THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Table of Contents
- Table of Contents
- Introduction
- Quickstart
- Getting Started
- Architecture
- Enterprise Integration Patterns
- Cook Book
- Tutorials
- Language Appendix
- DataFormat Appendix
- Pattern Appendix
- Component Appendix
- Index
Introduction
Apache Camel ™ is a versatile open-source integration framework based on known Enterprise Integration Patterns.
Camel empowers you to define routing and mediation rules in a variety of domain-specific languages, including a Java-based Fluent API, Spring or Blueprint XML Configuration files, and a Scala DSL. This means you get smart completion of routing rules in your IDE, whether in a Java, Scala or XML editor.
Apache Camel uses URIs to work directly with any kind of Transport or messaging model such as HTTP, ActiveMQ, JMS, JBI, SCA, MINA or CXF, as well as pluggable Components and Data Format options. Apache Camel is a small library with minimal dependencies for easy embedding in any Java application. Apache Camel lets you work with the same API regardless which kind of Transport is used - so learn the API once and you can interact with all the Components provided out-of-box.
Apache Camel provides support for Bean Binding and seamless integration with popular frameworks such as CDI, Spring, Blueprint and Guice. Camel also has extensive support for unit testing your routes.
The following projects can leverage Apache Camel as a routing and mediation engine:
- Apache ServiceMix - a popular distributed open source ESB and JBI container
- Apache ActiveMQ - a mature, widely used open source message broker
- Apache CXF - a smart web services suite (JAX-WS and JAX-RS)
- Apache Karaf - a small OSGi based runtime in which applications can be deployed
- Apache MINA - a high-performance NIO-driven networking framework
So don't get the hump - try Camel today! ![]()
Too many buzzwords - what exactly is Camel?
Okay, so the description above is technology focused.
There's a great discussion about Camel at Stack Overflow. We suggest you view the post, read the comments, and browse the suggested links for more details.
Getting Started with Apache Camel
The Enterprise Integration Patterns (EIP) book
The purpose of a "patterns" book is not to advocate new techniques that the authors have invented, but rather to document existing best practices within a particular field. By doing this, the authors of a patterns book hope to spread knowledge of best practices and promote a vocabulary for discussing architectural designs.
One of the most famous patterns books is Design Patterns: Elements of Reusable Object-oriented Software by Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides, commonly known as the "Gang of Four" (GoF) book. Since the publication of Design Patterns, many other pattern books, of varying quality, have been written. One famous patterns book is called Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions by Gregor Hohpe and Bobby Woolf. It is common for people to refer to this book by its initials EIP. As the subtitle of EIP suggests, the book focuses on design patterns for asynchronous messaging systems. The book discusses 65 patterns. Each pattern is given a textual name and most are also given a graphical symbol, intended to be used in architectural diagrams.
The Camel project
Camel (http://camel.apache.org) is an open-source, Java-based project that helps the user implement many of the design patterns in the EIP book. Because Camel implements many of the design patterns in the EIP book, it would be a good idea for people who work with Camel to have the EIP book as a reference.
Online documentation for Camel
The documentation is all under the Documentation category on the right-side menu of the Camel website (also available in PDF form. Camel-related books are also available, in particular the Camel in Action book, presently serving as the Camel bible--it has a free Chapter One (pdf), which is highly recommended to read to get more familiar with Camel.
A useful tip for navigating the online documentation
The breadcrumbs at the top of the online Camel documentation can help you navigate between parent and child subsections.
For example, If you are on the "Languages" documentation page then the left-hand side of the reddish bar contains the following links.
Apache Camel > Documentation > Architecture > Languages
As you might expect, clicking on "Apache Camel" takes you back to the home page of the Apache Camel project, and clicking on "Documentation" takes you to the main documentation page. You can interpret the "Architecture" and "Languages" buttons as indicating you are in the "Languages" section of the "Architecture" chapter. Adding browser bookmarks to pages that you frequently reference can also save time.
Online Javadoc documentation
The Apache Camel website provides Javadoc documentation. It is important to note that the Javadoc documentation is spread over several independent Javadoc hierarchies rather than being all contained in a single Javadoc hierarchy. In particular, there is one Javadoc hierarchy for the core APIs of Camel, and a separate Javadoc hierarchy for each component technology supported by Camel. For example, if you will be using Camel with ActiveMQ and FTP then you need to look at the Javadoc hierarchies for the core API and Spring API.
Concepts and terminology fundamental to Camel
In this section some of the concepts and terminology that are fundamental to Camel are explained. This section is not meant as a complete Camel tutorial, but as a first step in that direction.
Endpoint
The term endpoint is often used when talking about inter-process communication. For example, in client-server communication, the client is one endpoint and the server is the other endpoint. Depending on the context, an endpoint might refer to an address, such as a host:port pair for TCP-based communication, or it might refer to a software entity that is contactable at that address. For example, if somebody uses "www.example.com:80" as an example of an endpoint, they might be referring to the actual port at that host name (that is, an address), or they might be referring to the web server (that is, software contactable at that address). Often, the distinction between the address and software contactable at that address is not an important one.
Some middleware technologies make it possible for several software entities to be contactable at the same physical address. For example, CORBA is an object-oriented, remote-procedure-call (RPC) middleware standard. If a CORBA server process contains several objects then a client can communicate with any of these objects at the same physical address (host:port), but a client communicates with a particular object via that object's logical address (called an IOR in CORBA terminology), which consists of the physical address (host:port) plus an id that uniquely identifies the object within its server process. (An IOR contains some additional information that is not relevant to this present discussion.) When talking about CORBA, some people may use the term "endpoint" to refer to a CORBA server's physical address, while other people may use the term to refer to the logical address of a single CORBA object, and other people still might use the term to refer to any of the following:
- The physical address (host:port) of the CORBA server process
- The logical address (host:port plus id) of a CORBA object.
- The CORBA server process (a relatively heavyweight software entity)
- A CORBA object (a lightweight software entity)
Because of this, you can see that the term endpoint is ambiguous in at least two ways. First, it is ambiguous because it might refer to an address or to a software entity contactable at that address. Second, it is ambiguous in the granularity of what it refers to: a heavyweight versus lightweight software entity, or physical address versus logical address. It is useful to understand that different people use the term endpoint in slightly different (and hence ambiguous) ways because Camel's usage of this term might be different to whatever meaning you had previously associated with the term.
Camel provides out-of-the-box support for endpoints implemented with many different communication technologies. Here are some examples of the Camel-supported endpoint technologies.
- A JMS queue.
- A web service.
- A file. A file may sound like an unlikely type of endpoint, until you realize that in some systems one application might write information to a file and, later, another application might read that file.
- An FTP server.
- An email address. A client can send a message to an email address, and a server can read an incoming message from a mail server.
- A POJO (plain old Java object).
In a Camel-based application, you create (Camel wrappers around) some endpoints and connect these endpoints with routes, which I will discuss later in Section 4.8 ("Routes, RouteBuilders and Java DSL"). Camel defines a Java interface called Endpoint. Each Camel-supported endpoint has a class that implements this Endpoint interface. As I discussed in Section 3.3 ("Online Javadoc documentation"), Camel provides a separate Javadoc hierarchy for each communications technology supported by Camel. Because of this, you will find documentation on, say, the JmsEndpoint class in the JMS Javadoc hierarchy, while documentation for, say, the FtpEndpoint class is in the FTP Javadoc hierarchy.
CamelContext
A CamelContext object represents the Camel runtime system. You typically have one CamelContext object in an application. A typical application executes the following steps.
- Create a
CamelContextobject. - Add endpoints – and possibly Components, which are discussed in Section 4.5 ("Components") – to the
CamelContextobject. - Add routes to the
CamelContextobject to connect the endpoints. - Invoke the
start()operation on theCamelContextobject. This starts Camel-internal threads that are used to process the sending, receiving and processing of messages in the endpoints. - Eventually invoke the
stop()operation on theCamelContextobject. Doing this gracefully stops all the endpoints and Camel-internal threads.
Note that the CamelContext.start() operation does not block indefinitely. Rather, it starts threads internal to each Component and Endpoint and then start() returns. Conversely, CamelContext.stop() waits for all the threads internal to each Endpoint and Component to terminate and then stop() returns.
If you neglect to call CamelContext.start() in your application then messages will not be processed because internal threads will not have been created.
If you neglect to call CamelContext.stop() before terminating your application then the application may terminate in an inconsistent state. If you neglect to call CamelContext.stop() in a JUnit test then the test may fail due to messages not having had a chance to be fully processed.
CamelTemplate
Camel used to have a class called CamelClient, but this was renamed to be CamelTemplate to be similar to a naming convention used in some other open-source projects, such as the TransactionTemplate and JmsTemplate classes in Spring.
The CamelTemplate class is a thin wrapper around the CamelContext class. It has methods that send a Message or Exchange – both discussed in Section 4.6 ("Message and Exchange")) – to an Endpoint – discussed in Section 4.1 ("Endpoint"). This provides a way to enter messages into source endpoints, so that the messages will move along routes – discussed in Section 4.8 ("Routes, RouteBuilders and Java DSL") – to destination endpoints.
The Meaning of URL, URI, URN and IRI
Some Camel methods take a parameter that is a URI string. Many people know that a URI is "something like a URL" but do not properly understand the relationship between URI and URL, or indeed its relationship with other acronyms such as IRI and URN.
Most people are familiar with URLs (uniform resource locators), such as "http://...", "ftp://...", "mailto:...". Put simply, a URL specifies the location of a resource.
A URI (uniform resource identifier) is a URL or a URN. So, to fully understand what URI means, you need to first understand what is a URN.
URN is an acronym for uniform resource name. There are may "unique identifier" schemes in the world, for example, ISBNs (globally unique for books), social security numbers (unique within a country), customer numbers (unique within a company's customers database) and telephone numbers. Each "unique identifier" scheme has its own notation. A URN is a wrapper for different "unique identifier" schemes. The syntax of a URN is "urn:<scheme-name>:<unique-identifier>". A URN uniquely identifies a resource, such as a book, person or piece of equipment. By itself, a URN does not specify the location of the resource. Instead, it is assumed that a registry provides a mapping from a resource's URN to its location. The URN specification does not state what form a registry takes, but it might be a database, a server application, a wall chart or anything else that is convenient. Some hypothetical examples of URNs are "urn:employee:08765245", "urn:customer:uk:3458:hul8" and "urn:foo:0000-0000-9E59-0000-5E-2". The <scheme-name> ("employee", "customer" and "foo" in these examples) part of a URN implicitly defines how to parse and interpret the <unique-identifier> that follows it. An arbitrary URN is meaningless unless: (1) you know the semantics implied by the <scheme-name>, and (2) you have access to the registry appropriate for the <scheme-name>. A registry does not have to be public or globally accessible. For example, "urn:employee:08765245" might be meaningful only within a specific company.
To date, URNs are not (yet) as popular as URLs. For this reason, URI is widely misused as a synonym for URL.
IRI is an acronym for internationalized resource identifier. An IRI is simply an internationalized version of a URI. In particular, a URI can contain letters and digits in the US-ASCII character set, while a IRI can contain those same letters and digits, and also European accented characters, Greek letters, Chinese ideograms and so on.
Components
Component is confusing terminology; EndpointFactory would have been more appropriate because a Component is a factory for creating Endpoint instances. For example, if a Camel-based application uses several JMS queues then the application will create one instance of the JmsComponent class (which implements the Component interface), and then the application invokes the createEndpoint() operation on this JmsComponent object several times. Each invocation of JmsComponent.createEndpoint() creates an instance of the JmsEndpoint class (which implements the Endpoint interface). Actually, application-level code does not invoke Component.createEndpoint() directly. Instead, application-level code normally invokes CamelContext.getEndpoint(); internally, the CamelContext object finds the desired Component object (as I will discuss shortly) and then invokes createEndpoint() on it.
Consider the following code.
myCamelContext.getEndpoint("pop3://john.smith@mailserv.example.com?password=myPassword");
The parameter to getEndpoint() is a URI. The URI prefix (that is, the part before ":") specifies the name of a component. Internally, the CamelContext object maintains a mapping from names of components to Component objects. For the URI given in the above example, the CamelContext object would probably map the pop3 prefix to an instance of the MailComponent class. Then the CamelContext object invokes createEndpoint("pop3://john.smith@mailserv.example.com?password=myPassword") on that MailComponent object. The createEndpoint() operation splits the URI into its component parts and uses these parts to create and configure an Endpoint object.
In the previous paragraph, I mentioned that a CamelContext object maintains a mapping from component names to Component objects. This raises the question of how this map is populated with named Component objects. There are two ways of populating the map. The first way is for application-level code to invoke CamelContext.addComponent(String componentName, Component component). The example below shows a single MailComponent object being registered in the map under 3 different names.
Component mailComponent = new org.apache.camel.component.mail.MailComponent();
myCamelContext.addComponent("pop3", mailComponent);
myCamelContext.addComponent("imap", mailComponent);
myCamelContext.addComponent("smtp", mailComponent);
The second (and preferred) way to populate the map of named Component objects in the CamelContext object is to let the CamelContext object perform lazy initialization. This approach relies on developers following a convention when they write a class that implements the Component interface. I illustrate the convention by an example. Let's assume you write a class called com.example.myproject.FooComponent and you want Camel to automatically recognize this by the name "foo". To do this, you have to write a properties file called "META-INF/services/org/apache/camel/component/foo" (without a ".properties" file extension) that has a single entry in it called class, the value of which is the fully-scoped name of your class. This is shown below.
META-INF/services/org/apache/camel/component/foo
class=com.example.myproject.FooComponent
If you want Camel to also recognize the class by the name "bar" then you write another properties file in the same directory called "bar" that has the same contents. Once you have written the properties file(s), you create a jar file that contains the com.example.myproject.FooComponent class and the properties file(s), and you add this jar file to your CLASSPATH. Then, when application-level code invokes createEndpoint("foo:...") on a CamelContext object, Camel will find the "foo"" properties file on the CLASSPATH, get the value of the class property from that properties file, and use reflection APIs to create an instance of the specified class.
As I said in Section 4.1 ("Endpoint"), Camel provides out-of-the-box support for numerous communication technologies. The out-of-the-box support consists of classes that implement the Component interface plus properties files that enable a CamelContext object to populate its map of named Component objects.
Earlier in this section I gave the following example of calling CamelContext.getEndpoint().
myCamelContext.getEndpoint("pop3://john.smith@mailserv.example.com?password=myPassword");
When I originally gave that example, I said that the parameter to getEndpoint() was a URI. I said that because the online Camel documentation and the Camel source code both claim the parameter is a URI. In reality, the parameter is restricted to being a URL. This is because when Camel extracts the component name from the parameter, it looks for the first ":", which is a simplistic algorithm. To understand why, recall from Section 4.4 ("The Meaning of URL, URI, URN and IRI") that a URI can be a URL or a URN. Now consider the following calls to getEndpoint.
myCamelContext.getEndpoint("pop3:...");
myCamelContext.getEndpoint("jms:...");
myCamelContext.getEndpoint("urn:foo:...");
myCamelContext.getEndpoint("urn:bar:...");
Camel identifies the components in the above example as "pop3", "jms", "urn" and "urn". It would be more useful if the latter components were identified as "urn:foo" and "urn:bar" or, alternatively, as "foo" and "bar" (that is, by skipping over the "urn:" prefix). So, in practice you must identify an endpoint with a URL (a string of the form "<scheme>:...") rather than with a URN (a string of the form "urn:<scheme>:..."). This lack of proper support for URNs means the you should consider the parameter to getEndpoint() as being a URL rather than (as claimed) a URI.
Message and Exchange
The Message interface provides an abstraction for a single message, such as a request, reply or exception message.
There are concrete classes that implement the Message interface for each Camel-supported communications technology. For example, the JmsMessage class provides a JMS-specific implementation of the Message interface. The public API of the Message interface provides get- and set-style methods to access the message id, body and individual header fields of a messge.
The Exchange interface provides an abstraction for an exchange of messages, that is, a request message and its corresponding reply or exception message. In Camel terminology, the request, reply and exception messages are called in, out and fault messages.
There are concrete classes that implement the Exchange interface for each Camel-supported communications technology. For example, the JmsExchange class provides a JMS-specific implementation of the Exchange interface. The public API of the Exchange interface is quite limited. This is intentional, and it is expected that each class that implements this interface will provide its own technology-specific operations.
Application-level programmers rarely access the Exchange interface (or classes that implement it) directly. However, many classes in Camel are generic types that are instantiated on (a class that implements) Exchange. Because of this, the Exchange interface appears a lot in the generic signatures of classes and methods.
Processor
The Processor interface represents a class that processes a message. The signature of this interface is shown below.
Processor
package org.apache.camel;
public interface Processor {
void process(Exchange exchange) throws Exception;
}
Notice that the parameter to the process() method is an Exchange rather than a Message. This provides flexibility. For example, an implementation of this method initially might call exchange.getIn() to get the input message and process it. If an error occurs during processing then the method can call exchange.setException().
An application-level developer might implement the Processor interface with a class that executes some business logic. However, there are many classes in the Camel library that implement the Processor interface in a way that provides support for a design pattern in the EIP book. For example, ChoiceProcessor implements the message router pattern, that is, it uses a cascading if-then-else statement to route a message from an input queue to one of several output queues. Another example is the FilterProcessor class which discards messages that do not satisfy a stated predicate (that is, condition).
Routes, RouteBuilders and Java DSL
A route is the step-by-step movement of a Message from an input queue, through arbitrary types of decision making (such as filters and routers) to a destination queue (if any). Camel provides two ways for an application developer to specify routes. One way is to specify route information in an XML file. A discussion of that approach is outside the scope of this document. The other way is through what Camel calls a Java DSL (domain-specific language).
Introduction to Java DSL
For many people, the term "domain-specific language" implies a compiler or interpreter that can process an input file containing keywords and syntax specific to a particular domain. This is not the approach taken by Camel. Camel documentation consistently uses the term "Java DSL" instead of "DSL", but this does not entirely avoid potential confusion. The Camel "Java DSL" is a class library that can be used in a way that looks almost like a DSL, except that it has a bit of Java syntactic baggage. You can see this in the example below. Comments afterwards explain some of the constructs used in the example.
Example of Camel's "Java DSL"
RouteBuilder builder = new RouteBuilder() {
public void configure() {
from("queue:a").filter(header("foo").isEqualTo("bar")).to("queue:b");
from("queue:c").choice()
.when(header("foo").isEqualTo("bar")).to("queue:d")
.when(header("foo").isEqualTo("cheese")).to("queue:e")
.otherwise().to("queue:f");
}
};
CamelContext myCamelContext = new DefaultCamelContext();
myCamelContext.addRoutes(builder);
The first line in the above example creates an object which is an instance of an anonymous subclass of RouteBuilder with the specified configure() method.
The CamelContext.addRoutes(RouterBuilder builder) method invokes builder.setContext(this) – so the RouteBuilder object knows which CamelContext object it is associated with – and then invokes builder.configure(). The body of configure() invokes methods such as from(), filter(), choice(), when(), isEqualTo(), otherwise() and to().
The RouteBuilder.from(String uri) method invokes getEndpoint(uri) on the CamelContext associated with the RouteBuilder object to get the specified Endpoint and then puts a FromBuilder "wrapper" around this Endpoint. The FromBuilder.filter(Predicate predicate) method creates a FilterProcessor object for the Predicate (that is, condition) object built from the header("foo").isEqualTo("bar") expression. In this way, these operations incrementally build up a Route object (with a RouteBuilder wrapper around it) and add it to the CamelContext object associated with the RouteBuilder.
Critique of Java DSL
The online Camel documentation compares Java DSL favourably against the alternative of configuring routes and endpoints in a XML-based Spring configuration file. In particular, Java DSL is less verbose than its XML counterpart. In addition, many integrated development environments (IDEs) provide an auto-completion feature in their editors. This auto-completion feature works with Java DSL, thereby making it easier for developers to write Java DSL.
However, there is another option that the Camel documentation neglects to consider: that of writing a parser that can process DSL stored in, say, an external file. Currently, Camel does not provide such a DSL parser, and I do not know if it is on the "to do" list of the Camel maintainers. I think that a DSL parser would offer a significant benefit over the current Java DSL. In particular, the DSL would have a syntactic definition that could be expressed in a relatively short BNF form. The effort required by a Camel user to learn how to use DSL by reading this BNF would almost certainly be significantly less than the effort currently required to study the API of the RouterBuilder classes.
Continue Learning about Camel
Return to the main Getting Started page for additional introductory reference information.
Architecture
Camel uses a Java based Routing Domain Specific Language (DSL) or an Xml Configuration to configure routing and mediation rules which are added to a CamelContext to implement the various Enterprise Integration Patterns.At a high level Camel consists of a CamelContext which contains a collection of Component instances. A Component is essentially a factory of Endpoint instances. You can explicitly configure Component instances in Java code or an IoC container like Spring or Guice, or they can be auto-discovered using URIs.
An Endpoint acts rather like a URI or URL in a web application or a Destination in a JMS system; you can communicate with an endpoint; either sending messages to it or consuming messages from it. You can then create a Producer or Consumer on an Endpoint to exchange messages with it.
The DSL makes heavy use of pluggable Languages to create an Expression or Predicate to make a truly powerful DSL which is extensible to the most suitable language depending on your needs. The following languages are supported
- Bean Language for using Java for expressions
- Constant
- the unified EL from JSP and JSF
- Header
- JSonPath
- JXPath
- Mvel
- OGNL
- Ref Language
- ExchangeProperty / Property
- Scripting Languages such as
- Simple
- Spring Expression Language
- SQL
- Tokenizer
- XPath
- XQuery
- VTD-XML
Most of these languages is also supported used as Annotation Based Expression Language.
For a full details of the individual languages see the Language Appendix
URIs
Camel makes extensive use of URIs to allow you to refer to endpoints which are lazily created by a Component if you refer to them within Routes.
important
Make sure to read How do I configure endpoints to learn more about configuring endpoints. For example how to refer to beans in the Registry or how to use raw values for password options, and using property placeholders etc.
Current Supported URIs
Component / ArtifactId / URI | Description |
|---|---|
AHC / ahc:http[s]://hostName[:port][/resourceUri][?options] | To call external HTTP services using Async Http Client |
AHC-WS / ahc-ws[s]://hostName[:port][/resourceUri][?options] | To exchange data with external Websocket servers using Async Http Client |
AMQP / amqp:[queue:|topic:]destinationName[?options] | For Messaging with AMQP protocol |
APNS / apns:<notify|consumer>[?options] | For sending notifications to Apple iOS devices |
Atmosphere-Websocket / atmosphere-websocket:///relative path[?options] | To exchange data with external Websocket clients using Atmosphere |
Atom / atom:atomUri[?options] | Working with Apache Abdera for atom integration, such as consuming an atom feed. |
Avro / avro:[transport]:[host]:[port][/messageName][?options] | Working with Apache Avro for data serialization. |
aws-cw://namespace[?options] | For working with Amazon's CloudWatch (CW). |
aws-ddb://tableName[?options] | For working with Amazon's DynamoDB (DDB). |
aws-ddbstream://tableName[?options] | For working with Amazon's DynamoDB Streams (DDB Streams). |
aws-ec2://label[?options] | For working with Amazon's Elastic Compute Cloud (EC2). |
aws-sdb://domainName[?options] | For working with Amazon's SimpleDB (SDB). |
aws-ses://from[?options] | For working with Amazon's Simple Email Service (SES). |
aws-sns://topicName[?options] | For Messaging with Amazon's Simple Notification Service (SNS). |
aws-sqs://queueName[?options] | For Messaging with Amazon's Simple Queue Service (SQS). |
aws-swf://<worfklow|activity>[?options] | For Messaging with Amazon's Simple Workflow Service (SWF). |
aws-s3://bucketName[?options] | For working with Amazon's Simple Storage Service (S3). |
Bean / bean:beanName[?options] | Uses the Bean Binding to bind message exchanges to beans in the Registry. Is also used for exposing and invoking POJO (Plain Old Java Objects). |
Beanstalk / beanstalk:hostname:port/tube[?options] | For working with Amazon's Beanstalk. |
Bean Validator / bean-validator:label[?options] | Validates the payload of a message using the Java Validation API (JSR 303 and JAXP Validation) and its reference implementation Hibernate Validator |
Box / box://endpoint-prefix/endpoint?[options] | For uploading, downloading and managing files, managing files, folders, groups, collaborations, etc. on Box.com. |
Braintree / braintree://endpoint-prefix/endpoint?[options] | Component for interacting with Braintree Payments via Braintree Java SDK |
Browse / browse:someName | Provides a simple BrowsableEndpoint which can be useful for testing, visualisation tools or debugging. The exchanges sent to the endpoint are all available to be browsed. |
Cache / cache://cacheName[?options] | The cache component facilitates creation of caching endpoints and processors using EHCache as the cache implementation. |
Cassandra / cql:localhost/keyspace | For integrating with Apache Cassandra. |
Class / class:className[?options] | Uses the Bean Binding to bind message exchanges to beans in the Registry. Is also used for exposing and invoking POJO (Plain Old Java Objects). |
Chronicle Engine / chronicle-engine:addresses/path[?options] | Chronicle Engine is a high performance, low latency, reactive processing framework. |
Chunk / chunk:templateName[?options] | Generates a response using a Chunk template |
CMIS / cmis://cmisServerUrl[?options] | Uses the Apache Chemistry client API to interface with CMIS supporting CMS |
Cometd / cometd://hostName:port/channelName[?options] | Used to deliver messages using the jetty cometd implementation of the bayeux protocol |
Consul / consul:apiEndpoint[?options] | For interfacing with an Consul. |
Context / context:camelContextId:localEndpointName[?options] | Used to refer to endpoints within a separate CamelContext to provide a simple black box composition approach so that routes can be combined into a CamelContext and then used as a black box component inside other routes in other CamelContexts |
ControlBus / controlbus:command[?options] | ControlBus EIP that allows to send messages to Endpoints for managing and monitoring your Camel applications. |
CouchDB / couchdb:hostName[:port]/database[?options] | To integrate with Apache CouchDB. |
Crypto (Digital Signatures) / crypto:<sign|verify>:name[?options] | Used to sign and verify exchanges using the Signature Service of the Java Cryptographic Extension. |
CXF / cxf:<bean:cxfEndpoint|//someAddress>[?options] | Working with Apache CXF for web services integration |
CXF Bean / cxfbean:serviceBeanRef[?options] | Proceess the exchange using a JAX WS or JAX RS annotated bean from the registry. Requires less configuration than the above CXF Component |
CXFRS / cxfrs:<bean:rsEndpoint|//address>[?options] | Working with Apache CXF for REST services integration |
DataFormat / dataformat:name:<marshal|unmarshal>[?options] | for working with Data Formats as if it was a regular Component supporting Endpoints and URIs. |
DataSet / dataset:name[?options] | For load & soak testing the DataSet provides a way to create huge numbers of messages for sending to Components or asserting that they are consumed correctly |
Direct / direct:someName[?options] | Synchronous call to another endpoint from same CamelContext. |
Direct-VM / direct-vm:someName[?options] | Synchronous call to another endpoint in another CamelContext running in the same JVM. |
DNS / dns:operation[?options] | To lookup domain information and run DNS queries using DNSJava |
Disruptor / disruptor:someName[?<option>] disruptor-vm:someName[?<option>] | To provide the implementation of SEDA which is based on disruptor |
Docker / docker://[operation]?[options] | To communicate with Docker |
Dozer / dozer://name?[options] | To convert message body using the Dozer type converter library. |
Dropbox / dropbox://[operation]?[options] | The dropbox: component allows you to treat Dropbox remote folders as a producer or consumer of messages. |
EJB / ejb:ejbName[?options] | Uses the Bean Binding to bind message exchanges to EJBs. It works like the Bean component but just for accessing EJBs. Supports EJB 3.0 onwards. |
Ehcache / ehcache://cacheName[?options] | The cache component facilitates creation of caching endpoints and processors using Ehcache 3 as the cache implementation. |
ElasticSearch / elasticsearch://clusterName[?options] | For interfacing with an ElasticSearch server. |
Etcd / etcd:namespace[/path][?options] | For interfacing with an Etcd key value store. |
Spring Event / spring-event://default | Working with Spring ApplicationEvents |
EventAdmin / eventadmin:topic[?options] | Receiving OSGi EventAdmin events |
Exec / exec://executable[?options] | For executing system commands |
Facebook / facebook://endpoint[?options] | Providing access to all of the Facebook APIs accessible using Facebook4J |
File / file://nameOfFileOrDirectory[?options] | Sending messages to a file or polling a file or directory. |
Flatpack / flatpack:[fixed|delim]:configFile[?options] | Processing fixed width or delimited files or messages using the FlatPack library |
Flink / flink:dataset[?options] flink:datastream[?options] | Bridges Camel connectors with Apache Flink tasks. |
FOP / fop:outputFormat[?options] | Renders the message into different output formats using Apache FOP |
FreeMarker / freemarker:templateName[?options] | Generates a response using a FreeMarker template |
FTP / ftp:contextPath[?options] | Sending and receiving files over FTP. |
FTPS / ftps://[username@]hostName[:port]/directoryName[?options] | Sending and receiving files over FTP Secure (TLS and SSL). |
Ganglia / ganglia:destination:port[?options] | Sends values as metrics to the Ganglia performance monitoring system using gmetric4j. Can be used along with JMXetric. |
gauth://name[?options] | Used by web applications to implement an OAuth consumer. See also Camel Components for Google App Engine. |
ghttp:contextPath[?options] | Provides connectivity to the URL fetch service of Google App Engine but can also be used to receive messages from servlets. See also Camel Components for Google App Engine. |
git:localRepositoryPath[?options] | Supports interaction with Git repositories |
github:endpoint[?options] | Supports interaction with Github |
glogin://hostname[:port][?options] | Used by Camel applications outside Google App Engine (GAE) for programmatic login to GAE applications. See also Camel Components for Google App Engine. |
gtask://queue-name[?options] | Supports asynchronous message processing on Google App Engine by using the task queueing service as message queue. See also Camel Components for Google App Engine. |
Google Calendar / camel-google-calendar google-calendar://endpoint-prefix/endpoint?[options] | Supports interaction with Google Calendar's REST API. |
Google Drive / camel-google-drive google-drive://endpoint-prefix/endpoint?[options] | Supports interaction with Google Drive's REST API. |
Google Mail / camel-google-mail google-mail://endpoint-prefix/endpoint?[options] | Supports interaction with Google Mail's REST API. |
gmail://user@g[oogle]mail.com[?options] | Supports sending of emails via the mail service of Google App Engine. See also Camel Components for Google App Engine. |
Gora / gora:instanceName[?options] | Supports to work with NoSQL databases using the Apache Gora framework. |
grape:defaultMavenCoordinates | Grape component allows you to fetch, load and manage additional jars when CamelContext is running. |
Geocoder / geocoder:<address|latlng:latitude,longitude>[?options] | Supports looking up geocoders for an address, or reverse lookup geocoders from an address. |
Google Guava EventBus / guava-eventbus:busName[?options] | The Google Guava EventBus allows publish-subscribe-style communication between components without requiring the components to explicitly register with one another (and thus be aware of each other). This component provides integration bridge between Camel and Google Guava EventBus infrastructure. |
hazelcast://[type]:cachename[?options] | Hazelcast is a data grid entirely implemented in Java (single jar). This component supports map, multimap, seda, queue, set, atomic number and simple cluster support. |
HBase / hbase://table[?options] | For reading/writing from/to an HBase store (Hadoop database) |
HDFS / hdfs://hostName[:port][/path][?options] | For reading/writing from/to an HDFS filesystem using Hadoop 1.x |
HDFS2 / hdfs2://hostName[:port][/path][?options] | For reading/writing from/to an HDFS filesystem using Hadoop 2.x |
Hipchat / hipchat://[host][:port]?options | For sending/receiving messages to Hipchat using v2 API |
HL7 / mina2:tcp://hostName[:port][?options] | For working with the HL7 MLLP protocol and the HL7 data format using the HAPI library |
Infinispan / infinispan://cacheName[?options] | For reading/writing from/to Infinispan distributed key/value store and data grid |
HTTP / http:hostName[:port][/resourceUri][?options] | For calling out to external HTTP servers using Apache HTTP Client 3.x |
HTTP4 / http4:hostName[:port][/resourceUri][?options] | For calling out to external HTTP servers using Apache HTTP Client 4.x |
iBATIS / ibatis://statementName[?options] | Performs a query, poll, insert, update or delete in a relational database using Apache iBATIS |
Ignite / ignite:[cache/compute/messaging/...][?options] | Apache Ignite In-Memory Data Fabric is a high-performance, integrated and distributed in-memory platform for computing and transacting on large-scale data sets in real-time, orders of magnitude faster than possible with traditional disk-based or flash technologies. It is designed to deliver uncompromised performance for a wide set of in-memory computing use cases from high performance computing, to the industry most advanced data grid, highly available service grid, and streaming. |
IMAP / imap://[username@]hostName[:port][?options] | Receiving email using IMAP |
IMAPS / imaps://[username@]hostName[:port][?options] | ... |
IRC / irc:[login@]hostName[:port]/#room[?options] | For IRC communication |
IronMQ / ironmq:queueName[?options] | For working with IronMQ a elastic and durable hosted message queue as a service. |
JavaSpace / javaspace:jini://hostName[?options] | Sending and receiving messages through JavaSpace |
jBPM / jbpm:hostName[:port][/resourceUri][?options] | Sending messages through kie-remote-client API to jBPM. |
jcache / jcache:cacheName[?options] | The JCache component facilitates creation of caching endpoints and processors using JCache / jsr107 as the cache implementation. |
jclouds / jclouds:<blobstore|compute>:[provider id][?options] | For interacting with cloud compute & blobstore service via jclouds |
JCR / jcr://user:password@repository/path/to/node[?options] | Storing a message in a JCR compliant repository like Apache Jackrabbit |
JDBC / jdbc:dataSourceName[?options] | For performing JDBC queries and operations |
Jetty / jetty:hostName[:port][/resourceUri][?options] | For exposing or consuming services over HTTP |
JGroups / jgroups:clusterName[?options] | The |
JIRA / jira://endpoint[?options] | For interacting with JIRA |
JMS / jms:[queue:|topic:]destinationName[?options] | Working with JMS providers |
JMX / jmx://platform[?options] | For working with JMX notification listeners |
JPA / jpa://entityName[?options] | For using a database as a queue via the JPA specification for working with OpenJPA, Hibernate or TopLink |
JOLT / jolt:specName[?options] | The jolt: component allows you to process a JSON messages using an JOLT specification. This can be ideal when doing JSON to JSON transformation. |
Jsch / scp://hostName[:port]/destination[?options] | Support for the scp protocol |
JT/400 / jt400://user:pwd@system/<path_to_dtaq>[?options] | For integrating with data queues on an AS/400 (aka System i, IBM i, i5, ...) system |
Kafka / kafka://server:port[?options] | For producing to or consuming from Apache Kafka message brokers. |
Kestrel / kestrel://[addresslist/]queueName[?options] | For producing to or consuming from Kestrel queues |
Krati / krati://[path to datastore/][?options] | For producing to or consuming to Krati datastores |
Kubernetes / kubernetes:masterUrl[?options] | For integrating your application with Kubernetes standalone or on top of OpenShift. |
Kura /
| For deploying Camel OSGi routes into the Eclipse Kura M2M container. |
Language / language://languageName[:script][?options] | Executes Languages scripts |
LDAP / ldap:host[:port][?options] | Performing searches on LDAP servers (<scope> must be one of object|onelevel|subtree) |
LinkedIn / linkedin://endpoint-prefix/endpoint?[options] | Component for retrieving LinkedIn user profiles, connections, companies, groups, posts, etc. using LinkedIn REST API. |
Log / log:loggingCategory[?options] | Uses Jakarta Commons Logging to log the message exchange to some underlying logging system like log4j |
Lucene / lucene:searcherName:<insert|query>[?options] | Uses Apache Lucene to perform Java-based indexing and full text based searches using advanced analysis/tokenization capabilities |
Lumberjack / lumberjack:host[:port] | Uses the Lumberjack protocol for retrieving logs (from Filebeat for instance) |
Metrics / metrics:[meter|counter|histogram|timer]:metricname[?options] | Uses Metrics to collect application statistics directly from Camel routes. |
MINA / mina:[tcp|udp|vm]:host[:port][?options] | Working with Apache MINA 1.x |
MINA2 / mina2:[tcp|udp|vm]:host[:port][?options] | Working with Apache MINA 2.x |
Mock / mock:name[?options] | For testing routes and mediation rules using mocks |
MLLP / mllp:host:port[?options] | The MLLP component is specifically designed to handle the nuances of the MLLP protocol and provide the functionality required by Healthcare providers to communicate with other systems using the MLLP protocol |
MongoDB / mongodb:connectionBean[?options] | Interacts with MongoDB databases and collections. Offers producer endpoints to perform CRUD-style operations and more against databases and collections, as well as consumer endpoints to listen on collections and dispatch objects to Camel routes |
MongoDB GridFS / mongodb-gridfs:dbName[?options] | Sending and receiving files via MongoDB's GridFS system. Note: for Camel < 2.19, the URI syntax is gridfs:dbName[?options] |
MQTT / mqtt:name[?options] | Component for communicating with MQTT M2M message brokers |
MSV / msv:someLocalOrRemoteResource[?options] | Validates the payload of a message using the MSV Library |
Mustache / mustache:templateName[?options] | Generates a response using a Mustache template |
MVEL / mvel:templateName[?options] | Generates a response using an MVEL template |
MyBatis / mybatis://statementName[?options] | Performs a query, poll, insert, update or delete in a relational database using MyBatis |
Nagios / nagios://hostName[:port][?options] | |
NATS / nats://servers[?options] | For messaging with the NATS platform. |
Netty / netty:<tcp|udp>//host[:port][?options] | Working with TCP and UDP protocols using Java NIO based capabilities offered by the Netty project |
Netty4 / netty4:<tcp|udp>//host[:port][?options] | Working with TCP and UDP protocols using Java NIO based capabilities offered by the Netty project |
Netty HTTP / netty-http:http:[port]/context-path[?options] | Netty HTTP server and client using the Netty project |
Netty4 HTTP / netty4-http:http:[port]/context-path[?options] | Netty HTTP server and client using the Netty project 4.x |
Olingo2 / olingo2:endpoint/resource-path[?options] | Communicates with OData 2.0 services using Apache Olingo 2.0. |
Openshift / openshift:clientId[?options] | To manage your Openshift applications. |
OptaPlanner / optaplanner:solverConfig[?options] | Solves the planning problem contained in a message with OptaPlanner. |
Paho / paho:topic[?options] | Paho component provides connector for the MQTT messaging protocol using the Paho library. |
Pax-Logging / paxlogging:appender | Receiving Pax-Logging events in OSGi |
PDF / pdf:operation[?options] | Allows to work with Apache PDFBox PDF documents |
PGEvent / pgevent:dataSource[?options] | Allows for Producing/Consuming PostgreSQL events related to the LISTEN/NOTIFY commands added since PostgreSQL 8.3 |
POP3 / pop3s://[username@]hostName port][?options] | Receiving email using POP3 and JavaMail |
POP3S / pop3s://[username@]hostName port][?options] | ... |
Printer / lpr://host:port/path/to/printer[?options] | The printer component facilitates creation of printer endpoints to local, remote and wireless printers. The endpoints provide the ability to print camel directed payloads when utilized on camel routes. |
Properties / properties://key[?options] | The properties component facilitates using property placeholders directly in endpoint URI definitions. |
Quartz / quartz://groupName/timerName[?options] | Provides a scheduled delivery of messages using the Quartz 1.x scheduler |
Quartz2 / quartz2://groupName/timerName[?options] | Provides a scheduled delivery of messages using the Quartz 2.x scheduler |
Quickfix / quickfix:configFile[?options] | Implementation of the QuickFix for Java engine which allow to send/receive FIX messages |
RabbitMQ / rabbitmq://hostname[:port]/exchangeName[?options] | Component for integrating with RabbitMQ |
Ref / ref:name | Component for lookup of existing endpoints bound in the Registry. |
Rest / rest:verb:path[?options] | Component for consuming Restful resources supporting the Rest DSL and plugins to other Camel rest components. |
Restlet / restlet:restletUrl[?options] | Component for consuming and producing Restful resources using Restlet |
REST Swagger / camel-rest-swagger rest-swagger:[specificationUri#]operationId[?options] | Component for accessing REST resources using Swagger specification as configuration. |
RMI / rmi://hostName[:port][?options] | Working with RMI |
RNC / rnc:/relativeOrAbsoluteUri[?options] | Validates the payload of a message using RelaxNG Compact Syntax |
RNG / rng:/relativeOrAbsoluteUri[?options] | Validates the payload of a message using RelaxNG |
Routebox / routebox:routeBoxName[?options] | Facilitates the creation of specialized endpoints that offer encapsulation and a strategy/map based indirection service to a collection of camel routes hosted in an automatically created or user injected camel context |
RSS / rss:uri[?options] | Working with ROME for RSS integration, such as consuming an RSS feed. |
Salesforce / salesforce:topic[?options] | To integrate with Salesforce |
SAP NetWeaver / sap-netweaver:hostName[:port][?options] | To integrate with SAP NetWeaver Gateway |
Scheduler / scheduler://name?[options] | Used to generate message exchanges when a scheduler fires. The scheduler has more functionality than the timer component. |
schematron / schematron://path?[options] | Camel component of Schematron which supports to validate the XML instance documents. |
SEDA / seda:someName[?options] | Asynchronous call to another endpoint in the same CamelContext |
ServiceNow / servicenow:instanceName[?options] | Camel component for ServiceNow |
SERVLET / servlet:relativePath[?options] | For exposing services over HTTP through the servlet which is deployed into the Web container. |
SFTP / sftp://[username@]hostName[:port]/directoryName[?options] | Sending and receiving files over SFTP (FTP over SSH). |
Sip / sip://user@hostName[:port][?options] | Publish/Subscribe communication capability using the Telecom SIP protocol. RFC3903 - Session Initiation Protocol (SIP) Extension for Event |
SIPS / sips://user@hostName[:port][?options] | ... |
SJMS / sjms:[queue:|topic:]destinationName[?options] | A ground up implementation of a JMS client |
SJMS Batch / sjms-batch:[queue:]destinationName[?options] | A specialized JMS component for highly-performant transactional batch consumption from a queue. |
Slack / slack:#channel[?options] | The slack component allows you to connect to an instance of Slack and delivers a message contained in the message body via a pre established Slack incoming webhook . |
SMTP / smtps://[username@]hostName[:port][?options] | Sending email using SMTP and JavaMail |
SMTP / smtps://[username@]hostName[:port][?options] | ... |
SMPP / smpp://[username@]hostName[:port][?options] | To send and receive SMS using Short Messaging Service Center using the JSMPP library |
SMPPS / smpps://[username@]hostName[:port][?options] | ... |
SNMP / snmp://hostName[:port][?options] | Polling OID values and receiving traps using SNMP via SNMP4J library |
Solr / solr://hostName[:port]/solr[?options] | Uses the Solrj client API to interface with an Apache Lucene Solr server |
Apache Spark / spark:{rdd|dataframe|hive}[?options]
| Bridges Apache Spark computations with Camel endpoints. |
Spark-rest / spark-rest://verb:path[?options] | For easily defining REST services endpoints using Spark REST Java library. |
Splunk / splunk://[endpoint][?options] | For working with Splunk |
SpringBatch / spring-batch://jobName[?options] | To bridge Camel and Spring Batch |
SpringIntegration / spring-integration:defaultChannelName[?options] | The bridge component of Camel and Spring Integration |
Spring LDAP / spring-ldap:springLdapTemplateBean[?options] | Camel wrapper for Spring LDAP |
Spring Redis / spring-redis://hostName:port[?options] | Component for consuming and producing from Redis key-value store Redis |
Spring Web Services / spring-ws:[mapping-type:]address[?options] | Client-side support for accessing web services, and server-side support for creating your own contract-first web services using Spring Web Services |
SQL / sql:select * from table where id=#[?options] | Performing SQL queries using JDBC |
SQL Stored Procedure / sql-stored:template[?options] | Performing SQL queries using Stored Procedure calls |
SSH component / ssh:[username[:password]@]hostName[:port][?options] | For sending commands to a SSH server |
StAX / stax:(contentHandlerClassName|#myHandler) | Process messages through a SAX ContentHandler. |
Stream / stream:[in|out|err|file|header|url][?options] | Read or write to an input/output/error/file stream rather like unix pipes |
Stomp / stomp:queue:destinationName[?options] | For communicating with Stomp compliant message brokers, like Apache ActiveMQ or ActiveMQ Apollo |
StringTemplate / string-template:templateName[?options] | Generates a response using a String Template |
Stub / stub:someOtherCamelUri[?options] | Allows you to stub out some physical middleware endpoint for easier testing or debugging |
Telegram / telegram://bots/authToken[?options] | Allows to exchange data with the Telegram messaging network |
Test / test:expectedMessagesEndpointUri[?options] | Creates a Mock endpoint which expects to receive all the message bodies that could be polled from the given underlying endpoint |
Timer / timer:timerName[?options] | Used to generate message exchanges when a timer fires You can only consume events from this endpoint. |
Twitter / twitter://endpoint[?options] | A twitter endpoint |
Undertow / undertow://host:port/context-path[?options] | HTTP server and client using the light-weight Undertow server. |
Validation / validation:someLocalOrRemoteResource[?options] | Validates the payload of a message using XML Schema and JAXP Validation |
Velocity / velocity:templateName[?options] | Generates a response using an Apache Velocity template |
Vertx / vertx:eventBusName | Working with the vertx event bus |
VM / vm:queueName[?options] | Asynchronous call to another endpoint in the same JVM |
Weather / wweather://name[?options] | Polls the weather information from Open Weather Map |
Websocket / websocket://hostname[:port][/resourceUri][?options] | Communicating with Websocket clients |
XML Security / xmlsecurity:<sign|verify>:name[?options] | Used to sign and verify exchanges using the XML signature specification. |
XMPP / xmpp://[login@]hostname[:port][/participant][?options] | Working with XMPP and Jabber |
XQuery / xquery:someXQueryResource | Generates a response using an XQuery template |
XSLT / xslt:templateName[?options] | Generates a response using an XSLT template |
Yammer / yammer://function[?options] | Allows you to interact with the Yammer enterprise social network |
Zookeeper / zookeeper://zookeeperServer[:port][/path][?options] | Working with ZooKeeper cluster(s) |
URI's for external components
Other projects and companies have also created Camel components to integrate additional functionality into Camel. These components may be provided under licenses that are not compatible with the Apache License, use libraries that are not compatible, etc... These components are not supported by the Camel team, but we provide links here to help users find the additional functionality.
For a full details of the individual components see the Component Appendix
Enterprise Integration Patterns
Camel supports most of the Enterprise Integration Patterns from the excellent book of the same name by Gregor Hohpe and Bobby Woolf. Its a highly recommended book, particularly for users of Camel.
Pattern Index
There now follows a list of the Enterprise Integration Patterns from the book along with examples of the various patterns using Apache Camel
Messaging Systems
| How does one application communicate with another using messaging? | |
| How can two applications connected by a message channel exchange a piece of information? | |
| How can we perform complex processing on a message while maintaining independence and flexibility? | |
| How can you decouple individual processing steps so that messages can be passed to different filters depending on a set of conditions? | |
| How can systems using different data formats communicate with each other using messaging? | |
| How does an application connect to a messaging channel to send and receive messages? |

Messaging Channels
| How can the caller be sure that exactly one receiver will receive the document or perform the call? | |
| How can the sender broadcast an event to all interested receivers? | |
| What will the messaging system do with a message it cannot deliver? | |
| How can the sender make sure that a message will be delivered, even if the messaging system fails? | |
| What is an architecture that enables separate applications to work together, but in a de-coupled fashion such that applications can be easily added or removed without affecting the others? |





Message Construction
| How can messaging be used to transmit events from one application to another? | |
| When an application sends a message, how can it get a response from the receiver? | |
| How does a requestor that has received a reply know which request this is the reply for? | |
| How does a replier know where to send the reply? |

Message Routing
| How do we handle a situation where the implementation of a single logical function (e.g., inventory check) is spread across multiple physical systems? | |
| How can a component avoid receiving uninteresting messages? | |
| How can you avoid the dependency of the router on all possible destinations while maintaining its efficiency? | |
| How do we route a message to a list of (static or dynamically) specified recipients? | |
| How can we process a message if it contains multiple elements, each of which may have to be processed in a different way? | |
| How do we combine the results of individual, but related messages so that they can be processed as a whole? | |
| How can we get a stream of related but out-of-sequence messages back into the correct order? | |
| How can you maintain the overall message flow when processing a message consisting of multiple elements, each of which may require different processing? | |
| How do you maintain the overall message flow when a message needs to be sent to multiple recipients, each of which may send a reply? | |
| How do we route a message consecutively through a series of processing steps when the sequence of steps is not known at design-time and may vary for each message? | |
| How can I throttle messages to ensure that a specific endpoint does not get overloaded, or we don't exceed an agreed SLA with some external service? | |
| How can I sample one message out of many in a given period to avoid downstream route does not get overloaded? | |
| How can I delay the sending of a message? | |
| How can I balance load across a number of endpoints? | |
To use Hystrix Circuit Breaker when calling an external service. | ||
To call a remote service in a distributed system where the service is looked up from a service registry of some sorts. | ||
| How can I route a message to a number of endpoints at the same time? | |
| How can I repeat processing a message in a loop? |

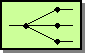
Message Transformation
| How do we communicate with another system if the message originator does not have all the required data items available? | |
| How do you simplify dealing with a large message, when you are interested only in a few data items? | |
| How can we reduce the data volume of message sent across the system without sacrificing information content? | |
| How do you process messages that are semantically equivalent, but arrive in a different format? | |
| How can I sort the body of a message? | |
Script | How do I execute a script which may not change the message? | |
| How can I validate a message? |
Messaging Endpoints
| How do you move data between domain objects and the messaging infrastructure while keeping the two independent of each other? | |
| How can an application automatically consume messages as they become available? | |
| How can an application consume a message when the application is ready? | |
| How can a messaging client process multiple messages concurrently? | |
| How can multiple consumers on a single channel coordinate their message processing? | |
| How can a message consumer select which messages it wishes to receive? | |
| How can a subscriber avoid missing messages while it's not listening for them? | |
| How can a message receiver deal with duplicate messages? | |
| How can a client control its transactions with the messaging system? | |
| How do you encapsulate access to the messaging system from the rest of the application? | |
| How can an application design a service to be invoked both via various messaging technologies and via non-messaging techniques? |


System Management
| How can we effectively administer a messaging system that is distributed across multiple platforms and a wide geographic area? | |
| How can you route a message through intermediate steps to perform validation, testing or debugging functions? | |
| How do you inspect messages that travel on a point-to-point channel? | |
| How can we effectively analyze and debug the flow of messages in a loosely coupled system? | |
| How can I log processing a message? |

For a full breakdown of each pattern see the Book Pattern Appendix
Pattern Appendix
There now follows a breakdown of the various Enterprise Integration Patterns that Camel supports
Messaging Systems
Message Channel
Camel supports the Message Channel from the EIP patterns. The Message Channel is an internal implementation detail of the Endpoint interface and all interactions with the Message Channel are via the Endpoint interfaces.
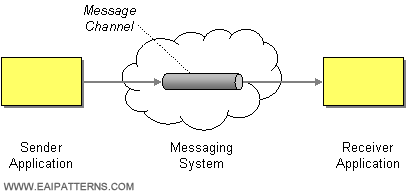
Example
In JMS, Message Channels are represented by topics and queues such as the following
jms:queue:foo
This message channel can be then used within the JMS component
Using the Fluent Builders
to("jms:queue:foo")
Using the Spring XML Extensions
<to uri="jms:queue:foo"/>
For more details see
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Message
Camel supports the Message from the EIP patterns using the Message interface.
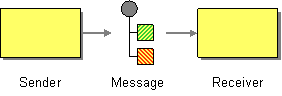
To support various message exchange patterns like one way Event Message and Request Reply messages Camel uses an Exchange interface which has a pattern property which can be set to InOnly for an Event Message which has a single inbound Message, or InOut for a Request Reply where there is an inbound and outbound message.
Here is a basic example of sending a Message to a route in InOnly and InOut modes
Requestor Code
//InOnly
getContext().createProducerTemplate().sendBody("direct:startInOnly", "Hello World");
//InOut
String result = (String) getContext().createProducerTemplate().requestBody("direct:startInOut", "Hello World");
Route Using the Fluent Builders
from("direct:startInOnly").inOnly("bean:process");
from("direct:startInOut").inOut("bean:process");
Route Using the Spring XML Extensions
<route> <from uri="direct:startInOnly"/> <inOnly uri="bean:process"/> </route> <route> <from uri="direct:startInOut"/> <inOut uri="bean:process"/> </route>
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Pipes and Filters
Camel supports the Pipes and Filters from the EIP patterns in various ways.

With Camel you can split your processing across multiple independent Endpoint instances which can then be chained together.
Using Routing Logic
You can create pipelines of logic using multiple Endpoint or Message Translator instances as follows
In Spring XML you can use the <pipeline/> element
In the above the pipeline element is actually unnecessary, you could use this:
which is a bit more explicit.
However if you wish to use <multicast/> to avoid a pipeline - to send the same message into multiple pipelines - then the <pipeline/> element comes into its own:
In the above example we are routing from a single Endpoint to a list of different endpoints specified using URIs. If you find the above a bit confusing, try reading about the Architecture or try the Examples
Message Router
The Message Router from the EIP patterns allows you to consume from an input destination, evaluate some predicate then choose the right output destination.
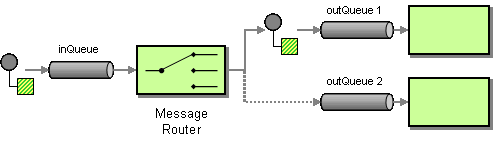
The following example shows how to route a request from an input queue:a endpoint to either queue:b, queue:c or queue:d depending on the evaluation of various Predicate expressions
Using the Fluent Builders
Error formatting macro: snippet: java.lang.NullPointerException
Using the Spring XML Extensions
Error formatting macro: snippet: java.lang.NullPointerException
Choice without otherwise
If you use a choice without adding an otherwise, any unmatched exchanges will be dropped by default.
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Message Translator
Camel supports the Message Translator from the EIP patterns by using an arbitrary Processor in the routing logic, by using a bean to perform the transformation, or by using transform() in the DSL. You can also use a Data Format to marshal and unmarshal messages in different encodings.
![]()
Using the Fluent Builders
You can transform a message using Camel's Bean Integration to call any method on a bean in your Registry such as your Spring XML configuration file as follows
Where the "myTransformerBean" would be defined in a Spring XML file or defined in JNDI etc. You can omit the method name parameter from beanRef() and the Bean Integration will try to deduce the method to invoke from the message exchange.
or you can add your own explicit Processor to do the transformation
or you can use the DSL to explicitly configure the transformation
Use Spring XML
You can also use Spring XML Extensions to do a transformation. Basically any Expression language can be substituted inside the transform element as shown below
Or you can use the Bean Integration to invoke a bean
You can also use Templating to consume a message from one destination, transform it with something like Velocity or XQuery and then send it on to another destination. For example using InOnly (one way messaging)
If you want to use InOut (request-reply) semantics to process requests on the My.Queue queue on ActiveMQ with a template generated response, then sending responses back to the JMSReplyTo Destination you could use this.
Message Endpoint
Camel supports the Message Endpoint from the EIP patterns using the Endpoint interface.
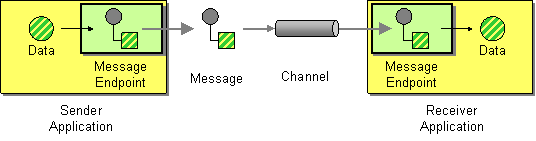
When using the DSL to create Routes you typically refer to Message Endpoints by their URIs rather than directly using the Endpoint interface. Its then a responsibility of the CamelContext to create and activate the necessary Endpoint instances using the available Component implementations.
Example
The following example route demonstrates the use of a File Consumer Endpoint and JMS Producer Endpoint
Using the Fluent Builders
from("file://local/router/messages/foo")
.to("jms:queue:foo");
Using the Spring XML Extensions
<route> <from uri="file://local/router/messages/foo"/> <to uri="jms:queue:foo"/> </route>
Dynamic To
Available as of Camel 2.16
There is a new <toD> that allows to send a message to a dynamic computed Endpoint using one or more Expression that are concat together. By default the Simple language is used to compute the endpoint. For example to send a message to a endpoint defined by a header you can do
<route>
<from uri="direct:start"/>
<toD uri="${header.foo}"/>
</route>
And in Java DSL
from("direct:start")
.toD("${header.foo}");
You can also prefix the uri with a value because by default the uri is evaluated using the Simple language
<route>
<from uri="direct:start"/>
<toD uri="mock:${header.foo}"/>
</route>
And in Java DSL
from("direct:start")
.toD("mock:${header.foo}");
In the example above we compute an endpoint that has prefix "mock:" and then the header foo is appended. So for example if the header foo has value order, then the endpoint is computed as "mock:order".
You can also use other languages than Simple such as XPath - this requires to prefix with language: as shown below (simple language is the default language). If you do not specify language: then the endpoint is a component name. And in some cases there is both a component and language with the same name such as xquery.
<route> <from uri="direct:start"/> <toD uri="language:xpath:/order/@uri"/> </route>
This is done by specifying the name of the language followed by a colon.
from("direct:start")
.toD("language:xpath:/order/@uri");
You can also concat multiple Language(s) together using the plus sign + such as shown below:
<route>
<from uri="direct:start"/>
<toD uri="jms:${header.base}+language:xpath:/order/@id"/>
</route>
In the example above the uri is a combination of Simple language and XPath where the first part is simple (simple is default language). And then the plus sign separate to another language, where we specify the language name followed by a colon
from("direct:start")
.toD("jms:${header.base}+language:xpath:/order/@id");
You can concat as many languages as you want, just separate them with the plus sign
The Dynamic To has a few options you can configure
| Name | Default Value | Description |
|---|---|---|
| uri | Mandatory: The uri to use. See above | |
| pattern | To set a specific Exchange Pattern to use when sending to the endpoint. The original MEP is restored afterwards. | |
| cacheSize | Allows to configure the cache size for the ProducerCache which caches producers for reuse. Will by default use the default cache size which is 1000. Setting the value to -1 allows to turn off the cache all together. | |
| ignoreInvalidEndpoint | false | Whether to ignore an endpoint URI that could not be resolved. If disabled, Camel will throw an exception identifying the invalid endpoint URI. |
For more details see
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Messaging Channels
Point to Point Channel
Camel supports the Point to Point Channel from the EIP patterns using the following components
- SEDA for in-VM seda based messaging
- JMS for working with JMS Queues for high performance, clustering and load balancing
- JPA for using a database as a simple message queue
- XMPP for point-to-point communication over XMPP (Jabber)
- and others

The following example demonstrates point to point messaging using the JMS component
Using the Fluent Builders
from("direct:start")
.to("jms:queue:foo");
Using the Spring XML Extensions
<route> <from uri="direct:start"/> <to uri="jms:queue:foo"/> </route>
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Publish Subscribe Channel
Camel supports the Publish Subscribe Channel from the EIP patterns using for example the following components:
- JMS for working with JMS Topics for high performance, clustering and load balancing
- XMPP when using rooms for group communication
- SEDA for working with SEDA in the same CamelContext which can work in pub-sub, but allowing multiple consumers.
- VM as SEDA but for intra-JVM.
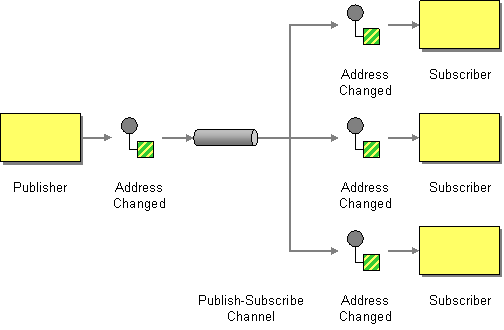
Using Routing Logic
Another option is to explicitly list the publish-subscribe relationship in your routing logic; this keeps the producer and consumer decoupled but lets you control the fine grained routing configuration using the DSL or Xml Configuration.
Using the Fluent Builders
Error formatting macro: snippet: java.lang.NullPointerException
Using the Spring XML Extensions
Error formatting macro: snippet: java.lang.NullPointerException
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Dead Letter Channel
Camel supports the Dead Letter Channel from the EIP patterns using the DeadLetterChannel processor which is an Error Handler.
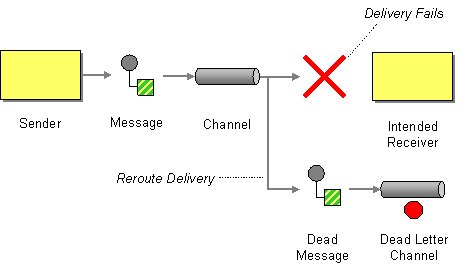
The DefaultErrorHandler does very little: it ends the Exchange immediately and propagates the thrown Exception back to the caller.
The DeadLetterChannel lets you control behaviors including redelivery, whether to propagate the thrown Exception to the caller (the handled option), and where the (failed) Exchange should now be routed to.
The DeadLetterChannel is also by default configured to not be verbose in the logs, so when a message is handled and moved to the dead letter endpoint, then there is nothing logged. If you want some level of logging you can use the various options on the redelivery policy / dead letter channel to configure this. For example if you want the message history then set logExhaustedMessageHistory=true (and logHandled=true for Camel 2.15.x or older).
When the DeadLetterChannel moves a message to the dead letter endpoint, any new Exception thrown is by default handled by the dead letter channel as well. This ensures that the DeadLetterChannel will always succeed. From Camel 2.15: this behavior can be changed by setting the option deadLetterHandleNewException=false. Then if a new Exception is thrown, then the dead letter channel will fail and propagate back that new Exception (which is the behavior of the default error handler). When a new Exception occurs then the dead letter channel logs this at WARN level. This can be turned off by setting logNewException=false.
Redelivery
It is common for a temporary outage or database deadlock to cause a message to fail to process; but the chances are if its tried a few more times with some time delay then it will complete fine. So we typically wish to use some kind of redelivery policy to decide how many times to try redeliver a message and how long to wait before redelivery attempts.
The RedeliveryPolicy defines how the message is to be redelivered. You can customize things like
- The number of times a message is attempted to be redelivered before it is considered a failure and sent to the dead letter channel.
- The initial redelivery timeout.
- Whether or not exponential backoff is used, i.e., the time between retries increases using a backoff multiplier.
- Whether to use collision avoidance to add some randomness to the timings.
- Delay pattern (see below for details).
- Camel 2.11: Whether to allow redelivery during stopping/shutdown.
Once all attempts at redelivering the message fails then the message is forwarded to the dead letter queue.
About Moving Exchange to Dead Letter Queue and Using handled()
handled() on Dead Letter Channel
When all attempts of redelivery have failed the Exchange is moved to the dead letter queue (the dead letter endpoint). The exchange is then complete and from the client point of view it was processed. As such the Dead Letter Channel have handled the Exchange.
For instance configuring the dead letter channel as:
Using the Fluent Builders
Using the Spring XML Extensions
The Dead Letter Channel above will clear the caused exception setException(null), by moving the caused exception to a property on the Exchange, with the key Exchange.EXCEPTION_CAUGHT. Then the Exchange is moved to the jms:queue:dead destination and the client will not notice the failure.
About Moving Exchange to Dead Letter Queue and Using the Original Message
The option useOriginalMessage is used for routing the original input message instead of the current message that potentially is modified during routing.
For instance if you have this route:
The route listen for JMS messages and validates, transforms and handle it. During this the Exchange payload is transformed/modified. So in case something goes wrong and we want to move the message to another JMS destination, then we can configure our Dead Letter Channel with the useOriginalMessage option. But when we move the Exchange to this destination we do not know in which state the message is in. Did the error happen in before the transformOrder or after? So to be sure we want to move the original input message we received from jms:queue:order:input. So we can do this by enabling the useOriginalMessage option as shown below:
Then the messages routed to the jms:queue:dead is the original input. If we want to manually retry we can move the JMS message from the failed to the input queue, with no problem as the message is the same as the original we received.
OnRedelivery
When Dead Letter Channel is doing redeliver its possible to configure a Processor that is executed just before every redelivery attempt. This can be used for the situations where you need to alter the message before its redelivered. See below for sample.
We also support for per onException to set an onRedeliver. That means you can do special on redelivery for different exceptions, as opposed to onRedelivery set on Dead Letter Channel can be viewed as a global scope.
Redelivery Default Values
Redelivery is disabled by default.
The default redeliver policy will use the following values:
maximumRedeliveries=0redeliverDelay=1000L(1 second)maximumRedeliveryDelay = 60 * 1000L(60 seconds)backOffMultiplieranduseExponentialBackOffare ignored.retriesExhaustedLogLevel=LoggingLevel.ERRORretryAttemptedLogLevel=LoggingLevel.DEBUG- Stack traces are logged for exhausted messages, from Camel 2.2.
- Handled exceptions are not logged, from Camel 2.3.
logExhaustedMessageHistoryis true for default error handler, and false for dead letter channel.logExhaustedMessageBodyCamel 2.17: is disabled by default to avoid logging sensitive message body/header details. If this option istrue, thenlogExhaustedMessageHistorymust also betrue.
The maximum redeliver delay ensures that a delay is never longer than the value, default 1 minute. This can happen when useExponentialBackOff=true.
The maximumRedeliveries is the number of re-delivery attempts. By default Camel will try to process the exchange 1 + 5 times. 1 time for the normal attempt and then 5 attempts as redeliveries.
Setting the maximumRedeliveries=-1 (or < -1) will then always redelivery (unlimited).
Setting the maximumRedeliveries=0 will disable re-delivery.
Camel will log delivery failures at the DEBUG logging level by default. You can change this by specifying retriesExhaustedLogLevel and/or retryAttemptedLogLevel. See ExceptionBuilderWithRetryLoggingLevelSetTest for an example.
You can turn logging of stack traces on/off. If turned off Camel will still log the redelivery attempt. It's just much less verbose.
Redeliver Delay Pattern
Delay pattern is used as a single option to set a range pattern for delays. When a delay pattern is in use the following options no longer apply:
delaybackOffMultiplieruseExponentialBackOffuseCollisionAvoidancemaximumRedeliveryDelay
The idea is to set groups of ranges using the following syntax: limit:delay;limit 2:delay 2;limit 3:delay 3;...;limit N:delay N
Each group has two values separated with colon:
limit= upper limitdelay= delay in milliseconds
And the groups is again separated with semi-colon. The rule of thumb is that the next groups should have a higher limit than the previous group.
Lets clarify this with an example:
delayPattern=5:1000;10:5000;20:20000
That gives us three groups:
5:100010:500020:20000
Resulting in these delays between redelivery attempts:
- Redelivery attempt number
1..4 = 0ms(as the first group start with 5) - Redelivery attempt number
5..9 = 1000ms(the first group) - Redelivery attempt number
10..19 = 5000ms(the second group) - Redelivery attempt number
20.. = 20000ms(the last group)
Note: The first redelivery attempt is 1, so the first group should start with 1 or higher.
You can start a group with limit 1 to e.g., have a starting delay: delayPattern=1:1000;5:5000
- Redelivery attempt number
1..4 = 1000ms(the first group) - Redelivery attempt number
5.. = 5000ms(the last group)
There is no requirement that the next delay should be higher than the previous. You can use any delay value you like. For example with delayPattern=1:5000;3:1000 we start with 5 sec delay and then later reduce that to 1 second.
Redelivery header
When a message is redelivered the DeadLetterChannel will append a customizable header to the message to indicate how many times its been redelivered.
Before Camel 2.6: The header is CamelRedeliveryCounter, which is also defined on the Exchange.REDELIVERY_COUNTER.
From Camel 2.6: The header CamelRedeliveryMaxCounter, which is also defined on the Exchange.REDELIVERY_MAX_COUNTER, contains the maximum redelivery setting. This header is absent if you use retryWhile or have unlimited maximum redelivery configured.
And a boolean flag whether it is being redelivered or not (first attempt). The header CamelRedelivered contains a boolean if the message is redelivered or not, which is also defined on the Exchange.REDELIVERED.
Dynamically Calculated Delay From the Exchange
In Camel 2.9 and 2.8.2: The header is CamelRedeliveryDelay, which is also defined on the Exchange.REDELIVERY_DELAY. If this header is absent, normal redelivery rules apply.
Which Endpoint Failed
Available as of Camel 2.1
When Camel routes messages it will decorate the Exchange with a property that contains the last endpoint Camel send the Exchange to:
The Exchange.TO_ENDPOINT have the constant value CamelToEndpoint. This information is updated when Camel sends a message to any endpoint. So if it exists its the last endpoint which Camel send the Exchange to.
When for example processing the Exchange at a given Endpoint and the message is to be moved into the dead letter queue, then Camel also decorates the Exchange with another property that contains that last endpoint:
The Exchange.FAILURE_ENDPOINT have the constant value CamelFailureEndpoint.
This allows for example you to fetch this information in your dead letter queue and use that for error reporting. This is usable if the Camel route is a bit dynamic such as the dynamic Recipient List so you know which endpoints failed.
Note: this information is retained on the Exchange even if the message is subsequently processed successfully by a given endpoint only to fail, for example, in local Bean processing instead. So, beware that this is a hint that helps pinpoint errors.
Now suppose the route above and a failure happens in the foo bean. Then the Exchange.TO_ENDPOINT and Exchange.FAILURE_ENDPOINT will still contain the value of http://someserver/somepath.
OnPrepareFailure
Available as of Camel 2.16
Before the exchange is sent to the dead letter queue, you can use onPrepare to allow a custom Processor to prepare the exchange, such as adding information why the Exchange failed.
For example, the following processor adds a header with the exception message:
Then configure the error handler to use the processor as follows:
Configuring this from XML DSL is as follows:
The onPrepare is also available using the default error handler.
Which Route Failed
Available as of Camel 2.10.4/2.11
When Camel error handler handles an error such as Dead Letter Channel or using Exception Clause with handled=true, then Camel will decorate the Exchange with the route id where the error occurred.
Example:
The Exchange.FAILURE_ROUTE_ID have the constant value CamelFailureRouteId. This allows for example you to fetch this information in your dead letter queue and use that for error reporting.
Control if Redelivery is Allowed During Stopping/Shutdown
Available as of Camel 2.11
Before Camel 2.10, Camel would perform redelivery while stopping a route, or shutting down Camel. This has improved a bit in Camel 2.10: Camel will no longer perform redelivery attempts when shutting down aggressively, e.g., during Graceful Shutdown and timeout hit.
From Camel 2.11: there is a new option allowRedeliveryWhileStopping which you can use to control if redelivery is allowed or not; notice that any in progress redelivery will still be executed. This option can only disallow any redelivery to be executed after the stopping of a route/shutdown of Camel has been triggered. If a redelivery is disallowed then a RejectedExcutionException is set on the Exchange and the processing of the Exchange stops. This means any consumer will see the Exchange as failed due the RejectedExcutionException. The default value is true for backward compatibility.
For example, the following snippet shows how to do this with Java DSL and XML DSL:
Samples
The following example shows how to configure the Dead Letter Channel configuration using the DSL
How Can I Modify the Exchange Before Redelivery?
We support directly in Dead Letter Channel to set a Processor that is executed before each redelivery attempt. When Dead Letter Channel is doing redeliver its possible to configure a Processor that is executed just before every redelivery attempt. This can be used for the situations where you need to alter the message before its redelivered. Here we configure the Dead Letter Channel to use our processor MyRedeliveryProcessor to be executed before each redelivery.MyRedeliveryProcessor where we alter the message.
How Can I Log What Caused the Dead Letter Channel to be Invoked?
You often need to know what went wrong that caused the Dead Letter Channel to be used and it does not offer logging for this purpose. So the Dead Letter Channel's endpoint can be set to a endpoint of our own (such as direct:deadLetterChannel). We write a route to accept this Exchange and log the Exception, then forward on to where we want the failed Exchange moved to (which might be a DLQ queue for instance). See also http://stackoverflow.com/questions/13711462/logging-camel-exceptions-and-sending-to-the-dead-letter-channel
Guaranteed Delivery
Camel supports the Guaranteed Delivery from the EIP patterns using among others the following components:
- File for using file systems as a persistent store of messages
- JMS when using persistent delivery (the default) for working with JMS Queues and Topics for high performance, clustering and load balancing
- JPA for using a database as a persistence layer, or use any of the many other database component such as SQL, JDBC, iBATIS/MyBatis, Hibernate
- HawtDB for a lightweight key-value persistent store
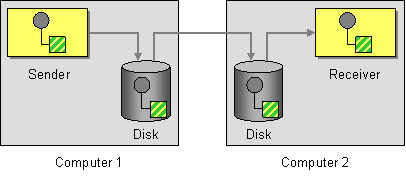
Example
The following example demonstrates illustrates the use of Guaranteed Delivery within the JMS component. By default, a message is not considered successfully delivered until the recipient has persisted the message locally guaranteeing its receipt in the event the destination becomes unavailable.
Using the Fluent Builders
from("direct:start")
.to("jms:queue:foo");
Using the Spring XML Extensions
<route> <from uri="direct:start"/> <to uri="jms:queue:foo"/> </route>
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Message Bus
Camel supports the Message Bus from the EIP patterns. You could view Camel as a Message Bus itself as it allows producers and consumers to be decoupled.
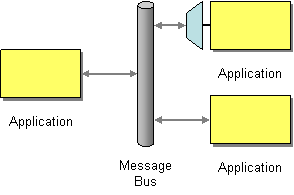
Folks often assume that a Message Bus is a JMS though so you may wish to refer to the JMS component for traditional MOM support.
Also worthy of note is the XMPP component for supporting messaging over XMPP (Jabber)
Of course there are also ESB products such as Apache ServiceMix which serve as full fledged message busses.
You can interact with Apache ServiceMix from Camel in many ways, but in particular you can use the NMR or JBI component to access the ServiceMix message bus directly.
Example
The following demonstrates how the Camel message bus can be used to communicate with consumers and producers
Using the Fluent Builders
from("direct:start")
.pollEnrich("file:inbox?fileName=data.txt")
.to("jms:queue:foo");
Using the Spring XML Extensions
<route> <from uri="direct:start"/> <pollEnrich uri="file:inbox?fileName=data.txt"/> <to uri="jms:queue:foo"/> </route>
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Message Construction
Event Message
Camel supports the Event Message from the EIP patterns by supporting the Exchange Pattern on a Message which can be set to InOnly to indicate a oneway event message. Camel Components then implement this pattern using the underlying transport or protocols.
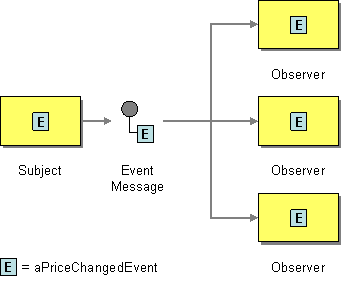
The default behaviour of many Components is InOnly such as for JMS, File or SEDA
Related
See the related Request Reply message.
Explicitly specifying InOnly
If you are using a component which defaults to InOut you can override the Exchange Pattern for an endpoint using the pattern property.
foo:bar?exchangePattern=InOnly
From 2.0 onwards on Camel you can specify the Exchange Pattern using the DSL.
Using the Fluent Builders
from("mq:someQueue").
setExchangePattern(ExchangePattern.InOnly).
bean(Foo.class);
or you can invoke an endpoint with an explicit pattern
from("mq:someQueue").
inOnly("mq:anotherQueue");
Using the Spring XML Extensions
<route>
<from uri="mq:someQueue"/>
<inOnly uri="bean:foo"/>
</route>
<route>
<from uri="mq:someQueue"/>
<inOnly uri="mq:anotherQueue"/>
</route>
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Correlation Identifier
Camel supports the Correlation Identifier from the EIP patterns by getting or setting a header on a Message.
When working with the ActiveMQ or JMS components the correlation identifier header is called JMSCorrelationID. You can add your own correlation identifier to any message exchange to help correlate messages together to a single conversation (or business process).
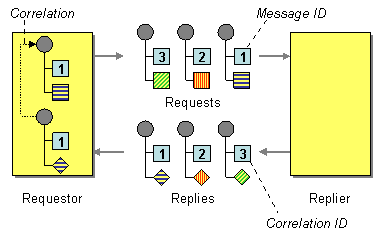
The use of a Correlation Identifier is key to working with the Camel Business Activity Monitoring Framework and can also be highly useful when testing with simulation or canned data such as with the Mock testing framework
Some EIP patterns will spin off a sub message, and in those cases, Camel will add a correlation id on the Exchange as a property with they key Exchange.CORRELATION_ID, which links back to the source Exchange. For example the Splitter, Multicast, Recipient List, and Wire Tap EIP does this.
The following example demonstrates using the Camel JMSMessageID as the Correlation Identifier within a request/reply pattern in the JMS component
Using the Fluent Builders
from("direct:start")
.to(ExchangePattern.InOut,"jms:queue:foo?useMessageIDAsCorrelationID=true")
.to("mock:result");
Using the Spring XML Extensions
<route> <from uri="direct:start"/> <to uri="jms:queue:foo?useMessageIDAsCorrelationID=true" pattern="InOut"/> <to uri="mock:result"/> </route>
See Also
Return Address
Camel supports the Return Address from the EIP patterns by using the JMSReplyTo header.
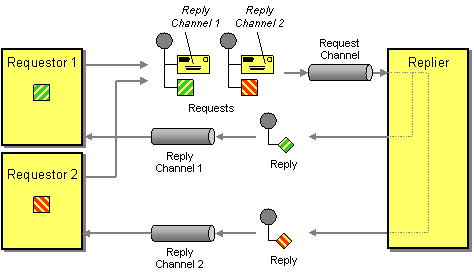
For example when using JMS with InOut the component will by default return to the address given in JMSReplyTo.
Requestor Code
getMockEndpoint("mock:bar").expectedBodiesReceived("Bye World");
template.sendBodyAndHeader("direct:start", "World", "JMSReplyTo", "queue:bar");
Route Using the Fluent Builders
from("direct:start").to("activemq:queue:foo?preserveMessageQos=true");
from("activemq:queue:foo").transform(body().prepend("Bye "));
from("activemq:queue:bar?disableReplyTo=true").to("mock:bar");
Route Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:queue:foo?preserveMessageQos=true"/>
</route>
<route>
<from uri="activemq:queue:foo"/>
<transform>
<simple>Bye ${in.body}</simple>
</transform>
</route>
<route>
<from uri="activemq:queue:bar?disableReplyTo=true"/>
<to uri="mock:bar"/>
</route>
For a complete example of this pattern, see this junit test case
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Message Routing
Content Based Router
The Content Based Router from the EIP patterns allows you to route messages to the correct destination based on the contents of the message exchanges.
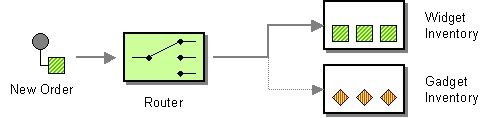
The following example shows how to route a request from an input seda:a endpoint to either seda:b, seda:c or seda:d depending on the evaluation of various Predicate expressions
Using the Fluent Builders
RouteBuilder builder = new RouteBuilder() {
public void configure() {
errorHandler(deadLetterChannel("mock:error"));
from("direct:a")
.choice()
.when(header("foo").isEqualTo("bar"))
.to("direct:b")
.when(header("foo").isEqualTo("cheese"))
.to("direct:c")
.otherwise()
.to("direct:d");
}
};
See Why can I not use when or otherwise in a Java Camel route if you have problems with the Java DSL, accepting using when or otherwise.
Using the Spring XML Extensions
<camelContext errorHandlerRef="errorHandler" xmlns="http://camel.apache.org/schema/spring">
<route>
<from uri="direct:a"/>
<choice>
<when>
<xpath>$foo = 'bar'</xpath>
<to uri="direct:b"/>
</when>
<when>
<xpath>$foo = 'cheese'</xpath>
<to uri="direct:c"/>
</when>
<otherwise>
<to uri="direct:d"/>
</otherwise>
</choice>
</route>
</camelContext>
For further examples of this pattern in use you could look at the junit test case
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Message Filter
The Message Filter from the EIP patterns allows you to filter messages

The following example shows how to create a Message Filter route consuming messages from an endpoint called queue:a, which if the Predicate is true will be dispatched to queue:b
Using the Fluent Builders
Using the Spring XML Extensions
Ensure you put the endpoint you want to filter <to uri="seda:b"/> before the closing </filter> tag or the filter will not be applied. From Camel 2.8: omitting this will result in an error.
For further examples of this pattern in use you could look at the junit test case
Using stop()
Stop is a bit different than a message filter as it will filter out all messages and end the route entirely (filter only applies to its child processor). Stop is convenient to use in a Content Based Router when you for example need to stop further processing in one of the predicates.
In the example below we do not want to route messages any further that has the word Bye in the message body. Notice how we prevent this in the when() predicate by using the .stop().
How To Determine If An Exchange Was Filtered
Available as of Camel 2.5
The Message Filter EIP will add a property on the Exchange that states if it was filtered or not.
The property has the key Exchange.FILTER_MATCHED, which has the String value of CamelFilterMatched. Its value is a boolean indicating true or false. If the value is true then the Exchange was routed in the filter block. This property will be visible within the Message Filter block who's Predicate matches (value set to true), and to the steps immediately following the Message Filter with the value set based on the results of the last Message Filter Predicate evaluated.
Dynamic Router
The Dynamic Router from the EIP patterns allows you to route messages while avoiding the dependency of the router on all possible destinations while maintaining its efficiency.
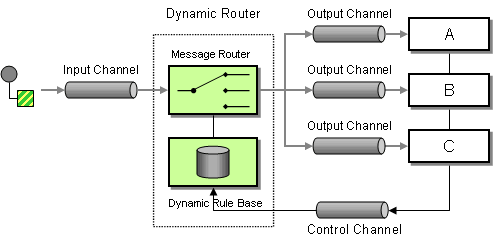
In Camel 2.5 we introduced a dynamicRouter in the DSL which is like a dynamic Routing Slip which evaluates the slip on-the-fly.
You must ensure the expression used for the dynamicRouter such as a bean, will return null to indicate the end. Otherwise the dynamicRouter will keep repeating endlessly.
Options
Name |
Default Value |
Description |
|---|---|---|
|
|
Delimiter used if the Expression returned multiple endpoints. |
|
|
If an endpoint uri could not be resolved, should it be ignored. Otherwise Camel will thrown an exception stating the endpoint uri is not valid. |
|
|
Camel 2.13.1/2.12.4: Allows to configure the cache size for the |
Dynamic Router in Camel 2.5 onwards
From Camel 2.5 the Dynamic Router will set a property (Exchange.SLIP_ENDPOINT) on the Exchange which contains the current endpoint as it advanced though the slip. This allows you to know how far we have processed in the slip. (It's a slip because the Dynamic Router implementation is based on top of Routing Slip).
Java DSL
In Java DSL you can use the dynamicRouter as shown below:
Which will leverage a Bean to compute the slip on-the-fly, which could be implemented as follows:
Mind that this example is only for show and tell. The current implementation is not thread safe. You would have to store the state on the Exchange, to ensure thread safety, as shown below:
You could also store state as message headers, but they are not guaranteed to be preserved during routing, where as properties on the Exchange are. Although there was a bug in the method call expression, see the warning below.
Mind that in Camel 2.9.2 or older, when using a Bean the state is not propagated, so you will have to use a Processor instead. This is fixed in Camel 2.9.3 onwards.
Spring XML
The same example in Spring XML would be:
@DynamicRouter annotation
You can also use the @DynamicRouter annotation, for example the Camel 2.4 example below could be written as follows. The route method would then be invoked repeatedly as the message is processed dynamically. The idea is to return the next endpoint uri where to go. Return null to indicate the end. You can return multiple endpoints if you like, just as the Routing Slip, where each endpoint is separated by a delimiter.
Dynamic Router in Camel 2.4 or older
The simplest way to implement this is to use the RecipientList Annotation on a Bean method to determine where to route the message.
In the above we can use the Parameter Binding Annotations to bind different parts of the Message to method parameters or use an Expression such as using XPath or XQuery.
The method can be invoked in a number of ways as described in the Bean Integration such as
- POJO Producing
- Spring Remoting
- Bean component
Aggregator
This applies for Camel version 2.3 or newer. If you use an older version then use this Aggregator link instead.
The Aggregator from the EIP patterns allows you to combine a number of messages together into a single message.
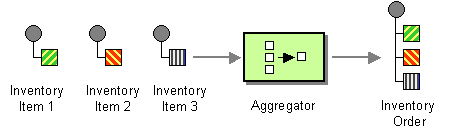
A correlation Expression is used to determine the messages which should be aggregated together. If you want to aggregate all messages into a single message, just use a constant expression. An AggregationStrategy is used to combine all the message exchanges for a single correlation key into a single message exchange.
Aggregator options
The aggregator supports the following options:
confluenceTableSmall
Option | Default | Description |
|---|---|---|
|
| Mandatory Expression which evaluates the correlation key to use for aggregation. The Exchange which has the same correlation key is aggregated together. If the correlation key could not be evaluated an Exception is thrown. You can disable this by using the |
|
| Mandatory From Camel 2.9.2 onwards the strategy can also be a From Camel 2.16: the strategy can also be a |
|
| A reference to lookup the |
|
| Camel 2.12: This option can be used to explicit declare the method name to use, when using POJOs as the |
|
| Camel 2.12: If this option is |
|
| Number of messages aggregated before the aggregation is complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a size dynamically - will use |
|
| Time in millis that an aggregated exchange should be inactive before its complete. This option can be set as either a fixed value or using an Expression which allows you to evaluate a timeout dynamically - will use |
|
| A repeating period in millis by which the aggregator will complete all current aggregated exchanges. Camel has a background task which is triggered every period. You cannot use this option together with |
|
| A Predicate to indicate when an aggregated exchange is complete. From Camel 2.15: if this is not specified and the |
|
| This option is if the exchanges are coming from a Batch Consumer. Then when enabled the Aggregator2 will use the batch size determined by the Batch Consumer in the message header |
|
| Camel 2.9 Indicates to complete all current aggregated exchanges when the context is stopped |
completeAllOnStop | false | Camel 2.16: Indicates to wait to complete all current and partial (pending) aggregated exchanges when the context is stopped. This also means that we will wait for all pending exchanges which are stored in the aggregation repository to complete so the repository is empty before we can stop. You may want to enable this when using the memory based aggregation repository that is memory based only, and do not store data on disk. When this option is enabled, then the aggregator is waiting to complete all those exchanges before its stopped, when stopping CamelContext or the route using it. |
|
| Whether or not to eager check for completion when a new incoming Exchange has been received. This option influences the behavior of the |
|
| If enabled then Camel will group all aggregated Exchanges into a single combined Note: this option does not support persistent repository with the aggregator. See further below for an example and more details. |
|
| Whether or not to ignore correlation keys which could not be evaluated to a value. By default Camel will throw an Exception, but you can enable this option and ignore the situation instead. |
|
| Whether or not too late Exchanges should be accepted or not. You can enable this to indicate that if a correlation key has already been completed, then any new exchanges with the same correlation key be denied. Camel will then throw a |
|
| Camel 2.5: Whether or not exchanges which complete due to a timeout should be discarded. If enabled then when a timeout occurs the aggregated message will not be sent out but dropped (discarded). |
|
| Allows you to plugin you own implementation of |
|
| Reference to lookup a |
|
| When aggregated are completed they are being send out of the aggregator. This option indicates whether or not Camel should use a thread pool with multiple threads for concurrency. If no custom thread pool has been specified then Camel creates a default pool with 10 concurrent threads. |
|
| If using |
|
| Reference to lookup a |
|
| Camel 2.9: If using either of the |
|
| Camel 2.9: Reference to lookup a |
|
| Camel 2.11: Turns on using optimistic locking, which requires the |
|
| Camel 2.11.1: Allows to configure retry settings when using optimistic locking. |
Exchange Properties
The following properties are set on each aggregated Exchange:
confluenceTableSmall
Header | Type | Description |
|---|---|---|
|
| The total number of Exchanges aggregated into this combined Exchange. |
|
| Indicator how the aggregation was completed as a value of either: |
About AggregationStrategy
The AggregationStrategy is used for aggregating the old (lookup by its correlation id) and the new exchanges together into a single exchange. Possible implementations include performing some kind of combining or delta processing, such as adding line items together into an invoice or just using the newest exchange and removing old exchanges such as for state tracking or market data prices; where old values are of little use.
Notice the aggregation strategy is a mandatory option and must be provided to the aggregator.
Here are a few example AggregationStrategy implementations that should help you create your own custom strategy.
Resequencer
The Resequencer from the EIP patterns allows you to reorganise messages based on some comparator. By default in Camel we use an Expression to create the comparator; so that you can compare by a message header or the body or a piece of a message etc.
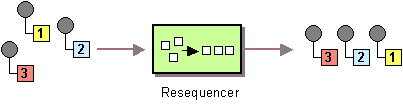
The <batch-config> and <stream-config> tags in XML DSL in the Resequencer EIP must now be configured in the top, and not in the bottom. So if you use those, then move them up just below the <resequence> EIP starts in the XML. If you are using Camel older than 2.7, then those configs should be at the bottom.
Camel supports two resequencing algorithms:
- Batch resequencing collects messages into a batch, sorts the messages and sends them to their output.
- Stream resequencing re-orders (continuous) message streams based on the detection of gaps between messages.
By default the Resequencer does not support duplicate messages and will only keep the last message, in case a message arrives with the same message expression. However in the batch mode you can enable it to allow duplicates.
Batch Resequencing
The following example shows how to use the batch-processing resequencer so that messages are sorted in order of the body() expression. That is messages are collected into a batch (either by a maximum number of messages per batch or using a timeout) then they are sorted in order and then sent out to their output.
Using the Fluent Builders
The batch-processing resequencer can be further configured via the size() and timeout() methods.
This sets the batch size to 300 and the batch timeout to 4000 ms (by default, the batch size is 100 and the timeout is 1000 ms). Alternatively, you can provide a configuration object.
So the above example will reorder messages from endpoint direct:a in order of their bodies, to the endpoint mock:result.
Typically you'd use a header rather than the body to order things; or maybe a part of the body. So you could replace this expression with
for example to reorder messages using a custom sequence number in the header mySeqNo.
You can of course use many different Expression languages such as XPath, XQuery, SQL or various Scripting Languages.
Using the Spring XML Extensions
Allow Duplicates
Available as of Camel 2.4
In the batch mode, you can now allow duplicates. In Java DSL there is a allowDuplicates() method and in Spring XML there is an allowDuplicates=true attribute on the <batch-config/> you can use to enable it.
Reverse
Available as of Camel 2.4
In the batch mode, you can now reverse the expression ordering. By default the order is based on 0..9,A..Z, which would let messages with low numbers be ordered first, and thus also also outgoing first. In some cases you want to reverse order, which is now possible.
In Java DSL there is a reverse() method and in Spring XML there is an reverse=true attribute on the <batch-config/> you can use to enable it.
Resequence JMS messages based on JMSPriority
Available as of Camel 2.4
It's now much easier to use the Resequencer to resequence messages from JMS queues based on JMSPriority. For that to work you need to use the two new options allowDuplicates and reverse.batch mode of the Resequencer.
Ignore invalid exchanges
Available as of Camel 2.9
The Resequencer EIP will from Camel 2.9 onwards throw a CamelExchangeException if the incoming Exchange is not valid for the resequencer - ie. the expression cannot be evaluated, such as a missing header. You can use the option ignoreInvalidExchanges to ignore these exceptions which means the Resequencer will then skip the invalid Exchange.
Reject Old Exchanges
Available as of Camel 2.11
This option can be used to prevent out of order messages from being sent regardless of the event that delivered messages downstream (capacity, timeout, etc). If enabled using rejectOld(), the Resequencer will throw a MessageRejectedException when an incoming Exchange is "older" (based on the Comparator) than the last delivered message. This provides an extra level of control with regards to delayed message ordering.
This option is available for the stream resequencer only.
Stream Resequencing
The next example shows how to use the stream-processing resequencer. Messages are re-ordered based on their sequence numbers given by a seqnum header using gap detection and timeouts on the level of individual messages.
Using the Fluent Builderscapacity() and timeout() methods.
This sets the resequencer's capacity to 5000 and the timeout to 4000 ms (by default, the capacity is 1000 and the timeout is 1000 ms). Alternatively, you can provide a configuration object.
The stream-processing resequencer algorithm is based on the detection of gaps in a message stream rather than on a fixed batch size. Gap detection in combination with timeouts removes the constraint of having to know the number of messages of a sequence (i.e. the batch size) in advance. Messages must contain a unique sequence number for which a predecessor and a successor is known. For example a message with the sequence number 3 has a predecessor message with the sequence number 2 and a successor message with the sequence number 4. The message sequence 2,3,5 has a gap because the successor of 3 is missing. The resequencer therefore has to retain message 5 until message 4 arrives (or a timeout occurs).
If the maximum time difference between messages (with successor/predecessor relationship with respect to the sequence number) in a message stream is known, then the resequencer's timeout parameter should be set to this value. In this case it is guaranteed that all messages of a stream are delivered in correct order to the next processor. The lower the timeout value is compared to the out-of-sequence time difference the higher is the probability for out-of-sequence messages delivered by this resequencer. Large timeout values should be supported by sufficiently high capacity values. The capacity parameter is used to prevent the resequencer from running out of memory.
By default, the stream resequencer expects long sequence numbers but other sequence numbers types can be supported as well by providing a custom expression.comparator() method
or via a StreamResequencerConfig object.
Using the Spring XML Extensions
Further Examples
For further examples of this pattern in use you could look at the batch-processing resequencer junit test case and the stream-processing resequencer junit test case
Composed Message Processor
The Composed Message Processor from the EIP patterns allows you to process a composite message by splitting it up, routing the sub-messages to appropriate destinations and the re-aggregating the responses back into a single message.
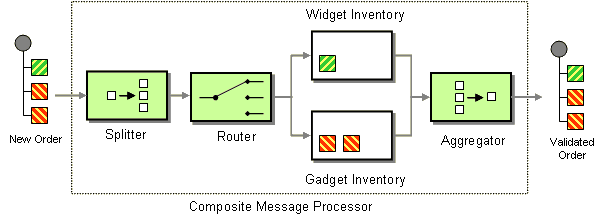
In Camel we provide two solutions
- using both a Splitter and Aggregator EIPs
- using only a Splitter
The difference is when using only a Splitter it aggregates back all the splitted messages into the same aggregation group, eg like a fork/join pattern.
Whereas using the Aggregator allows you group into multiple groups, a pattern which provides more options.
Using the splitter alone is often easier and possibly a better solution. So take a look at this first, before involving the aggregator.
Example using both Splitter and Aggregator
In this example we want to check that a multipart order can be filled. Each part of the order requires a check at a different inventory.
Error formatting macro: snippet: java.lang.NullPointerException
Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<split>
<simple>body</simple>
<choice>
<when>
<method bean="orderItemHelper" method="isWidget"/>
<to uri="bean:widgetInventory"/>
</when>
<otherwise>
<to uri="bean:gadgetInventory"/>
</otherwise>
</choice>
<to uri="seda:aggregate"/>
</split>
</route>
<route>
<from uri="seda:aggregate"/>
<aggregate strategyRef="myOrderAggregatorStrategy" completionTimeout="1000">
<correlationExpression>
<simple>header.orderId</simple>
</correlationExpression>
<to uri="mock:result"/>
</aggregate>
</route>
To do this we split up the order using a Splitter. The Splitter then sends individual OrderItems to a Content Based Router which checks the item type. Widget items get sent for checking in the widgetInventory bean and gadgets get sent to the gadgetInventory bean. Once these OrderItems have been validated by the appropriate bean, they are sent on to the Aggregator which collects and re-assembles the validated OrderItems into an order again.
When an order is sent it contains a header with the order id. We use this fact when we aggregate, as we configure this .header("orderId") on the aggregate DSL to instruct Camel to use the header with the key orderId as correlation expression.
For full details, check the example source here:
camel-core/src/test/java/org/apache/camel/processor/ComposedMessageProcessorTest.java
Example using only Splitter
In this example we want to split an incoming order using the Splitter eip, transform each order line, and then combine the order lines into a new order message.
Error formatting macro: snippet: java.lang.NullPointerException
Using XML
If you use XML, then the <split> tag offers the strategyRef attribute to refer to your custom AggregationStrategy
The bean with the methods to transform the order line and process the order as well:
Error formatting macro: snippet: java.lang.NullPointerException
And the AggregationStrategy we use with the Splitter eip to combine the orders back again (eg fork/join):
Error formatting macro: snippet: java.lang.NullPointerException
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Scatter-Gather
The Scatter-Gather from the EIP patterns allows you to route messages to a number of dynamically specified recipients and re-aggregate the responses back into a single message.
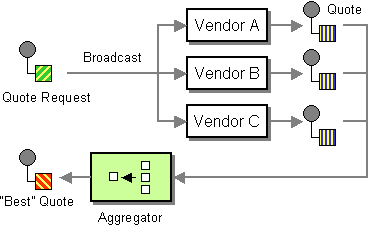
Dynamic Scatter-Gather Example
In this example we want to get the best quote for beer from several different vendors. We use a dynamic Recipient List to get the request for a quote to all vendors and an Aggregator to pick the best quote out of all the responses. The routes for this are defined as:
Error formatting macro: snippet: java.lang.NullPointerException
So in the first route you see that the Recipient List is looking at the listOfVendors header for the list of recipients. So, we need to send a message like
Error formatting macro: snippet: java.lang.NullPointerException
This message will be distributed to the following Endpoints: bean:vendor1, bean:vendor2, and bean:vendor3. These are all beans which look like
Error formatting macro: snippet: java.lang.NullPointerException
and are loaded up in Spring like
Error formatting macro: snippet: java.lang.NullPointerException
Each bean is loaded with a different price for beer. When the message is sent to each bean endpoint, it will arrive at the MyVendor.getQuote method. This method does a simple check whether this quote request is for beer and then sets the price of beer on the exchange for retrieval at a later step. The message is forwarded on to the next step using POJO Producing (see the @Produce annotation).
At the next step we want to take the beer quotes from all vendors and find out which one was the best (i.e. the lowest!). To do this we use an Aggregator with a custom aggregation strategy. The Aggregator needs to be able to compare only the messages from this particular quote; this is easily done by specifying a correlationExpression equal to the value of the quoteRequestId header. As shown above in the message sending snippet, we set this header to quoteRequest-1. This correlation value should be unique or you may include responses that are not part of this quote. To pick the lowest quote out of the set, we use a custom aggregation strategy like
Error formatting macro: snippet: java.lang.NullPointerException
Finally, we expect to get the lowest quote of $1 out of $1, $2, and $3.
Error formatting macro: snippet: java.lang.NullPointerException
You can find the full example source here:
camel-spring/src/test/java/org/apache/camel/spring/processor/scattergather/
camel-spring/src/test/resources/org/apache/camel/spring/processor/scattergather/scatter-gather.xml
Static Scatter-Gather Example
You can lock down which recipients are used in the Scatter-Gather by using a static Recipient List. It looks something like this
from("direct:start").multicast().to("seda:vendor1", "seda:vendor2", "seda:vendor3");
from("seda:vendor1").to("bean:vendor1").to("seda:quoteAggregator");
from("seda:vendor2").to("bean:vendor2").to("seda:quoteAggregator");
from("seda:vendor3").to("bean:vendor3").to("seda:quoteAggregator");
from("seda:quoteAggregator")
.aggregate(header("quoteRequestId"), new LowestQuoteAggregationStrategy()).to("mock:result")
A full example of the static Scatter-Gather configuration can be found in the Loan Broker Example.
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Routing Slip
The Routing Slip from the EIP patterns allows you to route a message consecutively through a series of processing steps where the sequence of steps is not known at design time and can vary for each message.
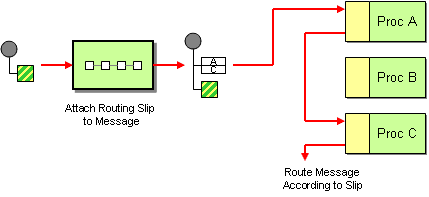
Options
Name | Default Value | Description |
|---|---|---|
|
| Delimiter used if the Expression returned multiple endpoints. |
|
| If an endpoint URI could not be resolved, should it be ignored. Otherwise, Camel will throw an exception stating the endpoint URI is not valid. |
|
| Camel 2.13.1/2.12.4: Allows to configure the cache size for the The default cache size is A value of |
Example
The following route will take any messages sent to the Apache ActiveMQ queue SomeQueue and pass them into the Routing Slip pattern.
Messages will be checked for the existence of the aRoutingSlipHeader header. The value of this header should be a comma-delimited list of endpoint URIs you wish the message to be routed to. The Message will be routed in a pipeline fashion, i.e., one after the other. From Camel 2.5 the Routing Slip will set a property, Exchange.SLIP_ENDPOINT, on the Exchange which contains the current endpoint as it advanced though the slip. This allows you to know how far we have processed in the slip.
The Routing Slip will compute the slip beforehand which means, the slip is only computed once. If you need to compute the slip on-the-fly then use the Dynamic Router pattern instead.
Configuration Options
Here we set the header name and the URI delimiter to something different.
Using the Fluent Builders
Ignore Invalid Endpoints
Available as of Camel 2.3
The Routing Slip now supports ignoreInvalidEndpoints which the Recipient List also supports. You can use it to skip endpoints which are invalid.
And in Spring XML its an attribute on the recipient list tag:
Then let's say the myHeader contains the following two endpoints direct:foo,xxx:bar. The first endpoint is valid and works. However the second endpoint is invalid and will just be ignored. Camel logs at INFO level, so you can see why the endpoint was invalid.
Expression Support
Available as of Camel 2.4
The Routing Slip now supports to take the expression parameter as the Recipient List does. You can tell Camel the expression that you want to use to get the routing slip.
And in Spring XML its an attribute on the recipient list tag.
Further Examples
For further examples of this pattern in use you could look at the routing slip test cases.
Throttler
The Throttler Pattern allows you to ensure that a specific endpoint does not get overloaded, or that we don't exceed an agreed SLA with some external service.
Options
Name |
Default Value |
Description |
|---|---|---|
|
|
Maximum number of requests per period to throttle. This option must be provided as a positive number. Notice, in the XML DSL, from Camel 2.8 onwards this option is configured using an Expression instead of an attribute. |
|
|
The time period in milliseconds, in which the throttler will allow at most |
|
|
Camel 2.4: If enabled then any messages which is delayed happens asynchronously using a scheduled thread pool. |
|
|
Camel 2.4: Refers to a custom Thread Pool to be used if |
|
|
Camel 2.4: Is used if |
|
|
Camel 2.14: If this option is true, throttler throws a ThrottlerRejectExecutionException when the request rate exceeds the limit. |
Examples
Using the Fluent Builders
So the above example will throttle messages all messages received on seda:a before being sent to mock:result ensuring that a maximum of 3 messages are sent in any 10 second window.
Note that since timePeriodMillis defaults to 1000 milliseconds, just setting the maximumRequestsPerPeriod has the effect of setting the maximum number of requests per second. So to throttle requests at 100 requests per second between two endpoints, it would look more like this...
For further examples of this pattern in use you could look at the junit test case
Using the Spring XML Extensions
Camel 2.7.x or older
Camel 2.8 onwards
In Camel 2.8 onwards you must set the maximum period as an Expression as shown below where we use a Constant expression:
Dynamically changing maximum requests per period
Available as of Camel 2.8
Since we use an Expression you can adjust this value at runtime, for example you can provide a header with the value. At runtime Camel evaluates the expression and converts the result to a java.lang.Long type. In the example below we use a header from the message to determine the maximum requests per period. If the header is absent, then the Throttler uses the old value. So that allows you to only provide a header if the value is to be changed:
Asynchronous delaying
Available as of Camel 2.4
You can let the Throttler use non blocking asynchronous delaying, which means Camel will use a scheduler to schedule a task to be executed in the future. The task will then continue routing. This allows the caller thread to not block and be able to service other messages, etc.
Sampling Throttler
Available as of Camel 2.1
A sampling throttler allows you to extract a sample of the exchanges from the traffic through a route.
It is configured with a sampling period during which only a single exchange is allowed to pass through. All other exchanges will be stopped.
Will by default use a sample period of 1 seconds.
Options
Name |
Default Value |
Description |
|---|---|---|
|
|
Samples the message every N'th message. You can only use either frequency or period. |
|
|
Samples the message every N'th period. You can only use either frequency or period. |
|
|
Time unit as an enum of |
Samples
You use this EIP with the sample DSL as show in these samples.
Using the Fluent Builders
These samples also show how you can use the different syntax to configure the sampling period:
Using the Spring XML Extensions
And the same example in Spring XML is:
And since it uses a default of 1 second you can omit this configuration in case you also want to use 1 second
See Also
Delayer
The Delayer Pattern allows you to delay the delivery of messages to some destination.
The expression is a value in millis to wait from the current time, so the expression should just be 3000.
However you can use a long value for a fixed value to indicate the delay in millis.
See the Spring DSL samples for Delayer.
See this ticket: https://issues.apache.org/jira/browse/CAMEL-2654
Options
Name |
Default Value |
Description |
|---|---|---|
|
|
Camel 2.4: If enabled then delayed messages happens asynchronously using a scheduled thread pool. |
|
|
Camel 2.4: Refers to a custom Thread Pool to be used if |
|
|
Camel 2.4: Is used if |
Using the Fluent Builders
The example below will delay all messages received on seda:b 1 second before sending them to mock:result.
You can just delay things a fixed amount of time from the point at which the delayer receives the message. For example to delay things 2 seconds
The above assume that the delivery order is maintained and that the messages are delivered in delay order. If you want to reorder the messages based on delivery time, you can use the Resequencer with this pattern. For example
You can of course use many different Expression languages such as XPath, XQuery, SQL or various Scripting Languages. For example to delay the message for the time period specified in the header, use the following syntax:
And to delay processing using the Simple language you can use the following DSL:
Spring DSL
The sample below demonstrates the delay in Spring DSL:
For further examples of this pattern in use you could look at the junit test case
Asynchronous delaying
Available as of Camel 2.4
You can let the Delayer use non blocking asynchronous delaying, which means Camel will use a scheduler to schedule a task to be executed in the future. The task will then continue routing. This allows the caller thread to not block and be able to service other messages etc.
From Java DSL
You use the asyncDelayed() to enable the async behavior.
From Spring XML
You use the asyncDelayed="true" attribute to enable the async behavior.
Creating a custom delay
You can use an expression to determine when to send a message using something like this
then the bean would look like this...
See Also
Load Balancer
The Load Balancer Pattern allows you to delegate to one of a number of endpoints using a variety of different load balancing policies.
Built-in load balancing policies
Camel provides the following policies out-of-the-box:
Policy | Description |
|---|---|
The exchanges are selected from in a round robin fashion. This is a well known and classic policy, which spreads the load evenly. | |
A random endpoint is selected for each exchange. | |
Sticky load balancing using an Expression to calculate a correlation key to perform the sticky load balancing; rather like jsessionid in the web or JMSXGroupID in JMS. | |
Topic which sends to all destinations (rather like JMS Topics) | |
In case of failures the exchange will be tried on the next endpoint. | |
Weighted Round-Robin | Camel 2.5: The weighted load balancing policy allows you to specify a processing load distribution ratio for each server with respect to the others. In addition to the weight, endpoint selection is then further refined using round-robin distribution based on weight. |
Weighted Random | Camel 2.5: The weighted load balancing policy allows you to specify a processing load distribution ratio for each server with respect to others.In addition to the weight, endpoint selection is then further refined using random distribution based on weight. |
Custom | Camel 2.8: From Camel 2.8 onwards the preferred way of using a custom Load Balancer is to use this policy, instead of using the @deprecated |
| Circuit Breaker | Camel 2.14: Implements the Circuit Breaker pattern as described in "Release it!" book. |
If you are proxying and load balancing HTTP, then see this page for more details.
Round Robin
The round robin load balancer is not meant to work with failover, for that you should use the dedicated failover load balancer. The round robin load balancer will only change to next endpoint per message.
The round robin load balancer is stateful as it keeps state of which endpoint to use next time.
Using the Fluent Builders
The above example loads balance requests from direct:start to one of the available mock endpoint instances, in this case using a round robin policy.
For further examples of this pattern look at this junit test case
Failover
The failover load balancer is capable of trying the next processor in case an Exchange failed with an exception during processing.
You can constrain the failover to activate only when one exception of a list you specify occurs. If you do not specify a list any exception will cause fail over to occur. This balancer uses the same strategy for matching exceptions as the Exception Clause does for the onException.
If you use streaming then you should enable Stream caching when using the failover load balancer. This is needed so the stream can be re-read after failing over to the next processor.
Failover offers the following options:
Option | Type | Default | Description |
|---|---|---|---|
inheritErrorHandler | boolean | true | Camel 2.3: Whether or not the Error Handler configured on the route should be used. Disable this if you want failover to transfer immediately to the next endpoint. On the other hand, if you have this option enabled, then Camel will first let the Error Handler try to process the message. The Error Handler may have been configured to redeliver and use delays between attempts. If you have enabled a number of redeliveries then Camel will try to redeliver to the same endpoint, and only fail over to the next endpoint, when the Error Handler is exhausted. |
maximumFailoverAttempts | int | -1 | Camel 2.3: A value to indicate after X failover attempts we should exhaust (give up). Use -1 to indicate never give up and continuously try to failover. Use 0 to never failover. And use e.g. 3 to failover at most 3 times before giving up. This option can be used whether or not roundRobin is enabled or not. |
roundRobin | boolean | false | Camel 2.3: Whether or not the |
| sticky | boolean | false | Camel 2.16: Whether or not the failover load balancer should operate in sticky mode or not. If not, then it will always start from the first endpoint when a new message is to be processed. In other words it restart from the top for every message. If sticky is enabled, then it keeps state and will continue with the last known good endpoint. You can also enable sticky mode together with round robin, if so then it will pick the last known good endpoint to use when starting the load balancing (instead of using the next when starting). |
Camel 2.2 or older behavior
The current implementation of failover load balancer uses simple logic which always tries the first endpoint, and in case of an exception being thrown it tries the next in the list, and so forth. It has no state, and the next message will thus always start with the first endpoint.
Camel 2.3 onwards behavior
The failover load balancer now supports round robin mode, which allows you to failover in a round robin fashion. See the roundRobin option.
In Camel 2.2 or older the failover load balancer requires you have enabled Camel Error Handler to use redelivery. In Camel 2.3 onwards this is not required as such, as you can mix and match. See the inheritErrorHandler option.
Here is a sample to failover only if a IOException related exception was thrown:
Using failover in Spring DSL
Failover can also be used from Spring DSL and you configure it as:
Using failover in round robin mode
An example using Java DSL:
You can configure inheritErrorHandler=false if you want to failover to the next endpoint as fast as possible. By disabling the Error Handler you ensure it does not intervene which allows the failover load balancer to handle failover asap. By also enabling roundRobin mode, then it will keep retrying until it success. You can then configure the maximumFailoverAttempts option to a high value to let it eventually exhaust (give up) and fail.
Weighted Round-Robin and Random Load Balancing
Available as of Camel 2.5
In many enterprise environments where server nodes of unequal processing power & performance characteristics are utilized to host services and processing endpoints, it is frequently necessary to distribute processing load based on their individual server capabilities so that some endpoints are not unfairly burdened with requests. Obviously simple round-robin or random load balancing do not alleviate problems of this nature. A Weighted Round-Robin and/or Weighted Random load balancer can be used to address this problem.
The weighted load balancing policy allows you to specify a processing load distribution ratio for each server with respect to others. You can specify this as a positive processing weight for each server. A larger number indicates that the server can handle a larger load. The weight is utilized to determine the payload distribution ratio to different processing endpoints with respect to others.
As of Camel 2.6, the Weighted Load balancer usage has been further simplified, there is no need to send in distributionRatio as a List<Integer>. It can be simply sent as a delimited String of integer weights separated by a delimiter of choice.
The parameters that can be used are
In Camel 2.5
Option | Type | Default | Description |
|---|---|---|---|
roundRobin | boolean | false | The default value for round-robin is false. In the absence of this setting or parameter the load balancing algorithm used is random. |
distributionRatio | List<Integer> | none | The distributionRatio is a list consisting on integer weights passed in as a parameter. The distributionRatio must match the number of endpoints and/or processors specified in the load balancer list. In Camel 2.5 if endpoints do not match ratios, then a best effort distribution is attempted. |
Available In Camel 2.6
Option | Type | Default | Description |
|---|---|---|---|
roundRobin | boolean | false | The default value for round-robin is false. In the absence of this setting or parameter the load balancing algorithm used is random. |
distributionRatio | String | none | The distributionRatio is a delimited String consisting on integer weights separated by delimiters for example "2,3,5". The distributionRatio must match the number of endpoints and/or processors specified in the load balancer list. |
distributionRatioDelimiter | String | , | The distributionRatioDelimiter is the delimiter used to specify the distributionRatio. If this attribute is not specified a default delimiter "," is expected as the delimiter used for specifying the distributionRatio. |
Using Weighted round-robin & random load balancing
In Camel 2.5
An example using Java DSL:
And the same example using Spring XML:
Available In Camel 2.6
An example using Java DSL:
And the same example using Spring XML:
Custom Load Balancer
You can use a custom load balancer (eg your own implementation) also.
An example using Java DSL:
To implement a custom load balancer you can extend some support classes such as LoadBalancerSupport and SimpleLoadBalancerSupport. The former supports the asynchronous routing engine, and the latter does not. Here is an example:
Circuit Breaker
The Circuit Breaker load balancer is a stateful pattern that monitors all calls for certain exceptions. Initially the Circuit Breaker is in closed state and passes all messages. If there are failures and the threshold is reached, it moves to open state and rejects all calls until halfOpenAfter timeout is reached. After this timeout is reached, if there is a new call, it will pass and if the result is success the Circuit Breaker will move to closed state, or to open state if there was an error.
When the circuit breaker is closed, it will throw a java.util.concurrent.RejectedExecutionException. This can then be caught to provide an alternate path for processing exchanges.
An example using Java DSL:
And the same example using Spring XML:
Multicast
The Multicast allows to route the same message to a number of endpoints and process them in a different way. The main difference between the Multicast and Splitter is that Splitter will split the message into several pieces but the Multicast will not modify the request message.
Options
Name | Default Value | Description | |
|---|---|---|---|
|
| Refers to an AggregationStrategy to be used to assemble the replies from the multicasts, into a single outgoing message from the Multicast. By default Camel will use the last reply as the outgoing message. From Camel 2.12 onwards you can also use a POJO as the | |
|
| Camel 2.12: This option can be used to explicit declare the method name to use, when using POJOs as the | |
|
| Camel 2.12: If this option is | |
|
| If enabled then sending messages to the multicasts occurs concurrently. Note the caller thread will still wait until all messages has been fully processed, before it continues. Its only the sending and processing the replies from the multicasts which happens concurrently. |
|
|
| Camel 2.14: If enabled then the | |
|
| Refers to a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatic implied, and you do not have to enable that option as well. | |
|
| Camel 2.2: Whether or not to stop continue processing immediately when an exception occurred. If disable, then Camel will send the message to all multicasts regardless if one of them failed. You can deal with exceptions in the AggregationStrategy class where you have full control how to handle that. | |
|
| If enabled then Camel will process replies out-of-order, eg in the order they come back. If disabled, Camel will process replies in the same order as multicasted. | |
|
| Camel 2.5: Sets a total timeout specified in millis. If the Multicast hasn't been able to send and process all replies within the given timeframe, then the timeout triggers and the Multicast breaks out and continues. Notice if you provide a TimeoutAwareAggregationStrategy then the | |
|
| Camel 2.8: Refers to a custom Processor to prepare the copy of the Exchange each multicast will receive. This allows you to do any custom logic, such as deep-cloning the message payload if that's needed etc. | |
|
| Camel 2.8: Whether the unit of work should be shared. See the same option on Splitter for more details. |
Example
The following example shows how to take a request from the direct:a endpoint , then multicast these request to direct:x, direct:y, direct:z.
Using the Fluent Builders
In case of using InOut MEP, an AggregationStrategy is used for aggregating all reply messages. The default is to only use the latest reply message and discard any earlier replies. The aggregation strategy is configurable:
Stop processing in case of exception
Available as of Camel 2.1
The Multicast will by default continue to process the entire Exchange even in case one of the multicasted messages will thrown an exception during routing.
For example if you want to multicast to 3 destinations and the 2nd destination fails by an exception. What Camel does by default is to process the remainder destinations. You have the chance to remedy or handle this in the AggregationStrategy.
But sometimes you just want Camel to stop and let the exception be propagated back, and let the Camel error handler handle it. You can do this in Camel 2.1 by specifying that it should stop in case of an exception occurred. This is done by the stopOnException option as shown below:
And using XML DSL you specify it as follows:
Using onPrepare to execute custom logic when preparing messages
Available as of Camel 2.8
The Multicast will copy the source Exchange and multicast each copy. However the copy is a shallow copy, so in case you have mutateable message bodies, then any changes will be visible by the other copied messages. If you want to use a deep clone copy then you need to use a custom onPrepare which allows you to do this using the Processor interface.
Notice the onPrepare can be used for any kind of custom logic which you would like to execute before the Exchange is being multicasted.
Its best practice to design for immutable objects.
For example if you have a mutable message body as this Animal class:onPrepare option as shown:onPrepare option is also available on other EIPs such as Splitter, Recipient List, and Wire Tap.
Loop
The Loop allows for processing a message a number of times, possibly in a different way for each iteration. Useful mostly during testing.
Notice by default the loop uses the same exchange throughout the looping. So the result from the previous iteration will be used for the next (eg Pipes and Filters). From Camel 2.8 onwards you can enable copy mode instead. See the options table for more details.
Options
Name | Default Value | Description |
|---|---|---|
|
| Camel 2.8: Whether or not copy mode is used. If |
| doWhile | Camel 2.17: Enables the while loop that loops until the predicate evaluates to false or null. |
Exchange properties
For each iteration two properties are set on the Exchange. Processors can rely on these properties to process the Message in different ways.
Property | Description |
|---|---|
| Total number of loops. This is not available if running the loop in while loop mode. |
| Index of the current iteration (0 based) |
Examples
The following example shows how to take a request from the direct:x endpoint, then send the message repetitively to mock:result. The number of times the message is sent is either passed as an argument to loop(), or determined at runtime by evaluating an expression. The expression must evaluate to an int, otherwise a RuntimeCamelException is thrown.
Using the Fluent Builders
Pass loop count as an argument
Pass loop count as an argument
Using copy mode
Available as of Camel 2.8
Now suppose we send a message to "direct:start" endpoint containing the letter A.
The output of processing this route will be that, each "mock:loop" endpoint will receive "AB" as message.
Using while mode
Available as of Camel 2.17
The loop can act like a while loop that loops until the expression evaluates to false or null.
For example the route below loops while the length of the message body is 5 or less characters. Notice that the DSL uses loopDoWhile.
And the same example in XML:
Notice in XML that the while loop is turned on using the doWhile attribute.
Message Transformation
Content Filter
Camel supports the Content Filter from the EIP patterns using one of the following mechanisms in the routing logic to transform content from the inbound message.
- Message Translator
- invoking a Java bean
- Processor object
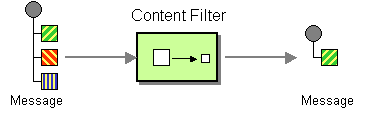
A common way to filter messages is to use an Expression in the DSL like XQuery, SQL or one of the supported Scripting Languages.
Using the Fluent Builders
Here is a simple example using the DSL directly
Error formatting macro: snippet: java.lang.NullPointerException
In this example we add our own Processor
Error formatting macro: snippet: java.lang.NullPointerException
For further examples of this pattern in use you could look at one of the JUnit tests
Using Spring XML
<route> <from uri="activemq:Input"/> <bean ref="myBeanName" method="doTransform"/> <to uri="activemq:Output"/> </route>
You can also use XPath to filter out part of the message you are interested in:
<route> <from uri="activemq:Input"/> <setBody><xpath resultType="org.w3c.dom.Document">//foo:bar</xpath></setBody> <to uri="activemq:Output"/> </route>
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Claim Check
The Claim Check from the EIP patterns allows you to replace message content with a claim check (a unique key), which can be used to retrieve the message content at a later time. The message content is stored temporarily in a persistent store like a database or file system. This pattern is very useful when message content is very large (thus it would be expensive to send around) and not all components require all information.
It can also be useful in situations where you cannot trust the information with an outside party; in this case, you can use the Claim Check to hide the sensitive portions of data.
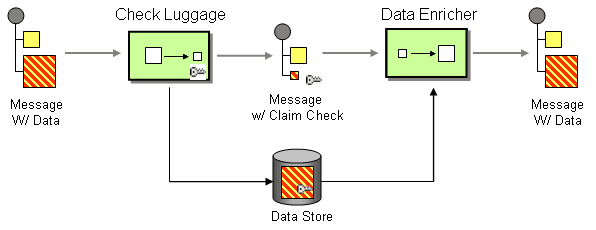
Example
In this example we want to replace a message body with a claim check, and restore the body at a later step.
Using the Fluent Builders
Using the Spring XML Extensions
The example route is pretty simple - its just a Pipeline. In a real application you would have some other steps where the mock:testCheckpoint endpoint is in the example.
The message is first sent to the checkLuggage bean which looks like
This bean stores the message body into the data store, using the custId as the claim check. In this example, we're just using a HashMap to store the message body; in a real application you would use a database or file system, etc. Next the claim check is added as a message header for use later. Finally we remove the body from the message and pass it down the pipeline.
The next step in the pipeline is the mock:testCheckpoint endpoint which is just used to check that the message body is removed, claim check added, etc.
To add the message body back into the message, we use the dataEnricher bean which looks like
This bean queries the data store using the claim check as the key and then adds the data back into the message. The message body is then removed from the data store and finally the claim check is removed. Now the message is back to what we started with!
For full details, check the example source here:
camel-core/src/test/java/org/apache/camel/processor/ClaimCheckTest.java
Normalizer
Camel supports the Normalizer from the EIP patterns by using a Message Router in front of a number of Message Translator instances.
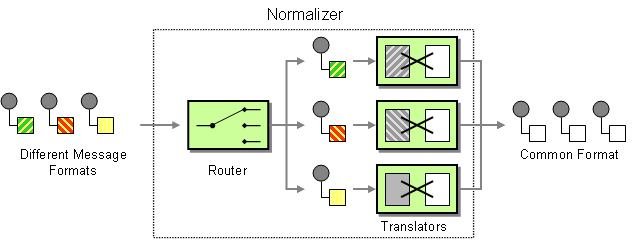
Example
This example shows a Message Normalizer that converts two types of XML messages into a common format. Messages in this common format are then filtered.
Using the Fluent Builders
In this case we're using a Java bean as the normalizer. The class looks like this
Using the Spring XML Extensions
The same example in the Spring DSL
See Also
Sort
Sort can be used to sort a message. Imagine you consume text files and before processing each file you want to be sure the content is sorted.
Sort will by default sort the body using a default comparator that handles numeric values or uses the string representation. You can provide your own comparator, and even an expression to return the value to be sorted. Sort requires the value returned from the expression evaluation is convertible to java.util.List as this is required by the JDK sort operation.
Options
Name |
Default Value |
Description |
|---|---|---|
|
|
Refers to a custom |
Using from Java DSL
In the route below it will read the file content and tokenize by line breaks so each line can be sorted.
from("file://inbox").sort(body().tokenize("\n")).to("bean:MyServiceBean.processLine");
You can pass in your own comparator as a 2nd argument:
from("file://inbox").sort(body().tokenize("\n"), new MyReverseComparator()).to("bean:MyServiceBean.processLine");
Using from Spring DSL
In the route below it will read the file content and tokenize by line breaks so each line can be sorted.
Camel 2.7 or better
<route>
<from uri="file://inbox"/>
<sort>
<simple>body</simple>
</sort>
<beanRef ref="myServiceBean" method="processLine"/>
</route>
Camel 2.6 or older
<route>
<from uri="file://inbox"/>
<sort>
<expression>
<simple>body</simple>
</expression>
</sort>
<beanRef ref="myServiceBean" method="processLine"/>
</route>
And to use our own comparator we can refer to it as a spring bean:
Camel 2.7 or better
<route>
<from uri="file://inbox"/>
<sort comparatorRef="myReverseComparator">
<simple>body</simple>
</sort>
<beanRef ref="MyServiceBean" method="processLine"/>
</route>
<bean id="myReverseComparator" class="com.mycompany.MyReverseComparator"/>
Camel 2.6 or older
<route>
<from uri="file://inbox"/>
<sort comparatorRef="myReverseComparator">
<expression>
<simple>body</simple>
</expression>
</sort>
<beanRef ref="MyServiceBean" method="processLine"/>
</route>
<bean id="myReverseComparator" class="com.mycompany.MyReverseComparator"/>
Besides <simple>, you can supply an expression using any language you like, so long as it returns a list.
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Messaging Endpoints
Messaging Mapper
Camel supports the Messaging Mapper from the EIP patterns by using either Message Translator pattern or the Type Converter module.

Example
The following example demonstrates the use of a Bean component to map between two messaging system
Using the Fluent Builders
from("activemq:foo")
.beanRef("transformerBean", "transform")
.to("jms:bar");
Using the Spring XML Extensions
<route> <from uri="activemq:foo"/> <bean ref="transformerBean" method="transform" /> <to uri="jms:bar"/> </route>
See also
- Message Translator
- Type Converter
- CXF for JAX-WS support for binding business logic to messaging & web services
- Pojo
- Bean
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Event Driven Consumer
Camel supports the Event Driven Consumer from the EIP patterns. The default consumer model is event based (i.e. asynchronous) as this means that the Camel container can then manage pooling, threading and concurrency for you in a declarative manner.
The Event Driven Consumer is implemented by consumers implementing the Processor interface which is invoked by the Message Endpoint when a Message is available for processing.
Example
The following demonstrates a Processor defined in the Camel Registry which is invoked when an event occurs from a JMS queue
Using the Fluent Builders
from("jms:queue:foo")
.processRef("processor");
Using the Spring XML Extensions
<route> <from uri="jms:queue:foo"/> <to uri="processor"/> </route>
For more details see
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Polling Consumer
Camel supports implementing the Polling Consumer from the EIP patterns using the PollingConsumer interface which can be created via the Endpoint.createPollingConsumer() method.
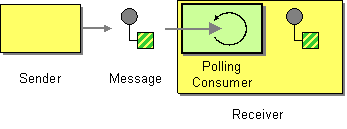
In Java:
The ConsumerTemplate (discussed below) is also available.
There are three main polling methods on PollingConsumer
Method name | Description |
|---|---|
Waits until a message is available and then returns it; potentially blocking forever | |
Attempts to receive a message exchange, waiting up to the given timeout and returning null if no message exchange could be received within the time available | |
Attempts to receive a message exchange immediately without waiting and returning null if a message exchange is not available yet |
EventDrivenPollingConsumer Options
The EventDrivePollingConsumer (the default implementation) supports the following options:
Option | Default | Description |
|---|---|---|
|
| Camel 2.14/2.13.1/2.12.4: The queue size for the internal hand-off queue between the polling consumer, and producers sending data into the queue. |
|
| Camel 2.14/2.13.1/2.12/4: Whether to block any producer if the internal queue is full. |
pollingConsumerBlockTimeout | 0 | Camel 2.16: To use a timeout (in milliseconds) when the producer is blocked if the internal queue is full. If the value is 0 or negative then no timeout is in use. If a timeout is triggered then a ExchangeTimedOutException is thrown. |
Notice that some Camel Components has their own implementation of PollingConsumer and therefore do not support the options above.
You can configure these options in endpoints URIs, such as shown below:
ConsumerTemplate
The ConsumerTemplate is a template much like Spring's JmsTemplate or JdbcTemplate supporting the Polling Consumer EIP. With the template you can consume Exchanges from an Endpoint. The template supports the three operations listed above. However, it also includes convenient methods for returning the body, etc consumeBody.
Example:
Or to extract and get the body you can do:
And you can provide the body type as a parameter and have it returned as the type:
You get hold of a ConsumerTemplate from the CamelContext with the createConsumerTemplate operation:
Using ConsumerTemplate with Spring DSL
With the Spring DSL we can declare the consumer in the CamelContext with the consumerTemplate tag, just like the ProducerTemplate. The example below illustrates this:ConsumerTemplate in our java class. The code below is part of an unit test but it shows how the consumer and producer can work together.
Timer Based Polling Consumer
In this sample we use a Timer to schedule a route to be started every 5th second and invoke our bean MyCoolBean where we implement the business logic for the Polling Consumer. Here we want to consume all messages from a JMS queue, process the message and send them to the next queue.
First we setup our route as:
Scheduled Poll Components
Quite a few inbound Camel endpoints use a scheduled poll pattern to receive messages and push them through the Camel processing routes. That is to say externally from the client the endpoint appears to use an Event Driven Consumer but internally a scheduled poll is used to monitor some kind of state or resource and then fire message exchanges.
Since this a such a common pattern, polling components can extend the ScheduledPollConsumer base class which makes it simpler to implement this pattern. There is also the Quartz Component which provides scheduled delivery of messages using the Quartz enterprise scheduler.
For more details see:
- PollingConsumer
- Scheduled Polling Components
ScheduledPollConsumer Options
The ScheduledPollConsumer supports the following options:
Option | Default | Description |
|---|---|---|
|
| Camel 2.12: The number of subsequent error polls (failed due some error) that should happen before the |
|
| Camel 2.12: The number of subsequent idle polls that should happen before the |
|
| Camel 2.12: To let the scheduled polling consumer back-off if there has been a number of subsequent idles/errors in a row. The multiplier is then the number of polls that will be skipped before the next actual attempt is happening again. When this option is in use then |
|
| Milliseconds before the next poll. |
|
| Camel 2.10.6/2.11.1: If greedy is enabled, then the |
|
| Milliseconds before the first poll starts. |
| A pluggable The default implementation will log the caused exception at | |
|
| Camel 2.8: The consumer logs a start/complete log line when it polls. This option allows you to configure the logging level for that. |
|
| Camel 2.10: Allows for configuring a custom/shared thread pool to use for the consumer. By default each consumer has its own single threaded thread pool. This option allows you to share a thread pool among multiple consumers. |
|
| Camel 2.12: Allow to plugin a custom See Quartz2 page for an example. |
|
| Camel 2.12: To configure additional properties when using a custom |
|
| Camel 2.9: If the polling consumer did not poll any files, you can enable this option to send an empty message (no body) instead. |
|
| Whether the scheduler should be auto started. |
|
| Time unit for |
|
| Controls if fixed delay or fixed rate is used. See ScheduledExecutorService in JDK for details. In Camel 2.7.x or older the default value is From Camel 2.8: the default value is |
Using backoff to Let the Scheduler be Less Aggressive
Available as of Camel 2.12
The scheduled Polling Consumer is by default static by using the same poll frequency whether or not there is messages to pickup or not.
From Camel 2.12: you can configure the scheduled Polling Consumer to be more dynamic by using backoff. This allows the scheduler to skip N number of polls when it becomes idle, or there has been X number of errors in a row. See more details in the table above for the backoffXXX options.
For example to let a FTP consumer back-off if its becoming idle for a while you can do:
In this example, the FTP consumer will poll for new FTP files every 5th second. But if it has been idle for 5 attempts in a row, then it will back-off using a multiplier of 6, which means it will now poll every 5 x 6 = 30th second instead. When the consumer eventually pickup a file, then the back-off will reset, and the consumer will go back and poll every 5th second again.
Camel will log at DEBUG level using org.apache.camel.impl.ScheduledPollConsumer when back-off is kicking-in.
About Error Handling and Scheduled Polling Consumers
ScheduledPollConsumer is scheduled based and its run method is invoked periodically based on schedule settings. But errors can also occur when a poll is being executed. For instance if Camel should poll a file network, and this network resource is not available then a java.io.IOException could occur. As this error happens before any Exchange has been created and prepared for routing, then the regular Error handling in Camel does not apply. So what does the consumer do then? Well the exception is propagated back to the run method where its handled. Camel will by default log the exception at WARN level and then ignore it. At next schedule the error could have been resolved and thus being able to poll the endpoint successfully.
Using a Custom Scheduler
Available as of Camel 2.12:
The SPI interface org.apache.camel.spi.ScheduledPollConsumerScheduler allows to implement a custom scheduler to control when the Polling Consumer runs. The default implementation is based on the JDKs ScheduledExecutorService with a single thread in the thread pool. There is a CRON based implementation in the Quartz2, and Spring components.
For an example of developing and using a custom scheduler, see the unit test org.apache.camel.component.file.FileConsumerCustomSchedulerTest from the source code in camel-core.
Error Handling When Using PollingConsumerPollStrategy
org.apache.camel.PollingConsumerPollStrategy is a pluggable strategy that you can configure on the ScheduledPollConsumer. The default implementation org.apache.camel.impl.DefaultPollingConsumerPollStrategy will log the caused exception at WARN level and then ignore this issue.
The strategy interface provides the following three methods:
beginvoid begin(Consumer consumer, Endpoint endpoint)
begin(Camel 2.3)boolean begin(Consumer consumer, Endpoint endpoint)
commitvoid commit(Consumer consumer, Endpoint endpoint)
commit(Camel 2.6)void commit(Consumer consumer, Endpoint endpoint, int polledMessages)
rollbackboolean rollback(Consumer consumer, Endpoint endpoint, int retryCounter, Exception e) throws Exception
In Camel 2.3: the begin method returns a boolean which indicates whether or not to skipping polling. So you can implement your custom logic and return false if you do not want to poll this time.
In Camel 2.6: the commit method has an additional parameter containing the number of message that was actually polled. For example if there was no messages polled, the value would be zero, and you can react accordingly.
The most interesting is the rollback as it allows you do handle the caused exception and decide what to do.
For instance if we want to provide a retry feature to a scheduled consumer we can implement the PollingConsumerPollStrategy method and put the retry logic in the rollback method. Lets just retry up till three times:
Notice that we are given the Consumer as a parameter. We could use this to restart the consumer as we can invoke stop and start:
Note: if you implement the begin operation make sure to avoid throwing exceptions as in such a case the poll operation is not invoked and Camel will invoke the rollback directly.
Configuring an Endpoint to Use PollingConsumerPollStrategy
To configure an Endpoint to use a custom PollingConsumerPollStrategy you use the option pollStrategy. For example in the file consumer below we want to use our custom strategy defined in the Registry with the bean id myPoll:
See Also
Competing Consumers
Camel supports the Competing Consumers from the EIP patterns using a few different components.
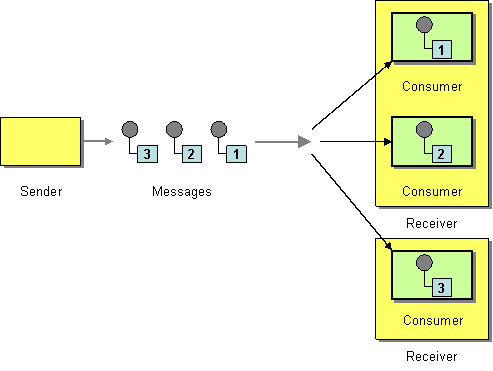
You can use the following components to implement competing consumers:-
- Seda for SEDA based concurrent processing using a thread pool
- JMS for distributed SEDA based concurrent processing with queues which support reliable load balancing, failover and clustering.
Enabling Competing Consumers with JMS
To enable Competing Consumers you just need to set the concurrentConsumers property on the JMS endpoint.
For example
from("jms:MyQueue?concurrentConsumers=5").bean(SomeBean.class);
or in Spring DSL
<route> <from uri="jms:MyQueue?concurrentConsumers=5"/> <to uri="bean:someBean"/> </route>
Or just run multiple JVMs of any ActiveMQ or JMS route ![]()
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Message Dispatcher
Camel supports the Message Dispatcher from the EIP patterns using various approaches.
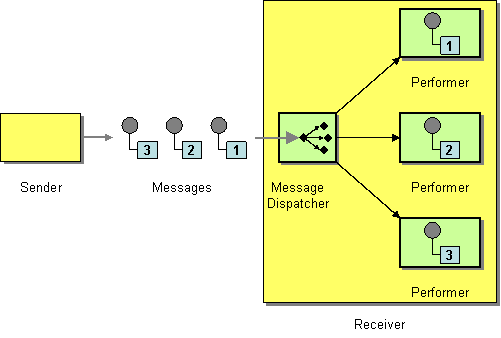
You can use a component like JMS with selectors to implement a Selective Consumer as the Message Dispatcher implementation. Or you can use an Endpoint as the Message Dispatcher itself and then use a Content Based Router as the Message Dispatcher.
Example
The following example demonstrates Message Dispatcher pattern using the Competing Consumers functionality of the JMS component to offload messages to a Content Based Router and custom Processors registered in the Camel Registry running in separate threads from originating consumer.
Using the Fluent Builders
from("jms:queue:foo?concurrentConsumers=5")
.threads(5)
.choice()
.when(header("type").isEqualTo("A"))
.processRef("messageDispatchProcessorA")
.when(header("type").isEqualTo("B"))
.processRef("messageDispatchProcessorB")
.when(header("type").isEqualTo("C"))
.processRef("messageDispatchProcessorC")
.otherwise()
.to("jms:queue:invalidMessageType");
Using the Spring XML Extensions
<route>
<from uri="jms:queue:foo?concurrentConsumers=5"/>
<threads poolSize="5">
<choice>
<when>
<simple>${in.header.type} == 'A'</simple>
<to ref="messageDispatchProcessorA"/>
</when>
<when>
<simple>${in.header.type} == 'B'</simple>
<to ref="messageDispatchProcessorB"/>
</when>
<when>
<simple>${in.header.type} == 'C'</simple>
<to ref="messageDispatchProcessorC"/>
</when>
<otherwise>
<to uri="jms:queue:invalidMessageType"/>
</choice>
</threads>
</route>
See Also
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Selective Consumer
The Selective Consumer from the EIP patterns can be implemented in two ways
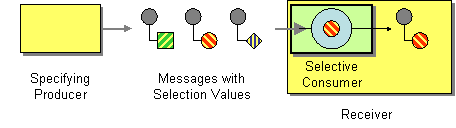
The first solution is to provide a Message Selector to the underlying URIs when creating your consumer. For example when using JMS you can specify a selector parameter so that the message broker will only deliver messages matching your criteria.
The other approach is to use a Message Filter which is applied; then if the filter matches the message your consumer is invoked as shown in the following example
Using the Fluent Builders
Error formatting macro: snippet: java.lang.NullPointerException
Using the Spring XML Extensions
Error formatting macro: snippet: java.lang.NullPointerException
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Durable Subscriber
Camel supports the Durable Subscriber from the EIP patterns using the JMS component which supports publish & subscribe using Topics with support for non-durable and durable subscribers.
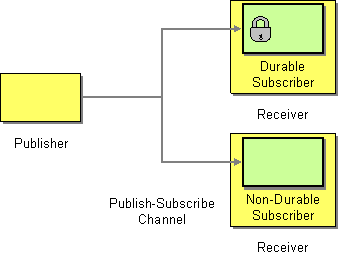
Another alternative is to combine the Message Dispatcher or Content Based Router with File or JPA components for durable subscribers then something like Seda for non-durable.
Here is a simple example of creating durable subscribers to a JMS topic
Using the Fluent Builders
from("direct:start").to("activemq:topic:foo");
from("activemq:topic:foo?clientId=1&durableSubscriptionName=bar1").to("mock:result1");
from("activemq:topic:foo?clientId=2&durableSubscriptionName=bar2").to("mock:result2");
Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:topic:foo"/>
</route>
<route>
<from uri="activemq:topic:foo?clientId=1&durableSubscriptionName=bar1"/>
<to uri="mock:result1"/>
</route>
<route>
<from uri="activemq:topic:foo?clientId=2&durableSubscriptionName=bar2"/>
<to uri="mock:result2"/>
</route>
Here is another example of JMS durable subscribers, but this time using virtual topics (recommended by AMQ over durable subscriptions)
Using the Fluent Builders
from("direct:start").to("activemq:topic:VirtualTopic.foo");
from("activemq:queue:Consumer.1.VirtualTopic.foo").to("mock:result1");
from("activemq:queue:Consumer.2.VirtualTopic.foo").to("mock:result2");
Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<to uri="activemq:topic:VirtualTopic.foo"/>
</route>
<route>
<from uri="activemq:queue:Consumer.1.VirtualTopic.foo"/>
<to uri="mock:result1"/>
</route>
<route>
<from uri="activemq:queue:Consumer.2.VirtualTopic.foo"/>
<to uri="mock:result2"/>
</route>
See Also
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Idempotent Consumer
The Idempotent Consumer from the EIP patterns is used to filter out duplicate messages.
This pattern is implemented using the IdempotentConsumer class. This uses an Expression to calculate a unique message ID string for a given message exchange; this ID can then be looked up in the IdempotentRepository to see if it has been seen before; if it has the message is consumed; if its not then the message is processed and the ID is added to the repository.
The Idempotent Consumer essentially acts like a Message Filter to filter out duplicates.
Camel will add the message id eagerly to the repository to detect duplication also for Exchanges currently in progress.
On completion Camel will remove the message id from the repository if the Exchange failed, otherwise it stays there.
Camel provides the following Idempotent Consumer implementations:
- MemoryIdempotentRepository
- FileIdempotentRepository
- HazelcastIdempotentRepository (Available as of Camel 2.8)
- JdbcMessageIdRepository (Available as of Camel 2.7)
- JpaMessageIdRepository
InfinispanIdempotentRepository (Available as of Camel 2.13.0)
JCacheIdempotentRepository (Available as of Camel 2.17.0)
SpringCacheIdempotentRepository (Available as of Camel 2.17.1)
EhcacheIdempotentRepository (Available as of Camel 2.18.0)
- KafkaIdempotentRepository (Available as of Camel 2.19.0)
Options
The Idempotent Consumer has the following options:
Option | Default | Description |
|---|---|---|
eager | true | Eager controls whether Camel adds the message to the repository before or after the exchange has been processed. If enabled before then Camel will be able to detect duplicate messages even when messages are currently in progress. By disabling Camel will only detect duplicates when a message has successfully been processed. |
messageIdRepositoryRef |
| A reference to a |
skipDuplicate | true | Camel 2.8: Sets whether to skip duplicate messages. If set to |
removeOnFailure | true | Camel 2.9: Sets whether to remove the id of an Exchange that failed. |
| completionEager | false | Camel 2.16: Sets whether to complete the idempotent consumer eager or when the exchange is done. If this option is true to complete eager, then the idempotent consumer will trigger its completion when the exchange reached the end of the block of the idempotent consumer pattern. So if the exchange is continued routed after the block ends, then whatever happens there does not affect the state. If this option is false (default) to not complete eager, then the idempotent consumer will complete when the exchange is done being routed. So if the exchange is continued routed after the block ends, then whatever happens there also affect the state. For example if the exchange failed due to an exception, then the state of the idempotent consumer will be a rollback. |
Using the Fluent Builders
The following example will use the header myMessageId to filter out duplicates
For further examples of this pattern in use you could look at the junit test case
Spring XML example
The following example will use the header myMessageId to filter out duplicates
How to handle duplicate messages in the route
Available as of Camel 2.8
You can now set the skipDuplicate option to false which instructs the idempotent consumer to route duplicate messages as well. However the duplicate message has been marked as duplicate by having a property on the Exchange set to true. We can leverage this fact by using a Content Based Router or Message Filter to detect this and handle duplicate messages.
For example in the following example we use the Message Filter to send the message to a duplicate endpoint, and then stop continue routing that message.
How to handle duplicate message in a clustered environment with a data grid
Available as of Camel 2.8
If you have running Camel in a clustered environment, a in memory idempotent repository doesn't work (see above). You can setup either a central database or use the idempotent consumer implementation based on the Hazelcast data grid. Hazelcast finds the nodes over multicast (which is default - configure Hazelcast for tcp-ip) and creates automatically a map based repository:
You have to define how long the repository should hold each message id (default is to delete it never). To avoid that you run out of memory you should create an eviction strategy based on the Hazelcast configuration. For additional information see camel-hazelcast.
See this little tutorial, how setup such an idempotent repository on two cluster nodes using Apache Karaf.
Available as of Camel 2.13.0
Another option for using Idempotent Consumer in a clustered environment is Infinispan. Infinispan is a data grid with replication and distribution clustering support. For additional information see camel-infinispan.
Transactional Client
Camel recommends supporting the Transactional Client from the EIP patterns using spring transactions.
![]()
Transaction Oriented Endpoints like JMS support using a transaction for both inbound and outbound message exchanges. Endpoints that support transactions will participate in the current transaction context that they are called from.
The redelivery in transacted mode is not handled by Camel but by the backing system (the transaction manager). In such cases you should resort to the backing system how to configure the redelivery.
You should use the SpringRouteBuilder to setup the routes since you will need to setup the spring context with the TransactionTemplates that will define the transaction manager configuration and policies.
For inbound endpoint to be transacted, they normally need to be configured to use a Spring PlatformTransactionManager. In the case of the JMS component, this can be done by looking it up in the spring context.
You first define needed object in the spring configuration.
Then you look them up and use them to create the JmsComponent.
Transaction Policies
Outbound endpoints will automatically enlist in the current transaction context. But what if you do not want your outbound endpoint to enlist in the same transaction as your inbound endpoint? The solution is to add a Transaction Policy to the processing route. You first have to define transaction policies that you will be using. The policies use a spring TransactionTemplate under the covers for declaring the transaction demarcation to use. So you will need to add something like the following to your spring xml:
Then in your SpringRouteBuilder, you just need to create new SpringTransactionPolicy objects for each of the templates.
Once created, you can use the Policy objects in your processing routes:
OSGi Blueprint
If you are using OSGi Blueprint then you most likely have to explicit declare a policy and refer to the policy from the transacted in the route.
And then refer to "required" from the route:
Database Sample
In this sample we want to ensure that two endpoints is under transaction control. These two endpoints inserts data into a database.
The sample is in its full as a unit test.
First of all we setup the usual spring stuff in its configuration file. Here we have defined a DataSource to the HSQLDB and a most importantly the Spring DataSource TransactionManager that is doing the heavy lifting of ensuring our transactional policies. You are of course free to use any of the Spring based TransactionManager, eg. if you are in a full blown J2EE container you could use JTA or the WebLogic or WebSphere specific managers.
As we use the new convention over configuration we do not need to configure a transaction policy bean, so we do not have any PROPAGATION_REQUIRED beans. All the beans needed to be configured is standard Spring beans only, eg. there are no Camel specific configuration at all.
This is after all based on a unit test. Notice that we mark each route as transacted using the transacted tag.
JMS Sample
In this sample we want to listen for messages on a queue and process the messages with our business logic java code and send them along. Since its based on a unit test the destination is a mock endpoint.
First we configure the standard Spring XML to declare a JMS connection factory, a JMS transaction manager and our ActiveMQ component that we use in our routing.
When a route is marked as transacted using transacted Camel will automatic use the TransactionErrorHandler as Error Handler. It supports basically the same feature set as the DefaultErrorHandler, so you can for instance use Exception Clause as well.
Integration Testing with Spring
An Integration Test here means a test runner class annotated @RunWith(SpringJUnit4ClassRunner.class).
When following the Spring Transactions documentation it is tempting to annotate your integration test with @Transactional then seed your database before firing up the route to be tested and sending a message in. This is incorrect as Spring will have an in-progress transaction, and Camel will wait on this before proceeding, leading to the route timing out.
Instead, remove the @Transactional annotation from the test method and seed the test data within a TransactionTemplate execution which will ensure the data is committed to the database before Camel attempts to pick up and use the transaction manager. A simple example can be found on GitHub.
Spring's transactional model ensures each transaction is bound to one thread. A Camel route may invoke additional threads which is where the blockage may occur. This is not a fault of Camel but as the programmer you must be aware of the consequences of beginning a transaction in a test thread and expecting a separate thread created by your Camel route to be participate, which it cannot. You can, in your test, mock the parts that cause separate threads to avoid this issue.
Using multiple routes with different propagation behaviors
Available as of Camel 2.2
Suppose you want to route a message through two routes and by which the 2nd route should run in its own transaction. How do you do that? You use propagation behaviors for that where you configure it as follows:
- The first route use
PROPAGATION_REQUIRED - The second route use
PROPAGATION_REQUIRES_NEW
This is configured in the Spring XML file:onException in the 2nd route to indicate in case of any exceptions we should handle it and just rollback this transaction. This is done using the markRollbackOnlyLast which tells Camel to only do it for the current transaction and not globally.
See Also
Messaging Gateway
Camel has several endpoint components that support the Messaging Gateway from the EIP patterns.
Components like Bean and CXF provide a a way to bind a Java interface to the message exchange.
However you may want to read the Using CamelProxy documentation as a true Messaging Gateway EIP solution.
Another approach is to use @Produce which you can read about in POJO Producing which also can be used as a Messaging Gateway EIP solution.
Example
The following example how the CXF and Bean components can be used to abstract the developer from the underlying messaging system API
Using the Fluent Builders
from("cxf:bean:soapMessageEndpoint")
.to("bean:testBean?method=processSOAP");
Using the Spring XML Extensions
<route> <from uri="cxf:bean:soapMessageEndpoint"/> <to uri="bean:testBean?method=processSOAP"/> </route>
See Also
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Service Activator
Camel has several endpoint components that support the Service Activator from the EIP patterns.
Components like Bean, CXF and Pojo provide a a way to bind the message exchange to a Java interface/service where the route defines the endpoints and wires it up to the bean.
In addition you can use the Bean Integration to wire messages to a bean using annotation.
Here is a simple example of using a Direct endpoint to create a messaging interface to a Pojo Bean service.
Using the Fluent Builders
from("direct:invokeMyService").to("bean:myService");
Using the Spring XML Extensions
<route>
<from uri="direct:invokeMyService"/>
<to uri="bean:myService"/>
</route>
See Also
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
System Management
Detour
The Detour from the EIP patterns allows you to send messages through additional steps if a control condition is met. It can be useful for turning on extra validation, testing, debugging code when needed.

Example
In this example we essentially have a route like from("direct:start").to("mock:result") with a conditional detour to the mock:detour endpoint in the middle of the route..
Error formatting macro: snippet: java.lang.NullPointerException
Using the Spring XML Extensions
<route>
<from uri="direct:start"/>
<choice>
<when>
<method bean="controlBean" method="isDetour"/>
<to uri="mock:detour"/>
</when>
</choice>
<to uri="mock:result"/>
</route>
whether the detour is turned on or off is decided by the ControlBean. So, when the detour is on the message is routed to mock:detour and then mock:result. When the detour is off, the message is routed to mock:result.
For full details, check the example source here:
camel-core/src/test/java/org/apache/camel/processor/DetourTest.java
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.
Wire Tap
Wire Tap (from the EIP patterns) allows you to route messages to a separate location while they are being forwarded to the ultimate destination.
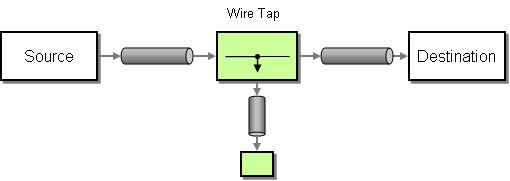
If you Wire Tap a stream message body then you should consider enabling Stream caching to ensure the message body can be read at each endpoint. See more details at Stream caching.
Options
| Name | Default | Description |
|---|---|---|
|
| Mandatory: The URI of the endpoint to which the wire-tapped message should be sent. From Camel 2.16: support for dynamic |
|
| Reference ID of a custom Thread Pool to use when processing the wire-tapped messages. When not set, Camel will use an instance of the default thread pool. |
|
| Reference ID of a custom Processor to use for creating a new message. See "Sending a New Exchange" below. |
|
| Camel 2.3: Whether to copy the Exchange before wire-tapping the message. |
|
| Camel 2.8: Reference identifier of a custom Processor to prepare the copy of the Exchange to be wire-tapped. This allows you to do any custom logic, such as deep-cloning the message payload. |
| Camel 2.16: Allows to configure the cache size for the Setting the value to | |
|
| Camel 2.16: Whether to ignore an endpoint URI that could not be resolved. When |
WireTap Threadpool
The Wire Tap uses a thread pool to process the tapped messages. This thread pool will by default use the settings detailed at Threading Model. In particular, when the pool is exhausted (with all threads utilized), further wiretaps will be executed synchronously by the calling thread. To remedy this, you can configure an explicit thread pool on the Wire Tap having either a different rejection policy, a larger worker queue, or more worker threads.
WireTap Node
Camel's Wire Tap node supports two flavors when tapping an Exchange:
- With the traditional Wire Tap, Camel will copy the original Exchange and set its Exchange Pattern to
InOnly, as we want the tapped Exchange to be sent in a fire and forget style. The tapped Exchange is then sent in a separate thread so it can run in parallel with the original. Beware that only the Exchange is copied - Wire Tap won't do a deep clone (unless you specify a custom processor viaonPrepareRefwhich does that). So all copies could share objects from the original Exchange. - Camel also provides an option of sending a new Exchange allowing you to populate it with new values.
Sending a Copy (traditional wiretap)
Using the Fluent Builders
Sending a New Exchange
Using the Fluent Builders
Camel supports either a processor or an Expression to populate the new Exchange. Using a processor gives you full power over how the Exchange is populated as you can set properties, headers, etc. An Expression can only be used to set the IN body.
From Camel 2.3: the Expression or Processor is pre-populated with a copy of the original Exchange, which allows you to access the original message when you prepare a new Exchange to be sent. You can use the copy option (enabled by default) to indicate whether you want this. If you set copy=false, then it works as in Camel 2.2 or older where the Exchange will be empty.
Below is the processor variation. This example is from Camel 2.3, where we disable copy by passing in false to create a new, empty Exchange.copy=false which results in the creation of a new, empty Exchange.
The processor variation, which uses a processorRef attribute to refer to a Spring bean by ID:body tag:"Bye ORIGINAL BODY MESSAGE HERE"
Further Example
For another example of this pattern, refer to the wire tap test case.
Using Dynamic URIs
Available as of Camel 2.16:
For example to wire tap to a dynamic URI, then it supports the same dynamic URIs as documented in Message Endpoint. For example to wire tap to a JMS queue where the header ID is part of the queue name:
Sending a New Exchange and Set Headers in DSL
Available as of Camel 2.8
If you send a new message using Wire Tap, then you could only set the message body using an Expression from the DSL. If you also need to set headers, you would have to use a Processor. From Camel 2.8: it's possible to set headers as well using the DSL.
The following example sends a new message which has
Bye Worldas message body.- A header with key
idwith the value123. - A header with key
datewhich has current date as value.
Java DSL
XML DSL
The XML DSL is slightly different than Java DSL in how you configure the message body and headers using <body> and <setHeader>:
Using onPrepare to Execute Custom Logic when Preparing Messages
Available as of Camel 2.8
See details at Multicast
Log
How can I log the processing of a Message?
Camel provides many ways to log the fact that you are processing a message. Here are just a few examples:
- You can use the Log component which logs the Message content.
- You can use the Tracer which trace logs message flow.
- You can also use a Processor or Bean and log from Java code.
- You can use the
logDSL.
Using log DSL
In Camel 2.2 you can use the log DSL which allows you to use Simple language to construct a dynamic message which gets logged.
For example you can do
from("direct:start").log("Processing ${id}").to("bean:foo");
Which will construct a String message at runtime using the Simple language. The log message will by logged at INFO level using the route id as the log name. By default a route is named route-1, route-2 etc. But you can use the routeId("myCoolRoute") to set a route name of choice.
Difference between log in the DSL and [Log] component
The log DSL is much lighter and meant for logging human logs such as Starting to do ... etc. It can only log a message based on the Simple language. On the other hand Log component is a full fledged component which involves using endpoints and etc. The Log component is meant for logging the Message itself and you have many URI options to control what you would like to be logged.
Using Logger instance from the the Registry
As of Camel 2.12.4/2.13.1, if no logger name or logger instance is passed to log DSL, there is a Registry lookup performed to find single instance of org.slf4j.Logger. If such an instance is found, it is used instead of creating a new logger instance. If more instances are found, the behavior defaults to creating a new instance of logger.
Logging message body with streamed messages
If the message body is stream based, then logging the message body, may cause the message body to be empty afterwards. See this FAQ. For streamed messages you can use Stream caching to allow logging the message body and be able to read the message body afterwards again.
The log DSL have overloaded methods to set the logging level and/or name as well.
from("direct:start").log(LoggingLevel.DEBUG, "Processing ${id}").to("bean:foo");
and to set a logger name
from("direct:start").log(LoggingLevel.DEBUG, "com.mycompany.MyCoolRoute", "Processing ${id}").to("bean:foo");
Since Camel 2.12.4/2.13.1 the logger instance may be used as well:
from("direct:start").log(LoggingLeven.DEBUG, org.slf4j.LoggerFactory.getLogger("com.mycompany.mylogger"), "Processing ${id}").to("bean:foo");
For example you can use this to log the file name being processed if you consume files.
from("file://target/files").log(LoggingLevel.DEBUG, "Processing file ${file:name}").to("bean:foo");
Using log DSL from Spring
In Spring DSL it is also easy to use log DSL as shown below:
<route id="foo">
<from uri="direct:foo"/>
<log message="Got ${body}"/>
<to uri="mock:foo"/>
</route>
The log tag has attributes to set the message, loggingLevel and logName. For example:
<route id="baz">
<from uri="direct:baz"/>
<log message="Me Got ${body}" loggingLevel="FATAL" logName="com.mycompany.MyCoolRoute"/>
<to uri="mock:baz"/>
</route>
Since Camel 2.12.4/2.13.1 it is possible to reference logger instance. For example:
<bean id="myLogger" class="org.slf4j.LoggerFactory" factory-method="getLogger" xmlns="http://www.springframework.org/schema/beans">
<constructor-arg value="com.mycompany.mylogger" />
</bean>
<route id="moo" xmlns="http://camel.apache.org/schema/spring">
<from uri="direct:moo"/>
<log message="Me Got ${body}" loggingLevel="INFO" loggerRef="myLogger"/>
<to uri="mock:baz"/>
</route>
Configuring log name globally
Available as of Camel 2.17
By default the log name is the route id. If you want to use a different log name, you would need to configure the logName option. However if you have many logs and you want all of them to use the same log name, then you would need to set that logName option on all of them.
With Camel 2.17 onwards you can configure a global log name that is used instead of the route id, eg
CamelContext context = ... context.getProperties().put(Exchange.LOG_EIP_NAME, "com.foo.myapp");
And in XML
<camelContext ...>
<properties>
<property key="CamelLogEipName" value="com.foo.myapp"/>
</properties>
Using slf4j Marker
Available as of Camel 2.9
You can specify a marker name in the DSL
<route id="baz">
<from uri="direct:baz"/>
<log message="Me Got ${body}" loggingLevel="FATAL" logName="com.mycompany.MyCoolRoute" marker="myMarker"/>
<to uri="mock:baz"/>
</route>
Using log DSL in OSGi
Improvement as of Camel 2.12.4/2.13.1
When using log DSL inside OSGi (e.g., in Karaf), the underlying logging mechanisms are provided by PAX logging. It searches for a bundle which invokes org.slf4j.LoggerFactory.getLogger() method and associates the bundle with the logger instance. Passing only logger name to log DSL results in associating camel-core bundle with the logger instance created.
In some scenarios it is required that the bundle associated with logger should be the bundle which contains route definition. This is possible using provided logger instance both for Java DSL and Spring DSL (see the examples above).
Using This Pattern
If you would like to use this EIP Pattern then please read the Getting Started, you may also find the Architecture useful particularly the description of Endpoint and URIs. Then you could try out some of the Examples first before trying this pattern out.