THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Introduction
This tutorial covers running Nutch jobs on Apache Tez (instead of MapReduce).
This tutorial is a work in progress and the document should be considered in DRAFT status. The work to evaluate Tez as an appropriate execution engine for Nutch jobs was initiated in December, 2020.
Audience
This tutorial will appeal to Nutch administrators looking to improve runtime speed whilst maintaining MapReduce’s ability to scale to petabytes of data. Readers are encouraged to share their experienced using Nutch on Tez.
What is Apache Tez?
Apache Tez is described as an application framework which allows for a complex directed-acyclic-graph (DAG) of tasks for processing data. It is currently built atop Apache Hadoop YARN.
The 2 main design themes for Tez are:
- Empowering end users by:
- Expressive dataflow definition APIs
- Flexible Input-Processor-Output runtime model
- Data type agnostic
- Simplifying deployment
- Execution Performance
- Performance gains over Map Reduce
- Optimal resource management
- Plan reconfiguration at runtime
- Dynamic physical data flow decisions
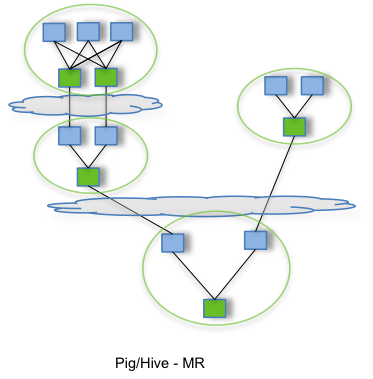
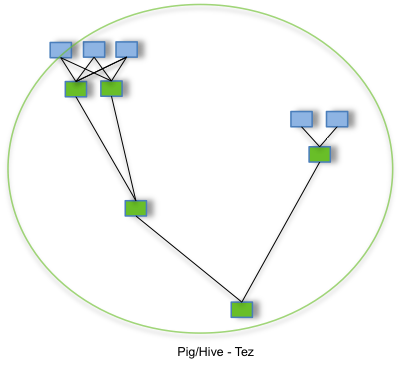
By allowing projects like Apache Hive and Apache Pig to run a complex DAG of tasks, Tez can be used to process data, that earlier took multiple MR jobs, now in a single Tez job as shown below.
Configuring and Deploying Hadoop Services
Configuring and Deploying Tez
Configuring and Deploying Nutch
Evaluating Tez as a Replacement for MapReduce
The following content relates to ongoing experiments which have been run by members of the Nutch community.