THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Introduction
This tutorial covers running Nutch jobs on Apache Tez (instead of MapReduce).
This tutorial is a work in progress and the document should be considered in DRAFT status. The work to evaluate Tez as an appropriate execution engine for Nutch jobs was initiated in December, 2020.
Hadoop version: 3.1.4 released
Tez version: 0.10.0-SNAPSHOT (commit 849e1d7694cdfd2432d631830940bc95c6f26ead)
Nutch version: 1.18-SNAPSHOT (commit 88a17f26b4160720bacb3ead1cad71ae24a559bc)
Audience
This tutorial will appeal to Nutch administrators looking to improve runtime speed whilst maintaining MapReduce’s ability to scale to petabytes of data. Readers are encouraged to share their experienced using Nutch on Tez.
What is Apache Tez?
Apache Tez is described as an application framework which allows for a complex directed-acyclic-graph (DAG) of tasks for processing data. It is currently built atop Apache Hadoop YARN.
The 2 main design themes for Tez are:
- Empowering end users by:
- Expressive dataflow definition APIs
- Flexible Input-Processor-Output runtime model
- Data type agnostic
- Simplifying deployment
- Execution Performance
- Performance gains over Map Reduce
- Optimal resource management
- Plan reconfiguration at runtime
- Dynamic physical data flow decisions
By allowing projects like Apache Hive and Apache Pig to run a complex DAG of tasks, Tez can be used to process data, that earlier took multiple MR jobs, now in a single Tez job as shown below.
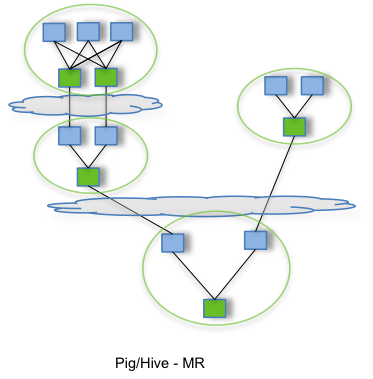
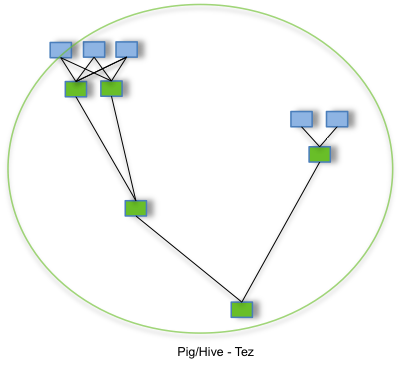
Configuring and Deploying Hadoop Services
Hadoop was configured and deployed in pseudo-distributed mode
hdfs-site.xml Configuration
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
yarn-site.xml Configuration
Configuring and Deploying Tez
Configuring and Deploying Nutch
Evaluating Tez as a Replacement for MapReduce
The following content relates to ongoing experiments which have been run by members of the Nutch community.
Experiments
Running the Injector job on Tez

| Run # | YARN Engine | # of URLs | Elapsed Time |
|---|---|---|---|
| 1 | MapReduce | 11523 | 00:00:34 |
| 2 | MapReduce | 11523 | 00:00:32 |
| 3 | MapReduce | 11523 | 00:00:34 |
| 4 | Tez | 11523 | 00:00:42 |
| 5 | Tez | 11523 | 00:00:13 |
| 6 | Tez | 11523 | 00:00:14 |
| 7 | MapReduce | 15763469 | 00:03:21 |
| 8 | MapReduce | 15763469 | 00:03:13 |
| 9 | MapReduce | 15763469 | 00:02:38 |
| 10 | MapReduce | 15763469 | 00:02:37 |
| 11 | MapReduce | 15763469 | 00:02:48 |
| 12 | Tez | 15763469 | 00:02:14 |
| 13 | Tez | 15763469 | 00:02:10 |
| 14 | Tez | 15763469 | 00:02:13 |
From the above Tez clearly appears to offer significant runtime improvements over MapReduce. This is very promising however much more experimentation is required.
Observed Issues
When using Tez, counters are not populated. This makes sense as all existing counters are created using MapReduce framework Context objects. This presents a major issue. Counters are a requirement to have as they are key to regular inspections of ongoing crawls, finding errors and debugging. The org.apache.tez.common.counters package may offer a equivalent replacement but this has still to be investigated.