THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: Under Discussion
Discussion thread: here
JIRA:
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
MirrorMaker has been used for years in large-scale production environments, but not without several problems:
Topics are created with default configuration. Often they'll need to be repartitioned manually.
ACL and configuration changes are not synced across mirrored clusters, making it difficult to manage multiple clusters.
Records are repartitioned with DefaultPartitioner. Semantic partitioning may be lost.
Any configuration change means the cluster must be bounced. This includes adding new topics to the whitelist, which may be a frequent operation.
There's no mechanism to migrate producers or consumers between mirrored clusters.
There's no support for exactly-once delivery. Records may be duplicated during replication.
Clusters can't be made mirrors of each other, i.e. no support for active/active pairs.
For these reasons, MirrorMaker is insufficient for many use cases, including backup, disaster recovery, and fail-over scenarios. Several other Kafka replication tools have been created to address some of these limitations, but Apache Kafka has no adequate replication strategy to date. Moreover, the lack of a native solution makes it difficult to build generic tooling for multi-cluster environments.
I propose to replace MirrorMaker with a new multi-cluster, cross-data-center replication engine based on the Connect framework, MirrorMaker 2.0 (MM2). The new engine will be fundamentally different from the legacy MirrorMaker in many ways, but will provide a drop-in replacement for existing deployments.
Highlights of the design include:
Leverages the Kafka Connect framework and ecosystem.
Includes both source and sink connectors.
- Includes a high-level driver that manages connectors in a dedicated cluster.
- High-level REST API abstracts over connectors between multiple Kafka clusters.
Detects new topics, partitions.
Automatically syncs topic configuration between clusters.
Manages downstream topic ACL.
Supports "active/active" cluster pairs, as well as any number of active clusters.
Supports cross-datacenter replication, aggregation, and other complex topologies.
Provides new metrics including end-to-end replication latency across multiple data centers/clusters.
Emits offsets required to migrate consumers between clusters.
Tooling for offset translation.
MirrorMaker-compatible legacy mode.
Public Interfaces
New interfaces include:
MirrorSourceConnector, MirrorSinkConnector, MirrorSourceTask, MirrorSinkTask classes.
- MirrorCheckpointConnector, MirrorCheckpointTask.
- MirrorHeartbeatConnector, MirrorHeartbeatTask.
- MirrorConnectorConfig, MirrorTaskConfig classes.
ReplicationPolicy interface. DefaultReplicationPolicy and LegacyReplicationPolicy classes.
Heartbeat and checkpoint topics and associated schemas.
RemoteClusterUtils class for querying remote cluster reachability and lag, and for translating consumer offsets between clusters.
MirrorMaker driver class with main entry point for running MM2 cluster nodes.
- MirrorMakerConfig used by MirrorMaker driver.
- ./bin/connect-mirror-maker.sh and ./config/mirror-maker.properties sample configuration.
- MirrorMaker high-level REST API.
Proposed Changes
Remote Topics, Partitions
This design introduces the concept of remote topics, which are replicated topics referencing a source cluster via a naming convention, e.g. "us-west.topic1", where topic1 is a source topic and us-west is a source cluster alias. Any partitions in a remote topic are remote partitions and refer to the same partitions in the source topic. Specifically:
Partitioning and order of records is preserved between source and remote topics.
Remote topics must have the same number of partitions as their source topics.
A remote topic has a single source topic.
A remote partition has a single source partition.
Remote partition i is a replica of source partition i.
MM2 replicates topics from a source cluster to corresponding remote topics in the destination cluster. In this way, replication never results in merged or out-of-order partitions. Moreover, the topic renaming policy enables "active/active" replication by default:
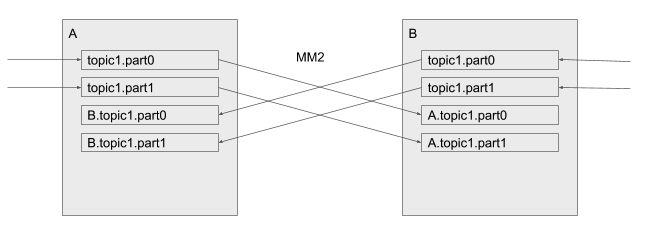
"active/active" replication
This is not possible with MirrorMaker today -- records would be replicated back and forth indefinitely, and the topics in either cluster would be merged inconsistently between clusters. The remote naming convention avoids these problems by keeping local and remote records in separate partitions. In either cluster above, the normal topic1 contains only locally produced records. Likewise, B.topic1 contains only records produced in cluster B.
To consume local records only, a consumer subscribes to topic1 as normal. To consume records that have been replicated from a remote cluster, consumers subscribe to a remote topic, e.g. B.topic1.
This convention extends to any number of clusters.
Aggregation
Downstream consumers can aggregate across multiple clusters by subscribing to the local topic and all corresponding remote topics, e.g. topic1, us-west.topic1, us-east.topic1… or by using a regex subscription.
Topics are never merged or repartitioned within the connector. Instead, merging is left to the consumer. This is in contrast to MirrorMaker, which is often used to merge topics from multiple clusters into a single aggregate cluster.
Likewise, a consumer can always elect not to aggregate by simply subscribing to the local topic only, e.g. topic1.
This approach eliminates the need for special purpose aggregation clusters without losing any power or flexibility.
Cycle detection
It is possible to configure two clusters to replicate each other ("active/active"), in which case all records produced to either cluster can be seen by consumers in both clusters. To prevent infinite recursion, topics that already contain "us-west" in the prefix won't be replicated to the us-west cluster.
This rule applies across all topics regardless of topology. A cluster can be replicated to many downstream clusters, which themselves can be replicated, yielding topics like us-west.us-east.topic1 and so on. The same cluster alias will not appear twice in a topic name due to cycle detection.
In this way, any topology of clusters is supported, not just DAGs.
Config, ACL Sync
MM2 monitors source topics and propagates configuration changes to remote topics. Any missing partitions will be automatically created.
Remote topics should never be written to, except by the source or sink connector. Producers must only write to local topics (e.g. topic1), which may then be replicated elsewhere. To enforce this policy, MM2 propagates ACL policies to downstream topics using the following rules:
Principals that can READ the source topic can READ the remote topic.
No one can WRITE to the remote topic except MM2.
Internal Topics
MM2 emits heartbeat topics like us-west.heartbeat, with time-stamped messages. Downstream consumers can use this topic to verify that a) the connector is running and b) the corresponding source cluster is available. Heartbeats will get propagated by source and sink connectors s.t. chains like backup.us-west.us-east.heartbeat are possible. Cycle detection prevents infinite recursion.
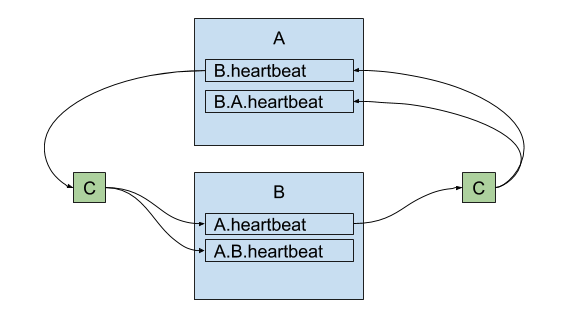
heartbeats are replicated between clusters
Additionally, the connectors periodically emit checkpoints in the destination cluster, containing offsets for each consumer group in the source cluster. The connector will periodically query the source cluster for all committed offsets from all consumer groups, filter for those topics being replicated, and emit a message to a topic like us-west.checkpoints.internal in the destination cluster. The message will include the following fields:
source cluster alias
consumer group ID
topic
partition
latest committed offset in source cluster
latest committed offset translated to destination cluster's offsets
- timestamp
As with __consumer_offsets, the checkpoint topic is log-compacted to reflect only the latest offsets across consumer groups. The topic will be created automatically by the connector if it doesn't exist.
Remote Cluster Utils
A utility class RemoteClusterUtils will leverage the internal topics described above to assist in computing reachability, inter-cluster lag, and offset translation. It won't be possible to directly translate any given offset, since not all offsets will be captured in the checkpoint stream. But for a given consumer group, it will be possible to find high water marks that consumers can seek() to. This is useful for inter-cluster consumer migration, failover, etc.
The interface is as follows (subject to change):
// Calculates the number of hops between a client and an upstream Kafka cluster based on replication heartbeats. // If the given cluster is not reachable, returns -1. int replicationHops(AdminClient client, String upstreamClusterAlias) // Find all heartbeat topics, e.g. A.B.heartbeat, visible from the client. List<String> heartbeatTopics(AdminClient client) // Find all checkpoint topics, e.g. A.checkpoint.internal, visible from the client. List<String> checkpointTopics(AdminClient client) // Find all upstream clusters reachable from the client List<String> upstreamClusters(AdminClient client) // Construct a consumer that is subscribed to all heartbeat topics. KafkaConsumer<Heartbeat> heartbeatConsumer(Map<?, ?> consumerConfig) // Construct a consumer that is subscribed to all checkpoint topics. KafkaConsumer<Checkpoint> checkpointConsumer(Map<?, ?> consumerConfig) // Construct a consumer that is subscribed to checkpoints from a specific upstream cluster. KafkaConsumer<Checkpoint> checkpointConsumer(Map<?, ?> consumerConfig, String sourceClusterAlias) // Construct a consumer that is subscribed to checkpoints from a specific upstream consumer group. KafkaConsumer<Checkpoint> checkpointConsumer(Map<?, ?> consumerConfig, String sourceClusterAlias, String remoteGroupId) // Find the local offsets corresponding to the latest checkpoint from a specific upstream consumer group. Map<TopicPartition, Long> translateOffsets(Map<?, ?> consumerConfig, String sourceClusterAlias, String remoteGroupId)
Replication Policies
ReplicationPolicy classes specify the behavior of MM2 at a high level, including which topics to replicate. The interface is as follows:
public interface ReplicationPolicy {
boolean shouldReplicateTopic(String topic);
boolean shouldCheckpointTopic(String topic);
boolean shouldReplicateConsumerGroup(String groupId);
boolean shouldSyncTopicConfiguration(String topic);
boolean shouldReplicatePrincipalACL(String principal);
boolean shouldSyncTopicACL(String topic);
String formatRemoteTopic(String topic); // e.g. us-west.topic1
}
The DefaultReplicationPolicy honors whitelists and blacklists for topics and consumer groups via regex patterns. LegacyReplicationPolicy causes MM2 to mimic legacy MirrorMaker behavior.
Connectors
Both source and sink connectors are provided to enable complex flows between multiple Kafka clusters and across data centers via existing Kafka Connect clusters. Generally, each data center has a single Connect cluster and a primary Kafka cluster, K.
MirrorSourceConnector workers replicate a set of topics from a single source cluster into the primary cluster.
MirrorSinkConnector workers consume from the primary cluster and replicate topics to a single sink cluster.
MirrorCheckpointConnector emits consumer offset checkpoints.
MirrorHeartbeatConnector emits heartbeats.
The source and sink connectors contain a pair of producers and consumers to replicate records, and a pair of AdminClients to propagate configuration/ACL changes.
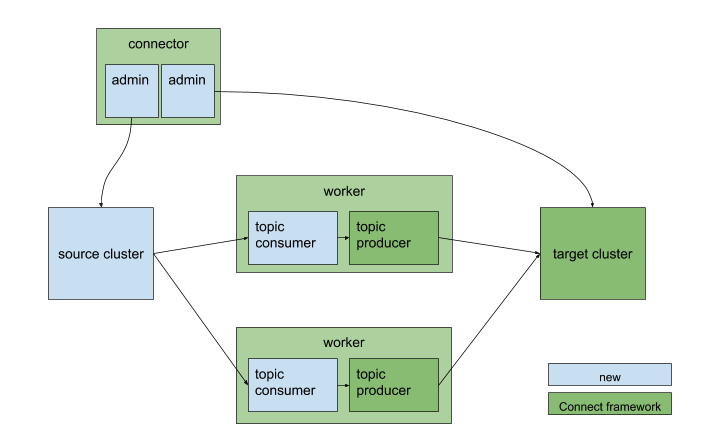
MirrorSourceConnector and workers
By combining SourceConnectors and SinkConnectors, a single Connect cluster can manage replication across multiple Kafka clusters.
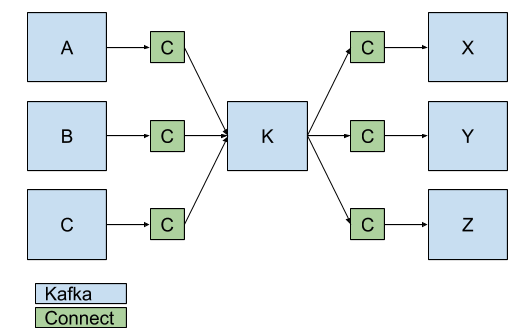
Connectors (C) replicate data between Kafka clusters.
For cross-datacenter replication (XDCR), each datacenter should have a single Connect cluster which pulls records from the other data centers via source connectors. Replication may fan-out within each datacenter via sink connectors.
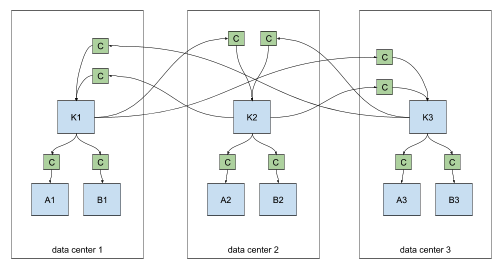
cross-datacenter replication of multiple clusters
Connectors can be configured to replicate specific topics via a whitelist or regex. For example, clusters A1 and B1 above might contain only a subset of topics from K1, K2, or K3.
Connector Configuration Properties
Properties common to the SourceConnector(s) and SinkConnector:
property | default value | description |
| name | required | name of the connector, e.g. "us-west->us-east" |
topics | empty string | regex of topics to replicate, e.g. "topic1|topic2|topic3" |
topics.blacklist | [".*\.internal", ".*\.replica", "__consumer_offsets", …] | topics to exclude from replication |
| groups | empty string | regex of groups to replicate, e.g. ".*" |
source.cluster.alias | required | name of the cluster being replicated |
| target.cluster.alias | required | name of the downstream Kafka cluster |
| source.cluster.bootstrap.servers | required | upstream cluster to replicate |
| target.cluster.bootstrap.servers | required | downstream cluster |
sync.topic.configs | true | whether or not to monitor source cluster for configuration changes |
| sync.topic.acls | true | whether to monitor source cluster ACLs for changes |
admin.* | n/a | passed to AdminClient for local cluster |
remote.admin.* | n/a | passed to remote AdminClient |
| rename.topics | true | connector should rename downstream topics according to "remote topic" convention |
emit.heartbeats | true | connector should periodically emit heartbeats |
| emit.heartbeats.interval.seconds | 5 (seconds) | frequency of heartbeats |
emit.checkpoints | true | connector should periodically emit consumer offset information |
| emit.checkpoints.interval.seconds | 5 (seconds) | frequency of checkpoints |
| refresh.topics | true | connector should periodically check for new topics |
| refresh.topics.interval.seconds | 5 (seconds) | frequency to check source cluster for new topics |
| refresh.groups | true | connector should periodically check for new consumer groups |
| refresh.groups.interval.seconds | 5 (seconds) | frequency to check source cluster for new consumer groups |
| readahead.queue.capacity | 500 (records) | number of records to let consumer get ahead of producer |
| replication.policy.class | org.apache.kafka.connect.mirror.DefaultReplicationPolicy | use LegacyReplicationPolicy to mimic legacy MirrorMaker |
The following are the SourceConnector's additional configuration properties.
property | default value | description |
consumer.* | n/a | passed to the consumer |
| consumer.poll.timeout.ms | 500 (ms) | poll timeout |
And similarly for the SinkConnector:
property | default value | description |
producer.* | n/a | passed to the producer |
These properties are specified in the MirrorConnectorConfig class, which is shared by all MirrorMaker connectors (MirrorSourceConnector, MirrorCheckpointConnector, etc). Some properties are relevant to specific Connectors, e.g. "emit.heartbeats" is only relevant to the MirrorHeartbeatConnector.
Example Configuration
A sample configuration file ./config/connect-mirror-source.properties is provided:
name = local-mirror-source topics = .* connector.class = org.apache.kafka.connect.mirror.MirrorSourceConnector tasks.max = 1 # for demo, source and target clusters are the same source.cluster.alias = upstream source.cluster.bootstrap.servers = localhost:9092 target.cluster.bootstrap.servers = localhost:9092 # use ByteArrayConverter to ensure that records are not re-encoded key.converter = org.apache.kafka.connect.converters.ByteArrayConverter value.converter = org.apache.kafka.connect.converters.ByteArrayConverter
This enables running standalone MM2 connectors as follows:
$ ./bin/connect-standalone.sh ./config/connect-standalone.properties ./config/connect-mirror-source.properties
Legacy MirrorMaker Configuration
By default, MM2 enables several features and best-practices that are not supported by legacy MirrorMaker; however, these can all be turned off. The following configuration demonstrates running MM2 in "legacy mode":
--%<---- # emulate legacy mirror-maker replication.policy.class = org.apache.kafka.mirror.LegacyReplicationPolicy # alternatively, can disable individual features rename.topics = false refresh.topics = false refresh.groups = false emit.checkpoints = false emit.heartbeats = false sync.topic.configs = false sync.topic.acls = false --%<----
MirrorMaker Clusters
The MirrorMaker.java driver class and ./bin/connect-mirror-maker.sh script implement a distributed MM2 cluster which does not depend on an existing Connect cluster. Instead, MM2 cluster nodes manage Connect workers internally based on a high-level configuration file and REST API. The configuration file is needed to identify each Kafka cluster. A sample MirrorMakerConfig properties file will be provided in ./config/mirror-maker.properties:
clusters = primary, backup cluster.primary.broker.list = localhost:9091 cluster.backup.broker.list = localhost:9092
This can be run as follows:
$ ./bin/connect-mirror-maker.sh ./config/mirror-maker.properties
Internally, the MirrorMaker driver sets up MirrorSourceConnectors, MirrorCheckpointConnectors, etc between each pair of clusters, based on the provided configuration file. For example, the above configuration results in two MirrorSourceConnectors: one replicating from primary→backup and one from backup→primary. The configuration for the primary→backup connector is automatically populated as follows:
name = MirrorSourceConnector connector.class = org.apache.kafka.connect.mirror.MirrorSourceConnector source.cluster.alias = primary target.cluster.alias = backup source.cluster.broker.list = localhost:9091 target.cluster.broker.list = localhost:9092 key.converter.class = org.apache.kafka.connect.converters.ByteArrayConverter value.converter.class = org.apache.kafka.connect.converters.ByteArrayConverter
Generally, a single connector of each type (MirrorSourceConnector, MirrorCheckpointConnector, MirrorHeartbeatConnector) is needed for each source→target flow, so the class name (e.g. MirrorSourceConnector) is used as the connector's "name".
At launch each such connector is configured to replicate no topics or groups (effectively idle), until these properties are configured via a REST API. Alternatively, the MirrorMaker properties file can specify static configuration properties for each connector to avoid using the REST API:
clusters = primary, backup cluster.primary.broker.list = localhost:9091 cluster.backup.broker.list = localhost:9092 connector.primary->backup.topics = .* connector.primary->backup.emit.heartbeats = false
In this case, two MirrorSourceConnectors, two MirrorCheckpointConnectors, and two MirrorHeartbeatConnectors will be created by the driver and the primary→backup connectors will start replicating all source topics at launch, with heartbeats disabled. Sub-configurations like connector.primary->backup.x.y.z will be applied to all connectors in that source→target flow (MirrorSourceConnector, MirrorHeartbeatConnector, etc), avoiding the need to configure each connector individually.
MirrorMaker Configuration Properties
The high-level configuration file required by the MirrorMaker driver supports the following properties:
property | default value | description |
clusters | required | comma-separated list of Kafka cluster "aliases" |
cluster.cluster.broker.list | required | connection information for the specific cluster |
| cluster.cluster.x.y.z | n/a | passed to workers for a specific cluster |
| connector.source->target.x.y.z | n/a | passed to a specific connector |
MirrorMaker REST API
To enable remote control of a dedicated MirrorMaker cluster, a high-level REST API is provided. The REST API includes a subset of the full Connect REST API, providing access to the underlying Connectors.
As with the Connect REST API, configurations can be updated via a PUT request:
PUT /from:us-west/to:us-east/connectors/MirrorSourceConnector/config HTTP/1.1
Host: localhost
Accept: application/json
{
"topics": ".*"
}
The following endpoints are supported:
- GET /clusters - list of cluster aliases
- GET /status - MirrorMaker status information
- GET /metrics - MirrorMaker metrics snapshot
- GET /cluster/cluster/status - status information for specific cluster
- GET /cluster/cluster/metrics - metrics snapshot for specific cluster
- GET /from:source/to:target/status - status information for specific replication flow
- GET /from:source/to:target/metrics - metrics snapshot for specific replication flow
- GET /from:source/to:target/connectors - list of connectors
- GET /from:source/to:target/connectors/connector/config - connector configuration
- PUT /from:source/to:target/connectors/connector/config - update connector configuration
- GET /from:source/to:target/connectors/connector/status - status information for a specific connector
- PUT /from:source/to:target/connectors/connector/restart - restart a specific connector
- PUT /from:source/to:target/connectors/connector/pause- pause a specific connector
- PUT /from:source/to:target/connectors/connector/resume - resume a specific connector
- DELETE /from:source/to:target/connectors/connector- delete a specific connector
Walkthrough: Running MirrorMaker 2.0
There are four ways to run MM2:
- As a dedicated MirrorMaker cluster.
- As a Connector in a distributed Connect cluster.
- As a standalone Connect worker.
- In legacy mode using existing MirrorMaker scripts.
Running a dedicated MirrorMaker cluster
In this mode, MirrorMaker does not require an existing Connect cluster. Instead, a high-level driver and API abstract over a collection of Connect workers.
First, specify Kafka cluster information in a configuration file:
# mm2.properties clusters = us-west, us-east cluster.us-west.brokers.list = host1:9092 cluster.us-east.brokers.list = host2:9092
Optionally, you can override default MirrorMaker properties:
topics = .* groups = .* emit.checkpoints.interval.seconds = 10
You can also override default properties for specific clusters or connectors:
cluster.us-west.offset.storage.topic = mm2-offsets connector.us-west->us-east.emit.heartbeats = false
Second, launch one or more MirrorMaker cluster nodes:
$ ./bin/connect-mirror-maker.sh mm2.properties
Finally, remote-control the MirrorMaker cluster using the REST API or CLI. The REST API provides a sub-set of the Connect REST API, including the ability to start, stop, and reconfigure connectors. For example:
PUT /from:us-west/to:us-east/connectors/MirrorSourceConnector/config
{
"topics": ".*"
}
Running a standalone MirrorMaker connector
In this mode, a single Connect worker runs MirrorSourceConnector. This does not support multinode clusters, but is useful for small workloads or for testing.
First, create a "worker" configuration file:
# worker.properties bootstrap.servers = host2:9092
An example is provided in ./config/connect-standalone.properties.
Second, create a "connector" configuration file:
# connector.properties name = local-mirror-source connector.class = org.apache.kafka.connect.mirror.MirrorSourceConnector tasks.max = 1 topics=.* source.cluster.alias = upstream source.cluster.bootstrap.servers = host1:9092 target.cluster.bootstrap.servers = host2:9092 # use ByteArrayConverter to ensure that in and out records are exactly the same key.converter = org.apache.kafka.connect.converters.ByteArrayConverter value.converter = org.apache.kafka.connect.converters.ByteArrayConverter
Finally, launch a single Connect worker:
$ ./bin/connecti-standalone.sh worker.properties connector.properties
Running MirrorMaker in a Connect cluster
If you already have a Connect cluster, you can configure it to run MirrorMaker connectors.
There are four such connectors:
- MirrorSourceConnector
- MirrorSinkConnector
- MirrorCheckpointConnector
- MirrorHeartbeatConnector
Configure these using the Connect REST API:
PUT /connectors/us-west-source/config HTTP/1.1
{
"name": "us-west-source",
"connector.class": "org.apache.kafka.connect.mirror.MirrorSourceConnector",
"source.cluster.alias": "us-west",
"target.cluster.alias": "us-east",
"source.cluster.brokers.list": "us-west-host1:9091",
"topics": ".*"
}
Running MirrorMaker in legacy mode
After legacy MirrorMaker is deprecated, the existing ./bin/kafka-mirror-maker.sh scripts will be updated to run MM2 in legacy mode:
$ ./bin/kafka-mirror-maker.sh --consumer consumer.properties --producer producer.properties
Compatibility, Deprecation, and Migration Plan
A new version of ./bin/kafka-mirror-maker.sh will be implemented to run MM2 in "legacy mode", i.e. with new features disabled and supporting existing options and configuration properties. Existing deployments will be able to upgrade to MM2 seamlessly.
The existing MirrorMaker source will be removed from Kafka core project. MM2 will be added to the connect project under a new module "mirror" and package "org.apache.kafka.connect.mirror".
Deprecation will occur in three phases:
- Phase 1 (targeting next Apache Kafka release): All MirrorMaker 2.0 Java code is added to ./connect/mirror/.
- Phase 2 (subsequent release): Legacy MirrorMaker Scala code is deprecated, but kept in place. Sample MM2 scripts and configuration files are added to ./bin/ and ./config/.
- Phase 3 (subsequent release): Legacy MirrorMaker Scala code is removed from Apache Kafka. A new ./bin/kafka-mirror-maker.sh script is provided which replaces and emulates the legacy script.
Rejected Alternatives
We could release this as an independent project, but we feel that cluster replication should be one of Kafka's fundamental features.
We could deprecate MirrorMaker but keep it around. However, we see this as a natural evolution of MirrorMaker, not an alternative solution.
We could update MirrorMaker rather than completely rewrite it. However, we'd end up recreating many features provided by the Connect framework, including the REST API, configuration, metrics, worker coordination, etc.
We could build on Uber's uReplicator, which solves some of the problems with MirrorMaker. However, uReplicator uses Apache Helix to provide features that overlap with Connect, e.g. REST API, live configuration changes, cluster management, coordination etc. A native MirrorMaker should only use native parts of Apache Kafka. That said, uReplicator is a major inspiration for the MM2 design.