THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
1 实验环境
1.1 测试条件
500个measurement
每个measurement 10000row
1.2 测试用例
Read All Vector Chunk
读一串连续的measurement,横坐标表示读取一个vector下连续的chunk的数量(从1开始)
select s001,s002,s003,..,s100 from root.sg_2.d1.vector
Read Bad Vector Chunk
读两个measurement,横坐标表示读取一个vector下的首尾chunk的间隔
select s001,s500 from root.sg_2.d1.vector
2 windows环境
2.1 Read All Vector Chunk
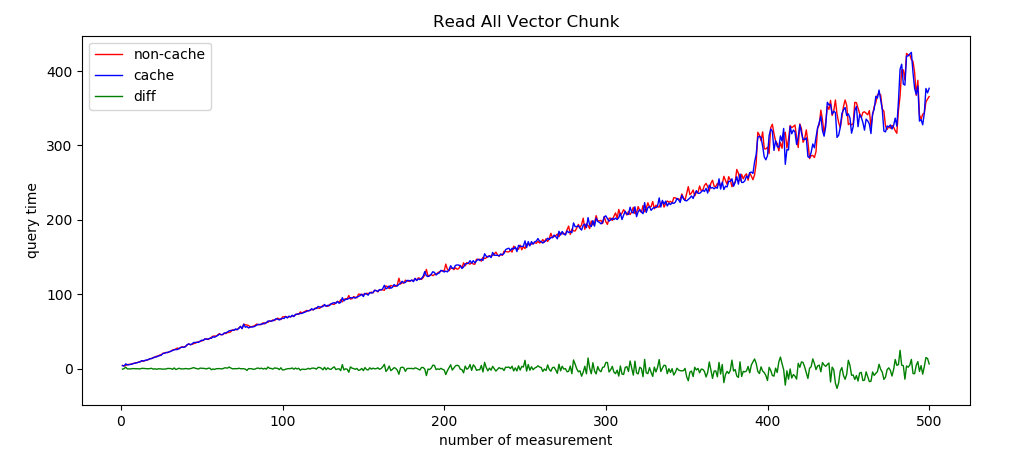
分析:
时间基本上是线性增长,符合预期
添加cache后基本没有优化,不符合预期
3 Linux环境
使用Linux环境测试,主要是为了借助
vmtouch工具验证OS缓存的影响。
3.1 lock
使用vmtouch工具,强制使tsfile驻留在OS缓存中。
在cli端进行测时,4次实验去极值取平均
实验前:

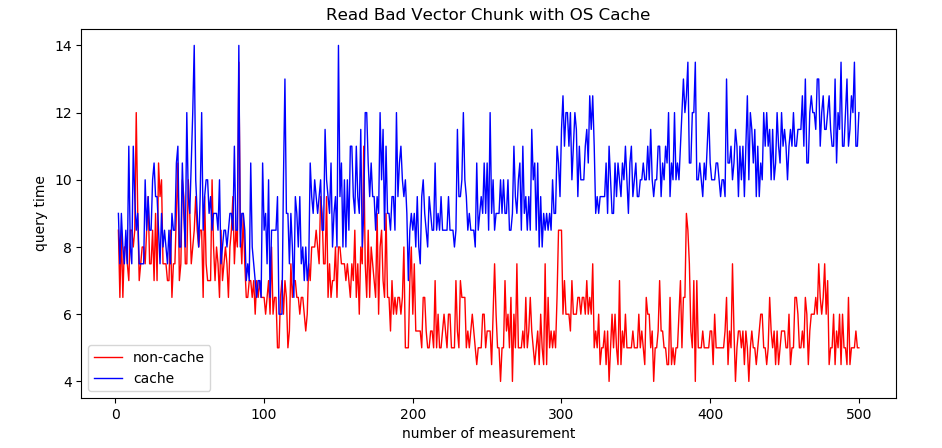
分析:
Read All Vector Chunk 的情况下,都不涉及磁盘IO,效率没有差别。
Read Bad Vector Chunk 的情况下,读的measurement间隔越大,性能差异越大。我认为原因可能是
开cache时需要开一个较大的ByteBuffer
内存IO传输大小
3.2 evict
使用vmtouch工具,每次读文件前都强制将tsfile从OS缓存中移除,即真对磁盘进行IO
4次实验去极值取平均
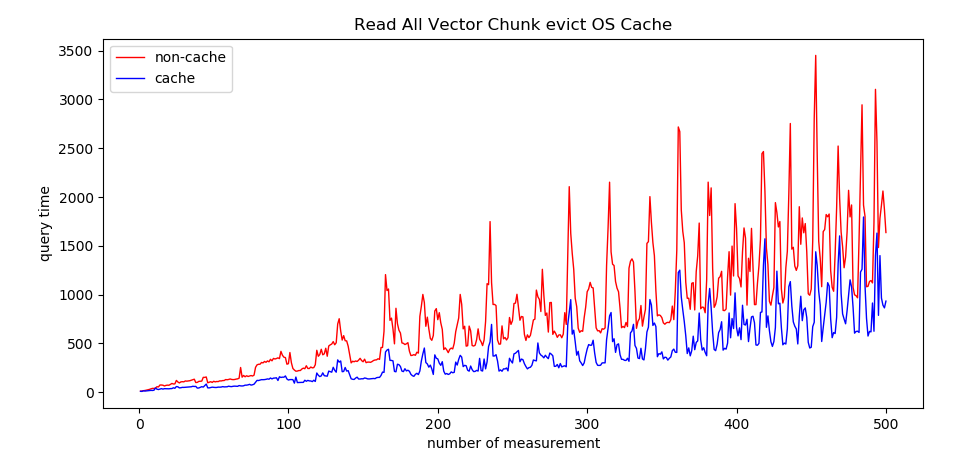
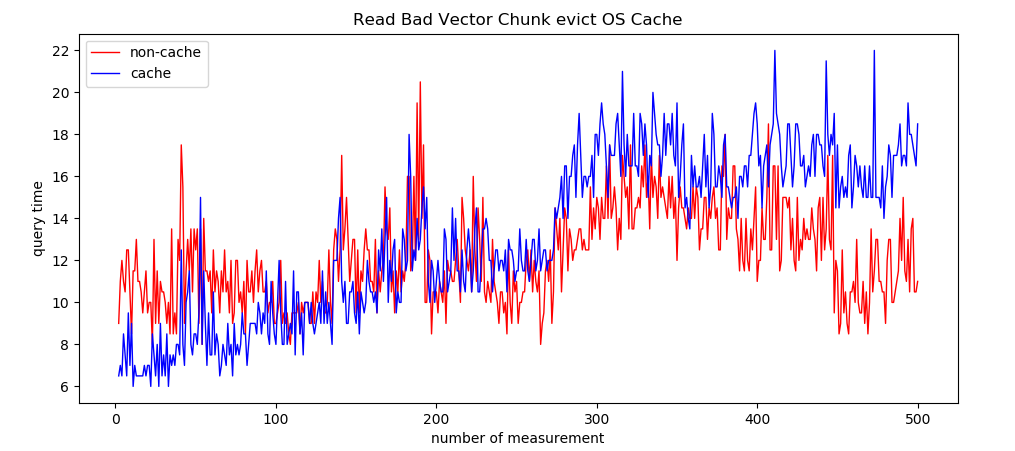
分析:
Read All Vector Chunk 的情况下,符合理想预期,但是由于跑一次测试时间比较久,起伏比较大。
Read Bad Vector Chunk 的情况下,符合理想预期,读的measurement间隔较小时cache好,读的measurement间隔大时non-cache好
non-cache情况下,进行四次磁盘IO,不浪费传输。