THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Apache Airavata
Mentors :- Dimuthu Upeksha, Suresh Marru, Isuru Ranawaka

I'm briefly summarizing my tasks during this year's GSoC period.
Starting off, my first task was to come up with a frontend system and backend system for maintaining the launch, stop, creation and deletion of Jupyter notebook processes.
Initially i started with setting up my local system for work on Flask, React and MySQL and created a couple of sample applications to gain hands on experience with the above technologies, the source code for which can be found here :-
https://github.iu.edu/hhansar/GSoC22
I also created a ToDo List application apart from these, to get all the pieces of the puzzle before starting my core development.
I ended up creating the frontend initially on HTML and Backend using generic templates in Flask and finally shifted to React frontend with a regular backend in Flask.
This is what the initial frontend system looked like before the styling and CSS was added with the ability to CREATE a notebook entry using a popup, following which it came to the CREATED database. Following this, entries in the CREATED database could be launched as well, allowing this dynamic menu items to change and react based on the launch and delete from the saved table to the running table.
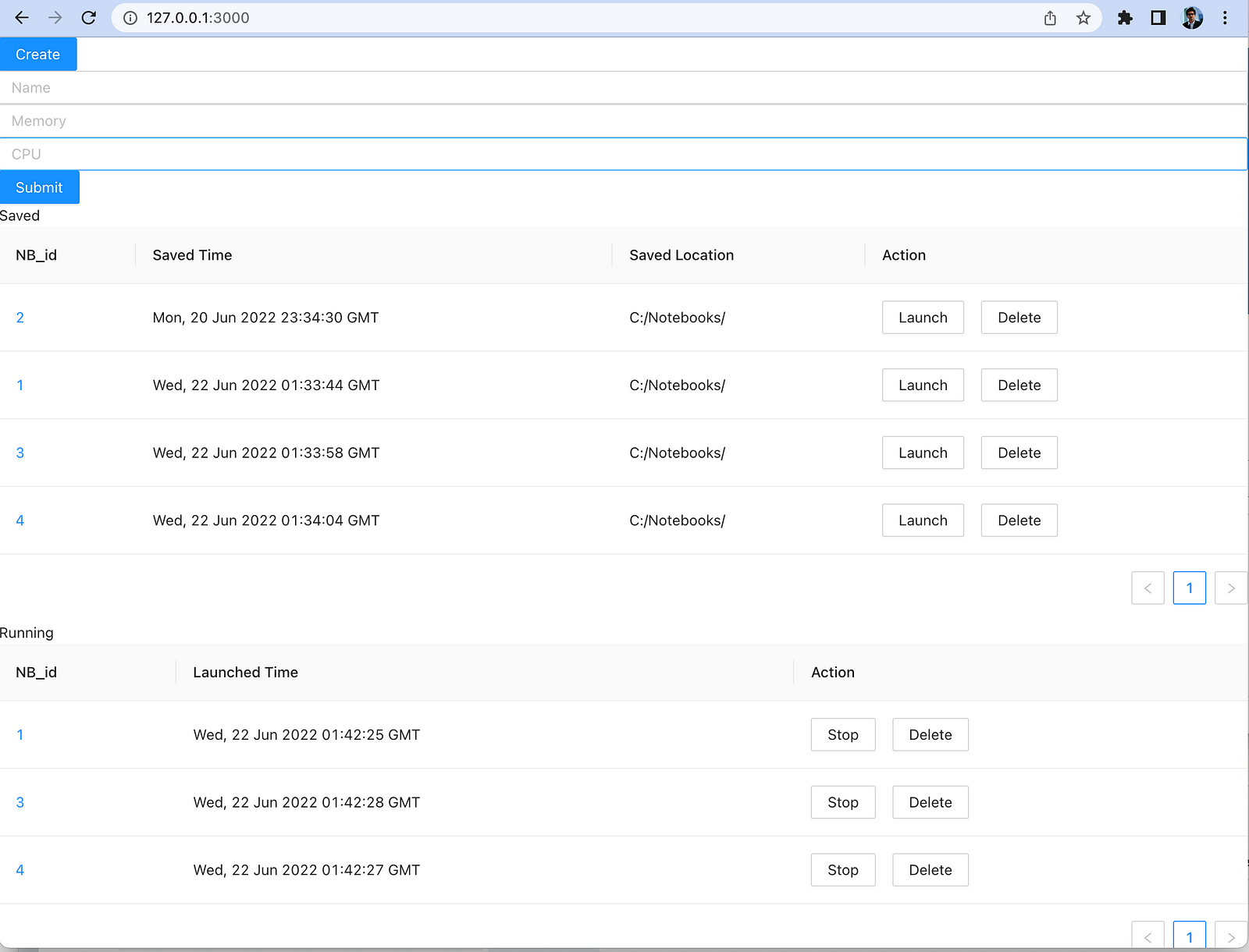
I created the backend system in Flask using Python, where i created the API’s based on each of the action buttons as seen in the above diagram supporting the items in the aforementioned paragraph.
The PR for the frontend and backend can be found here :-
https://github.com/Mrsterius/airavata-sandbox/tree/jupyter/gsoc2022/jupyter-platform-dashboard
the code of which was eventually merged here https://github.com/SciGaP/iPython-Kerner-Changes/tree/main/jupyter-platform.
My next major task was to understand the functionality of Jupyterhub so that i could work on analysing the performance comparison with the platform application as in here and the Jupyterhub slurm containerization being replaced with the existing Jupyterhub Slurm setup based on the slurmspawner.
I spent time sifting through various architecture videos on Jupterhub and setting up docker for the subtasks that lie ahead.
I started with this task by setting up Jupyterhub on my local system and additionally running the dockerspawner which i was able to use to run the jupyterhub process on a docker container instead, the context of which will get cleared later in this article.
After that, I started analysis on the existing Jupyterhub Slurm deployment where I understood what the BatchScheduling system slurm does to stably spin up new Jupyter notebook servers based on the time, CPU and memory resources as specified in the jupyterhub config file. I came up with the following architectures for the current way in which Jupyterhub Slurm deployment behaves.
Before the final cluster setup, i personally tried to setup the Jupyterhub Slurm cluster the steps of which I have annotated in this blog :- https://medium.com/@himanshu.hansaria/slurm-cluster-setup-on-single-node-on-ubuntu-22-04-f851ee08c4e7, since i spent conisderable time going through the vast array of different resources on the topic before finally being able to run Slurm successfully. The jupyterhub setup i followed can be referenced from here.
This is what the existing Jupyterhub Slurm deployment looks like :-
![]()
The following architecture i analysed is what was intended with the platform application to augment a framework to capture and reproduce the absolute state of Jupyter Notebooks, led by Dimuthu Upeksha.
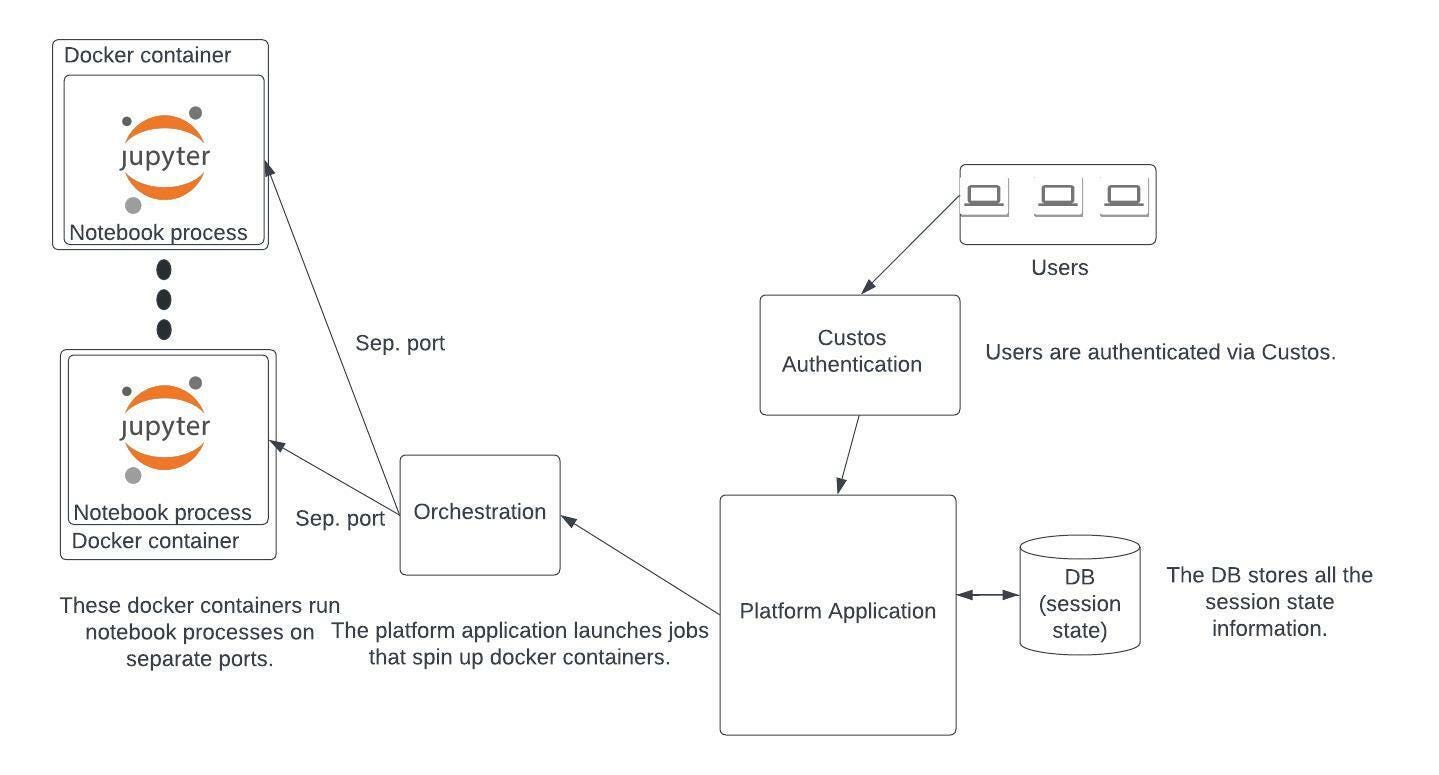
Therefore, after the slurm jupyterhub setup was complete, our goal became to use the standard batch spawner (slurmspawner) provided by jupyterhub to replace the notebook processes as seen in the first architecture diagram with the containers as seen in the second. With it running in the SLURM cluster, i needed to create a base configurable docker image and change the slurm script which spins up notebook processes to spinup notebook containers instead.
For this task, i created a base configurable docker image, and pushed it to docker hub from where i could pull the image on the fly before running the docker container in the spawned server.
The relevant codes for the jupyterhub containerization with slurm orchestration can be found here :-
https://github.com/Mrsterius/airavata-sandbox/tree/jupyter/gsoc2022/jupyterhub-slurm-codes
It contains the jupyterhub_config file which contains the slurm script for running the docker container inside the spawned server as well as the dockerfile and .dockerignore files used to build the base configurable docker image.
I was able to run the jupyterhub process in the docker container in the spawned server, however there was a persistent issue which didn’t allow me to connect with the jupyterhub process in the docker container in the spawned server from the hostnode before this timeline.
Learnings
I learnt a lot during this GSoC program as I didn’t have much Distributed Systems experience before joining the program. I learnt to see the bigger picture of machines as the interaction among different systems. Also, i gained functional working knowledge of React, Flask and the ways of Jupyterhub. I also learnt the principles and the modus operandi of doing Open Source contributions and gained more confidence with Software development/engineering processes. I would like to thank my mentors for constantly pushing me to achieve as much as possible in the given timeline, resulting in a lot of learning in short amount of time.
Challenges
I faced multiple issues while setting up the jupyterhub slurm cluster on a fresh vm. That’s why I created a blog post on the same so that it becomes easier for someone else on the same path.
Also, while running the docker container within the spawned server using the jupyterhub slurm script, I faced several challenges along the way which was rectified one by one involving a lot of network related debugging.
Future Work
I intend to continue contributing to Airavata and take the project to it’s desired conclusion. For now, my goal is to remove the underlying issue present with connecting with the jupyterhub process started in the docker container in the spawned server.
Overview
Content Tools
Apps
For an overview of Apache Airavata visit the Website - https://airavata.apache.org/![]()