THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: Under Discussion
Discussion thread: here
JIRA:
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Kafka typically uses zero-copy optimization for transferring data from the file system cache to the network socket when sending messages from brokers to consumers. This optimization works only when the consumer is able understands the on-disk message format.
An older consumer would expect an older message format than what is stored in the log. Broker needs to convert the messages to the appropriate older format that the consumer is able to understand (i.e. down-convert the messages). In such cases, the zero-copy optimization does not work as we need to read the messages from the file system cache into the JVM heap, transform the messages into the appropriate format, and then send them over the network socket. We could end up in situations where this down-conversion process causes Out Of Memory because we end up copying lot of data into the JVM heap.
Following are the goals of this KIP:
- Provide appropriate configuration parameters to manage maximum memory usage during down-conversion on the broker.
- Reduce overall footprint of the down-conversion process, both in terms of memory usage and the time for which the required memory is held.
As we cap the memory usage, we’d inadvertently affect the throughput and latency characteristics. Lesser the amount of memory available for down-conversion, fewer messages can batched together in a single reply to the consumer. As fewer messages can be batched together, the consumer would require more round-trips to consume the same number of messages. We need a design that minimizes any impact on throughput and latency characteristics.
Public Interfaces
Broker Configuration
A new broker configuration will be provided to block older clients from being able to fetch messages from the broker. This configuration provides an added measure to completely disable any down-conversions on the broker.
- Topic-level configuration:
minimum.consumer.fetch.version - Broker-level configuration:
log.minimum.consumer.fetch.version - Type: String
- Possible Values: "0.8.0", "0.8.1", "0.8.2", ..., "1.1" (see ApiVersion for an exhaustive list of possible values)
- Explanation: Sets the minimum
FetchRequestAPI version for consumer fetch requests. Broker sends anInvalidRequestExceptionin response to aFetchRequestfrom a client running an older version. - Default Value: "0.8.0", meaning the broker will honor all
FetchRequestversions.
The configuration accepts the broker version rather than the message format version to keep it consistent with other existing configurations like like message.format.version. Even though the configuration accepts all possible broker versions, the configuration takes effect only on certain versions where the message format actually changed. For example, setting minimum.consumer.fetch.version to "0.10.0" (which introduced message format 1) will block all clients requesting message format 0.
Proposed Changes
Message Chunking
We will introduce a message chunking approach to reduce overall memory consumption during down-conversion. The idea is to lazily and incrementally down-convert messages "chunks", and send the result out to the consumer as soon as the chunk is ready. The broker continuously down-converts chunks of messages and sends them out, until it has exhausted all messages contained in the FetchResponse, or has reached some predetermined threshold. This way, we use a small, fixed amount of memory per FetchResponse.
The diagram below shows what a FetchResponse looks like (excluding some metadata that is not relevant for this discussion). The red boxes correspond to the messages that need to be sent out for each partition. When down-conversion is not required, we simply hold an instance of FileRecords for each of these which contains pointers to the section of file we want to send out. When sending out the FetchResponse, we use zero-copy to transfer the actual data from the file to the underlying socket which means we never actually have to copy the data in userspace.
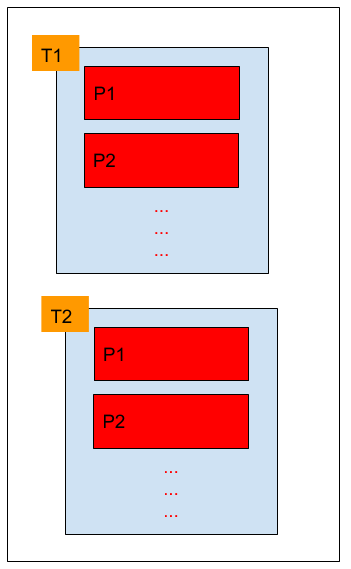
When down-conversion is required, each of the red boxes correspond to a MemoryRecords. Messages for each partition are read into JVM heap, converted to the appropriate format, and we hold on to this memory containing converted messages till the entire FetchResponse is created and subsequently sent out. There are couple of inefficiencies with this approach:
- The amount of memory we need to allocate is proportional to all the partition data in
FetchResponse. - The memory is kept referenced for an unpredictable amount of time -
FetchResponseis created in the I/O thread, queued up in theresponseQueuetill the network thread gets to it and is able to send the response out.
The idea with the chunking approach is to tackle both of these inefficiencies. We want to make the allocation predictable, both in terms of amount of memory allocated as well as the amount of time for which the memory is kept referenced. The diagram below shows what down-conversion would look like with the chunking approach. The consumer still sees a single FetchResponse which is actually being sent out in a "streaming" fashion from the broker.
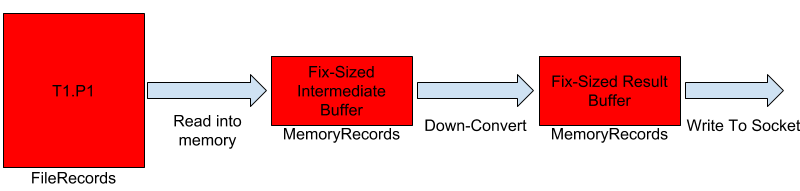
We have two fix-sized, preallocated buffers for each FetchResponse. The network thread does the following:
- Read a set of messages batches from the particular log segment into the intermediate buffer.
- Down-convert all the message batches that were read into the result buffer.
- Write the result buffer to the underlying socket.
- Repeat till we have sent out all the messages, or have reached some pre-determined threshold.
With this approach, we need to allocate a fixed amount of memory per response for the two fix-sized buffers. A subtle difference also is the fact that we have managed to delay the memory allocation and the actual process of down-conversion till the network thread is actually ready to send out the results. Specifically, we can perform down-conversion when Records.writeTo is called.
Although we have increased some amount of computation and I/O for reading log segments in the network thread, this is not expected to be very significant to cause any performance degradation. We will continue performing non-blocking socket writes in the network thread, to avoid having to stall the network thread waiting for socket I/O to complete.
Messages that require lazy down-conversion are encapsulated in a new class called LazyDownConvertedRecords. LazyDownConvertedRecords#writeTo will provide implementation for down-converting messages in chunks, and writing them to the underlying socket.
public class LazyDownConvertRecords implements Records {
/**
* Reference to records that will be "lazily" down-converted. Typically FileRecords.
*/
private final Records records;
/**
* Magic value to which above records need to be converted to.
*/
private final byte toMagic;
/**
* The starting offset of records.
*/
private final long firstOffset;
/**
* A "batch" of converted records.
*/
private ConvertedRecords<? extends Records> convertedRecords = null;
// Implementation for all methods in Records interface
}
Determining Total Response Size
Kafka response protocol requires the size of the entire response in the header. Generically, FetchResponse looks like the following:
FetchResponse => Size CorrelationId ResponseDataAndMetadata Size => Int32 CorrelationId => Int32 ResponseDataAndMetadata => Struct where Size = HeaderSize + MetadataSize + ∑(TopicPartitionDataSize)
HeaderSize and MetadataSize is always fixed in size, and can be pre-computed. TopicPartitionDataSize is a variable portion which depends on the size of the actual data being sent out. Because we delay down-conversion till Records.writeTo, we do not know the exact size of data that needs to be sent out.
To resolve this, we will use the pre-downconversion size (Spre) as an estimate for the post-downconversion size (Spost) for each topic-partition. We also commit to send out exactly Spre bytes for that particular partition. In terms of the above equation, the size will be computed as:
Size = HeaderSize + MetadataSize + ∑(Spre)
Given this, we have three possible scenarios:
- Spre = Spost: This is the ideal scenario where size of down-converted messages is exactly equal to the size before down-conversion. This requires no special handling.
- Spre < Spost: Because we committed to and cannot write more than Spre, we will not be able to send out all the messages to the consumer. We will down-convert and send all message batches that fit within Spre.
- Spre > Spost: Because we need to write exactly Spre, we append a "fake" message at the end with maximum message size (= Integer.MAX_VALUE). Consumer will treat this as a partial message batch and should thus ignore it.
Ensuring Consumer Progress
To ensure that consumer keeps making progress, Kafka makes sure that every response consists of at least one message for the first partition, even if it exceeds fetch.max.bytes and max.partition.fetch.bytes (KIP-74). When Spre < Spost (second case above), we cannot send out all the messages and need to trim message batch(es) towards the end. It is possible that we end up in a situation with a single partial batch in this case.
To prevent this from happening, we will not delay down-conversion of the first partition in the response. We will down-convert all messages of the first partition in the I/O thread (like we do today), and only delay down-conversion for subsequent partitions. This ensures that know the exact size of down-converted messages in the first partition beforehand, and can fully accomodate it in the response.
This can be done by accepting an additional parameter doLazyConversion in KafkaApis#handleFetchRequest#convertedPartitionData which returns FetchResponse.PartitionData containing either LazyDownConvertedRecords or MemoryRecords depending on whether we want to delay down-conversion or not.
Sizing Intermediate and Result Buffers
Initially, the intermediate and result buffer will be sized as small as possible, with possibility to grow if the allocation is not sufficient to hold a single message batch.
initialBufferSize = min(max.partition.fetch.bytes, message.max.bytes)
Pros
- Fixed and deterministic memory usage for each down-conversion response.
- Significantly reduced duration for which down-converted messages are kept referenced in JVM heap.
- No change required to existing clients.
Cons
- More computation being done in network threads.
- Additional file I/O being done in network threads.
- Complexity - expect this to be a big patch, but should be able to keep it abstracted into its own module so that it does not cause too much churn in existing code.
- Could be viewed as being somewhat "hacky" because of the need the need to pad "fake" messages at the end of the response.
Ability to Block Older Clients
Even though the chunking approach tries to minimize the impact on memory consumption when down-conversions need to be performed, the reality is that we cannot completely eliminate its impact on CPU and memory consumption. Some users might want an ability to completely block older clients, such that the broker is not burdened with having to perform down-conversions. We will add a broker-side configuration parameter to help specify the minimum compatible consumer that can fetch messages from a particular topic (see the "Public Interfaces" section for details).
Compatibility, Deprecation, and Migration Plan
There should be no visible impact after enabling the message chunking behavior described above. One thing that clients need to be careful about is the case where the total response size is greater than the size of the actual payload (described in Spre > Spost scenario of the chunking approach); client must ignore any message who size exceeds the size of the total response.
Rejected Alternatives
We considered several alternative design strategies but they were deemed to be either not being able to address the root cause by themselves, or being too complex to implement.
Alternate Chunked Approach
The "hacky"ness of the chunked approach discussed previously can be eliminated if we allowed the broker to break down a single logical FetchResponse into multiple FetchResponse messages. This means if we end up under-estimating the size of down-converted messages, we could send out two (or more) FetchResponse to the consumer. But we would require additional metadata so that the consumer knows that the multiple FetchResponse actually constitute a single logically continuous response. Because tagging the additional metadata requires changes to FetchResponse protocol, this will however not work for existing consumers.
We could consider this option as the eventual end-to-end solution for the down-conversion issue for future clients that require down-conversion.
Native Heap Memory
Kafka brokers are typically deployed with a much smaller JVM heap size compared to the amount of memory available, as large portions of memory need to be dedicated for the file system cache.
The primary problem with down-conversion today is that we need to process and copy large amounts of data into the JVM heap. One way of working around having to allocate large amount of memory in the JVM heap is by writing the down-converted messages into a native heap.
We can incrementally read messages from the log, down-convert them and write them out to native memory. When the entire FetchResponse has been down-converted, we can then put the response onto the network queue like we do today.
Pros
- Easy to implement.
Cons
- Need to devise effective way to reuse allocated native heap space (memory pooling).
- Tricky to design for cases where required memory is not immediately available.
- Could lead to consumer starvation if we wait too long for memory to become available, or if we never get the required amount of memory.
- Same amount of memory still consumed in aggregate, just not from the JVM heap. Memory will also not be freed till GC calls finalize.
- We need some estimate of how much memory to allocate before actually performing the down-conversion.
Configuration for Maximum Down-Conversion Memory Usage
Expose a broker-side configuration message.max.bytes.downconvert, which is the maximum amount of memory the broker can allocate to hold down-converted messages. This means that a message fetch that requires down-conversion would be able to fetch maximum of message.max.bytes.downconvert in a single fetch. If required memory is not available because it is already being consumed by other down-converted messages, we block the down-conversion process till sufficient memory becomes available.
The implementation for this could be based on the MemoryPool model, which essentially provides an interface to manage a fixed amount of memory. Each message that requires down-conversion requests for memory from the underlying MemoryPool and releases back to the pool once the message is sent out to the consumer.
Pros
- Likely straight-forward in terms of implementation.
- We have an upper-bound on how much memory can be consumed by down-conversion on the broker.
Cons
- Determining what message.max.bytes.downconvert should be set to could be a challenge, as setting it too low could affect latency, while setting it too high could cause memory pressure for other modules that share the JVM heap.
- Another knob for administrators to worry about!
- Need to devise effective way to reuse allocated native heap space (memory pooling).
- Tricky to design for cases where required memory is not immediately available.
Compression
To reduce the overall amount of memory consumed by down-converted messages, we could consider compressing them (if they are not already compressed to begin with).
Pros
- Reduced overall memory usage for down-converted messages.
Cons
- Choosing the correct compression format would require some experimentation.
- This by itself would not resolve the root cause because the compressed batch of messages might still end up causing OOM.