THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Vector Chunk 读取优化设计
背景
引入多元时间序列后,IoTDB 在存储设计上引入了 VectorChunk。
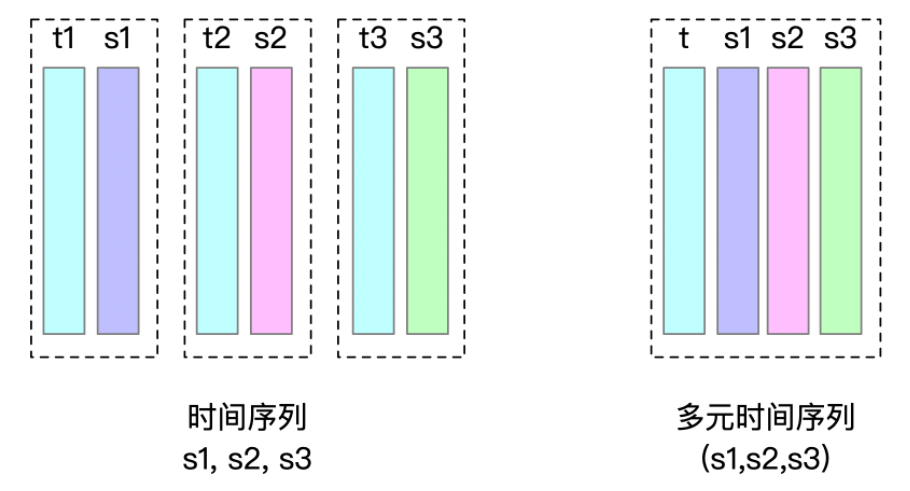
在 TsFile 层面的存储设计上,一个多元时间序列存储为 VectorChunk,包含 TimeChunk 和若干个 ValueChunk。以上图为例,存储 TimeChunk t 及 ValueChunk (t.s1, t.s2, t.s3)。
在TsFile中,对于同一个VectorChunk,其 TimeChunk 和 ValueChunk 的分布是连续的

考虑到同一多元时间序列的多个 measurement 在往往同时读写,在读取时我们可以通过 LRUCache 对 Chunk 进行缓存,减少读文件时的磁盘扫描时间。
性能分析
可行性分析
读取时,可以从FileLoaderUtils.java的loadPageReaderListt(IChunkMetadata chunkMetaData, Filter timeFilter)方法开始分析:

如果是VectorChunkMetadata类型,ChunkMetadata包含了该查询对应的vector和measurement,例如存在一个vector1.(s1,s2,s3),查询为vector1.s1,vector1,s3,则该ChunkMetadata仅包含vector1.(s1,s3)。该方法会读取该 Vector 的 TimeChunk 和 ValueChunk。
注意到 TimeChunk 和 ValueChunk 的排列连续性,我们可以在读取 TimeChunk 的时候对 ValueChunk 进行缓存。
IO分析
在单个Chunk读取的时候,实际上包括了两次磁盘寻道开销和两次传输开销
/**
* read memory chunk.
*
* @param metaData -given chunk meta data
* @return -chunk
*/
public Chunk readMemChunk(ChunkMetadata metaData) throws IOException {
int chunkHeadSize = ChunkHeader.getSerializedSize(metaData.getMeasurementUid());
ChunkHeader header = readChunkHeader(metaData.getOffsetOfChunkHeader(), chunkHeadSize); // 第一次读
ByteBuffer buffer =
readChunk(
metaData.getOffsetOfChunkHeader() + header.getSerializedSize(), header.getDataSize()); // 第二次读
return new Chunk(header, buffer, metaData.getDeleteIntervalList(), metaData.getStatistics());
}
针对VectorChunk的读取,在未读磁盘前我们拥有具有的信息包括
* `ChunkMetadata timeChunkMetadata` TimeChunk 的 Metadata,其中可以获得的有效信息有
* measurementUid
* startOffset
* `List<ChunkMetadata> valueChunkMetadatas` ValueChunk 的 Metadata列表,其中可以获得的有效信息有
* 最后一个ValueChunk的startOffset
* measurementUid
因此,我们可以同样通过两次磁盘寻道开销和两次传输开销,来读取整段的磁盘数据到Buffer
1. 在第一次遍历valueChunkMetadatas后,获得最后一个ValueChunk的startOffset
2. 读取并反序列化最后一个ValueChunk,获得endOffset
3. 根据startOffset和endOffset,读取全部的磁盘数据到Buffer
4. 根据每个 chunkMetadata对Buffer进行切分并反序列化
```java
/**
* read memory chunk once for vector.
*
* @param timeChunkMetadata time chunk metadata
* @param valueChunkMetadatas value chunk metadata
* @return -map
*/
public Map<ChunkMetadata, Chunk> readMemVectorChunk(
ChunkMetadata timeChunkMetadata, List<ChunkMetadata> valueChunkMetadatas) {
Map<ChunkMetadata, Chunk> res = new HashMap<>();
try {
int chunkHeadSize = ChunkHeader.getSerializedSize(timeChunkMetadata.getMeasurementUid());
long endOffset = -1;
ChunkMetadata lastChunkMetadata = null;
for (ChunkMetadata metadata : valueChunkMetadatas) {
if( metadata.getOffsetOfChunkHeader() > endOffset){
endOffset = metadata.getOffsetOfChunkHeader();
lastChunkMetadata = metadata;
}
}
if (endOffset != -1) {
// compute true endOffset
int lastChunkHeaderSize = ChunkHeader.getSerializedSize(lastChunkMetadata.getMeasurementUid());
ChunkHeader lastHeader = readChunkHeader(lastChunkMetadata.getOffsetOfChunkHeader(), lastChunkHeaderSize);
endOffset += lastHeader.getSerializedSize()+lastHeader.getDataSize();
ByteBuffer buffer =
readData(timeChunkMetadata.getOffsetOfChunkHeader(), endOffset); // read once
// load time chunk
int headSize = ChunkHeader.getSerializedSize(timeChunkMetadata.getMeasurementUid());
ChunkHeader header = ChunkHeader.deserializeFrom(buffer, headSize);
byte[] chunkBuffer = new byte[header.getDataSize()];
buffer.get(chunkBuffer, 0, header.getDataSize());
res.put(
timeChunkMetadata,
new Chunk(
header,
ByteBuffer.wrap(chunkBuffer),
timeChunkMetadata.getDeleteIntervalList(),
timeChunkMetadata.getStatistics()));
// load value chunk
for (ChunkMetadata metadata : valueChunkMetadatas) {
if (metadata.getOffsetOfChunkHeader() < endOffset) {
buffer.position(
(int) (metadata.getOffsetOfChunkHeader()
- timeChunkMetadata.getOffsetOfChunkHeader()));
headSize = ChunkHeader.getSerializedSize(metadata.getMeasurementUid());
header = ChunkHeader.deserializeFrom(buffer, headSize);
chunkBuffer = new byte[header.getDataSize()];
buffer.get(
chunkBuffer,0, header.getDataSize());
res.put(
metadata,
new Chunk(
header,
ByteBuffer.wrap(chunkBuffer),
metadata.getDeleteIntervalList(),
metadata.getStatistics()));
}
}
} else {
ChunkHeader header =
readChunkHeader(timeChunkMetadata.getOffsetOfChunkHeader(), chunkHeadSize);
ByteBuffer buffer =
readChunk(
timeChunkMetadata.getOffsetOfChunkHeader() + header.getSerializedSize(),
header.getDataSize());
res.put(
timeChunkMetadata,
new Chunk(
header,
buffer,
timeChunkMetadata.getDeleteIntervalList(),
timeChunkMetadata.getStatistics()));
}
} catch (IOException e) {
e.printStackTrace();
}
return res;
}
## 实现设计
### 原设计
未优化的设计是向`ChunkCache`中传一个ChunkMetadata,向LRUCache中读取对应的Cache,如果未命中则读磁盘并加入缓存
```java
public Chunk get(ChunkMetadata chunkMetaData, boolean debug) throws IOException {
if (!CACHE_ENABLE) {
TsFileSequenceReader reader =
FileReaderManager.getInstance()
.get(chunkMetaData.getFilePath(), chunkMetaData.isClosed());
Chunk chunk = reader.readMemChunk(chunkMetaData);
return new Chunk(
chunk.getHeader(),
chunk.getData().duplicate(),
chunk.getDeleteIntervalList(),
chunkMetaData.getStatistics());
}
Chunk chunk = lruCache.get(chunkMetaData);
if (debug) {
DEBUG_LOGGER.info("get chunk from cache whose meta data is: " + chunkMetaData);
}
return new Chunk(
chunk.getHeader(),
chunk.getData().duplicate(),
chunk.getDeleteIntervalList(),
chunkMetaData.getStatistics());
}新设计
目前使用的是全缓存的策略,有很多优化点,见最后
在读取TimeChunk时,不仅向ChunkCache中传入timeChunkMetadata,还要传入该查询对应的valueChunkMetadata列表。ChunkCache判断如果timeChunkMetadata存在,直接返回;否则在读磁盘文件时候,直接读取所有的TimeChunk和ValueChunk进行缓存
/**
* support for vector
*
* @param timeChunkMetadata timeColumn's chunk metadata
* @param valueChunkMetadatas valueColumns' chunk metadata, only about query measurement
* @return time chunk
*/
public Chunk getTimeChunk(
ChunkMetadata timeChunkMetadata, List<ChunkMetadata> valueChunkMetadatas) throws IOException {
if (CACHE_ENABLE && CACHE_VECTOR_ENABLE) {
Chunk chunk = lruCache.getIfPresent(timeChunkMetadata);
if(chunk==null){
// explicitly put cache
TsFileSequenceReader reader =
FileReaderManager.getInstance()
.get(timeChunkMetadata.getFilePath(), timeChunkMetadata.isClosed());
Map<ChunkMetadata, Chunk> map =
reader.readMemVectorChunk(timeChunkMetadata, valueChunkMetadatas);
lruCache.putAll(map);
chunk = map.get(timeChunkMetadata);
}
return new Chunk(
chunk.getHeader(),
chunk.getData().duplicate(),
chunk.getDeleteIntervalList(),
timeChunkMetadata.getStatistics());
} else {
return get(timeChunkMetadata, false);
}
}实验
实验环境
数据集:1个vector,500个measurement,每个measurement有100000个数据
每次查询后清空缓存
使用session,客户端计时
long startTime = System.currentTimeMillis();
selectTest(sql);
long endTime = System.currentTimeMillis();
最优情况
顺序查询,number of measurement 代表查询的measurement个数,比如3就是select * from root.sg_1.d1.vector.s001, root.sg_1.d1.vector.s002, root.sg_1.d1.vector.s003

极端情况
极端情况查询,即只查首尾两个,中间会浪费很大的数据传输开销。number of measurement 代表尾measurement的位置,比如100就是select * from root.sg_1.d1.vector.s001, root.sg_1.d1.vector.s100

针对极端情况,开启cache的情况下,一开始的查询时间比较少,但如果数据传输开销大到一定程度后,non-cache的性能较好。
待优化点
根据实验,在极端情况下使用全缓存会使得性能大幅下降。而最优情况下却相差不大,不知道这里是不是因为实验环境的问题、操作系统的缓存或是JAVA编译优化导致的,待排查。
初步优化思路:在浪费的传输开销和可能浪费的寻道开销之间寻找tradeoff
在读chunk的时候,未读磁盘可以拥有的信息有:
ValueChunk 的个数 n
TimeChunk的startOffset
最后一个ValueChunk的起始位置
读一次磁盘,获取最后一个ValueChunkHeader后,可以有的信息是
endOffset
一个ValueChunk的预估长度 len(ValueChunkHeader里,用最后一个ValueChunk来估计)
从而可以估算出浪费的传输延迟是
(endOffset-startoffset)-n*len而理论上可以节省的寻道延迟为
n次根据
n次寻道时间和(endOffset-startoffset)-n*len的传输时间,寻找tradeoff