THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: "Under Discussion"
Discussion thread:
JIRA:
Released: <Flink Version>
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
In the batch world, Hive is still the standard. Considering that Flink has continuously improved its compatibility with Hive in recent years, we propose to expose HiveServer2 Endpoint on the Flink SQL Gateway. The Endpoint will implement the thrift interface exposed by HiveServer2, and users' BI, CLI and other tools based on the HiveServer2 can also be seamlessly migrated to the Flink SQL Gateway.
HiveServer2 has 3 kinds of functionality:
- manage the metadata info in the Hive MetaStore
- translate the HiveSQL to the Operation and execute:
- translate DML/QUERY to MapReduce job and submit the job to the Hadoop
- translate to the Operation that manipulates the Hive MetaStore
- Users can lookup the Operation status and manage the submitted Operation.
Overall Design
HiveServer2 has the similar architecture we describe in the FLIP-91. User should register the Session in the SessionManager before submitting the statement. After that, the user uses the SessionHandle to find the registered resources in the Session and execute the statements. All statements will be translated to the Operation and use the OperationHandle to fetch the results or logs. Therefore, the HiveServer2 endpoint gurantees:
- The
SessionHandleandOperationHandlein the HiveServer2 is able to convert to theSessionHandleandOperationHandlein the FLIP-91; - The interfaces exposed by the HiveServer2 can be converted into related calls in Flink
GatewayService;
Handle
The structure of the Handle in the HiveServer2 is as follows.

The transfomration is as follows.
- HiveServer2
SessionHandlehas the same structure with the GatewaySessionHandle - The HiveServer2
OperationHandlehas more information than theOperationHandlein the Gateway. HiveServer2 endpoint should use the result of theGatewayService#getOperationInfoto build theOperationHandlein the HiveServer2.
HiveServer2 Endpoint API
Refer to the file for the HiveServer2 API.
GatewayService API Change
Session API
- OpenSession
- Usage:register a
Sessionin theSessionManager - Return:
SessionHandle - HiveServer2 Endpoint needs to do:
- Determine the communication version between HiveServer2 and Client;
- Invoke
GatewayService#openSessionto register theSession; - Configure the Hive Environment
- Create the Hive Catalog
- Switch to the Hive Dialect
- Load the Hive Module
- CloseSession
- Usage: Clear the related resources;
- HiveServer2 Endpoint needs to do:
- Invoke the
GatewayService#closeSession
Operation API
- GetOperationStatus
- Usage: Get the Operation status.
- HiveServer2 Endpoint needs to do:
- Invoke the
GatewayService#getOperationStatus
- CancelOperation
- Usage: Cancel the Operation.
- HiveServer2 Endpoint needs to do:
- Invokes the
GatewayService#cancelOperation
- CloseOperatio
- Usage: Close the Operation
- HiveServer2 Endpoint needs to do:
- Invoke the
GatewayService#closeOperation
Statement API
- ExecuteStatement
- Usage: Execute the SQL to the Gateway Service synchronously or asynchronously.
- Return:
OperationHandle - HiveServer2 Endpoint needs to do:
- Invokes the
GatewayService#executeStatement - HiveServer2 supports to execute statement in the synchronous mode.
- ExecuteStatement with
table.dml-syncis true. - Currently the
GatewayServiceonly supports submission in asynchronous mode. It requires the HiveServer2 Endpoint to monitorOperationstatus.
- FetchResults
- Usage: Supports fetching the results or logs with fetch orientation to the client.
- HiveServer2 Endpoint needs to do:
- Invoke the
GatewayService#fetchResultsorGatewayService#fetchLog
- GetResultSetMetadata
- Usage: return the result schema
- HiveServer2 Endpoint needs to do:
- Invokes the
GatewayService#getResultSchema。
- GetInfo
- Get cluster info。
- Only support to get the CLI_SERVER_NAME(FLINK) now. Extend other values if needed in the future.
- GetTypeInfo
- Get the ODBC's type info.
- GetCatalogs
- Return the registered Catalogs.
- Do as follows:
/**
* The schema for the Operation is
* <pre>
* +-------------------------------+--------------+
* | column name | column type | comments |
* +-------------------------------+--------------+
* | TABLE_CAT | STRING | catalog name |
* +-------------------------------+--------------+
* </pre>
*/
gateway.submitOperation(
HiveServer2OperationType.GET_CATALOGS,
() -> convertToGetCatalogs(gateway.listCatalogs()),
resultSchema);
- GetSchemas
- Return the databases info。Currently HiveServer2 supports to use regex to filter out the unmatched database.
- Do as follow:
/**
* The schema for the Operation is
* <pre>
* +-------------------------------+--------------+
* | column name | column type | comments |
* +-------------------------------+--------------+
* | TABLE_SCHEMA | STRING | schema name |
* +-------------------------------+--------------+
* | TABLE_CAT | STRING | catalog name |
* +-------------------------------+--------------+
* </pre>
*/
gateway.submitOperation(
HiveServer2OperationType.GET_SCHEMAS,
() -> {
List<String> databases = filter(gateway.listDatabases(sessionHandle), databasePattern);
return convertToGetDatabasesResultSet(databases);
},
resultSchema);
- GetTables
- Get the tables in the specified Catalog and Database. HiveServer2 allows to use the Catalog/Database/Table Pattern to filter out the unmatched tables.
- Do as follow:
/**
* The schema for the Operation is
* <pre>
* +-------------------------------+--------------------------------+
* | column name | column type | comments |
* +-------------------------------+--------------------------------+
* | TABLE_CAT | STRING | catalog name |
* +-------------------------------+--------------------------------+
* | TABLE_SCHEMA | STRING | schema name |
* +-------------------------------+--------------------------------+
* | TABLE_NAME | STRING | table name |
* +-------------------------------+--------------------------------+
* | TABLE_TYPE | STRING | table type, e.g. TABLE, VIEW |
* +-------------------------------+--------------------------------+
* | REMARKS | STRING | table desc |
* +-------------------------------+--------------------------------+
* </pre>
*/
gateway.submitOperation(
HiveServer2OperationType.GET_TABLES,
() -> {
List<CatalogTable> results = new ArrayList<>();
List<String> catalogs = filter(gateway.listCatalogs(sessionHandle), catalogPattern);
for (String catalog: catalogs) {
List<String> databases = filter(gateway.listDatabases(sessionHandle, catalog), databasePattern);
for (String database: databases) {
List<String> tables = filter(gateway.listTables(sessionHandle, catalog, database), tablePattern);
for (String table: tables) {
results.add(gateway.getTable(catalog, database, table, ALL));
}
}
}
return convertToGetTablesResultSet(results);
},
resultSchema);
- GetTableTypes
- Return the table types in the current catalog and current database.
- Do as follow.
/**
* The schema for the Operation is
* <pre>
* +-------------------------------+--------------------------------+
* | column name | column type | comments |
* +-------------------------------+--------------------------------+
* | TABLE_TYPE | STRING | table type, e.g. TABLE, VIEW |
* +-------------------------------+--------------------------------+
* | REMARKS | STRING | table desc |
* +-------------------------------+--------------------------------+
* </pre>
*/
gateway.submitOperaton(
HiveServer2OperationType.GET_TABLE_TYPES,
() -> {
String catalog = gateway.getCurrentCatalog();
String database = gateway.getCurrentDatbase();
List<TableDescriptor> tables = gateway.listTables(catalog, database, ALL);
return convertToGetTablesResultSet(results);
}
)
- GetColumns
- Return the column info for the specified tables
- Should be similar to the GatTables
- GetPrimaryKeys
- Return the PK infos
- Should be similar to the GatTables
- GetFunctions
- Return the registered function infos
- Should be similar to the GatTables
Unsupported API
- GetCrossReference
Flink doesn't have the concepts about cross reference.
- GetDelegationToken、CancelDelegationToken、RenewDelegationToken
Flink doesn't support to get the delegation token from the Yarn side now.
Public Interfaces
GatewayService API Change
public interface GatewayService {
/**
* Fetch the Operation-level log from the GatewayService.
*/
ResultSet fetchLog(
SessionHandle sessionHandle,
OperationHandle operationHandle,
FetchOrientation orientation,
int maxRows);
/**
* Only supports FORWARD/BACKWARD.
* - Users can only BACKWARD from the current offset once.
* - The Gateway don't not materialize the changelog.
*/
ResultSet fetchResult(
SessionHandle sessionHandle,
OperationHandle operationHandle,
FetchOrientation orientation,
int maxRows
);
}
enum FetchOrientation {
FORWARD,
BACKWARD
}
Options
We use the same style as the HiveServer2 options。
Option name | Default value(Required) | Description |
hiveserver2.catalog.hive-conf-dir | (none)(Yes) | URI to your Hive conf dir containing hive-site.xml. The URI needs to be supported by Hadoop FileSystem. If the URI is relative, i.e. without a scheme, local file system is assumed. If the option is not specified, hive-site.xml is searched in class path. |
hiveserver2.catalog.name | hive (no) | hive catalog name |
hiveserver2.catalog.default-database | (none) (Yes) | The default database to use when the catalog is set as the current catalog. |
hiveserver2.thrift.bind-port | 8084(No) | The port of the HiveServer2 endpoint |
hiveserver2.thrift.worker.min-threads | 5(No) | HiveServer2 uses |
hiveserver2.thrift.worker.max-threads | 512(No) | |
hiveserver2.thrift.worker.alive-duration | 60 s(No) | |
hiveserver2.transport.mode | binary/http (tcp) | Currently only supports binary mode. |
Example
endpoint.protocol: hiveserver2 endpoint.hiveserver2.port: 9002 endpoint.hiveserver2.catalog.hive-conf-dir: /path/to/catalog
Implementation
HiveServer2 uses the Apache Thrift framework. The server is composed of 3 parts.
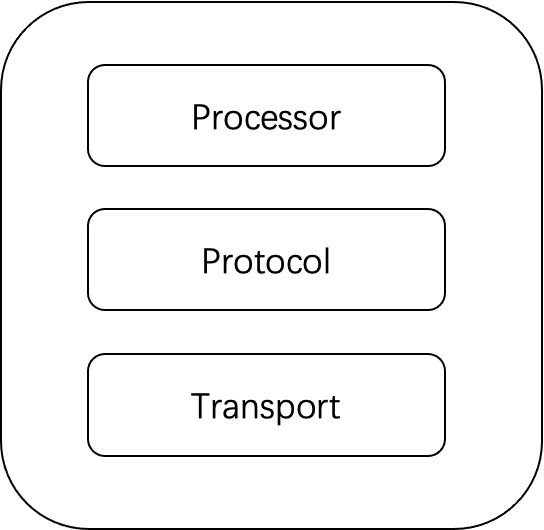
- Transport determines how the client communicates with the server。Now HiveServer2 supports http and binary mode.
- Protocol is responsible for serialization and deserialization。Currently HiveServer2 uses the TBinaryProtocol.
- Processor is the application logic to handle requests 。We should rewrite the Processor with the Flink logic.
Therefore, we relies on the hive-service-rpc which contains HiveServer2 API and thrift dependencies. We will use the Hive-2.3.x as the Endpoint version, which is the most popular. Considering the HiveServer2 endpoint is lightweight and needs to work with the Hive Catalog, we just merge the HiveServer2 Endpoint into the flink-connector-hive module.