Apache Kylin : Analytical Data Warehouse for Big Data
Welcome to Kylin Wiki.
Background
Since that fact that Kylin4 is highly depend on Spark SQL, it better we have a deeper understanding of Spark SQL.
Definitation
Catalyst is an execution-agnostic framework to represent and manipulate a dataflow graph, i.e. trees of relational operators and expressions.
The main abstraction in Catalyst is TreeNode that is then used to build trees of Expressions or QueryPlans.
Core Components
| Name | Target |
|---|---|
| SQL Parser Framework | SQL Parser Framework in Spark SQL uses ANTLR to translate a SQL text to a data type, Expression, TableIdentifier or LogicalPlan. |
| Catalyst Framework | Catalyst is an execution-agnostic framework to represent and manipulate a dataflow graph, i.e. trees of relational operators and expressions. |
| Tungsten Execution Backend | The goal of Project Tungsten is to improve Spark execution by optimizing Spark jobs for CPU and memory efficiency (as opposed to network and disk I/O which are considered fast enough). Tungsten focuses on the hardware architecture of the platform Spark runs on, including but not limited to JVM, LLVM, GPU, NVRAM, etc. It does so by offering the following optimization features:
|
| Monitor | SQL tab in web UI shows SQLMetrics per physical operator in a structured query physical plan. You can access the SQL tab under By default, it displays all SQL query executions. However, after a query has been selected, the SQL tab displays the details for the structured query execution. |
Contract/Interface
Core Interface
| Name | Contract | Comment |
|---|---|---|
| SparkSession | Entry Point to Spark SQL |
As a Spark developer, you create a |
| Dataset | Structured Query with Data Encoder | Dataset is a strongly-typed data structure in Spark SQL that represents a structured query. |
| Catalog | Metastore Management Interface |
|
Parser Framework
| Name | Contract | Comment |
|---|---|---|
| ParserInterface | Base of SQL Parser | ParserInterface is the abstraction of SQL parsers that can convert (parse) textual representation of SQL statements into Expressions, LogicalPlans, TableIdentifiers, FunctionIdentifier, StructType, and DataType. |
| AbstractSqlParser | Base SQL Parsing Infrastructure | AbstractSqlParser is the base of ParserInterfaces that use an AstBuilder to parse SQL statements and convert them to Spark SQL entities, i.e. DataType, StructType, Expression, LogicalPlan and TableIdentifier. |
Catalyst Framework
| Name | Contract | Comment |
|---|---|---|
| TreeNode | Node in Catalyst Tree |
|
| Expression | Executable Node in Catalyst Tree |
|
| QueryPlan | Structured Query Plan |
Scala-specific, |
| LogicalPlan | Logical Relational Operator with Children and Expressions / Logical Query Plan |
A logical query plan is a tree of nodes of logical operators that in turn can have (trees of) Catalyst expressions. In other words, there are at least two trees at every level (operator). |
| SparkPlan | Physical Operators in Physical Query Plan of Structured Query |
|
| QueryPlanner | Converting Logical Plan to Physical Trees |
|
| InternelRow | Binary Row Format |
UnsafeRow is a concrete InternalRow. |
| Attribute | Base of leaf named expressions |
|
| CodegenSupport | Physical Operators with Java Code Generation |
|
BaseRelation | Collection of Tuples with schema |
"Data source", "relation" and "table" are often used as synonyms. |
Physical Operator
| Name | Contract | |
|---|---|---|
| Exchange | Base for Unary Physical Operators that Exchange Data |
|
Core Diagram
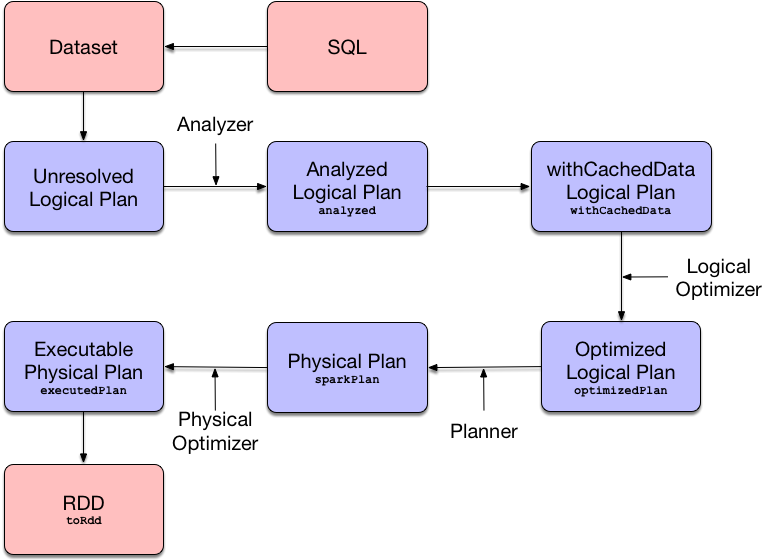
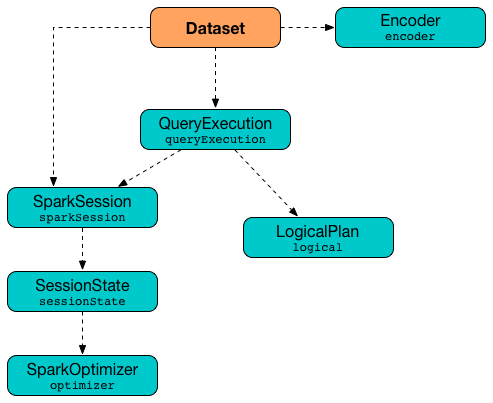
Framework UML Diagram
High level Interface
Credit
All right reserved to jaceklaskowski.
Overview
Content Tools
ThemeBuilder
Apps