THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Authors: Xingbo Huang, Robert Metzger, Jincheng Sun
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Scalar Python UDF (FLIP-58) has already been supported in release 1.10 and Python UDTF will be supported in the coming release of 1.11. In release 1.10, we focused on supporting UDF features and did not make many optimizations in terms of performance. Although we have made a lot of optimizations in master, Cython can further greatly improve the performance of Python UDF.
Background
Cython is an optimizing static compiler for both the Python programming language and the extended Cython programming language (based on Pyrex). It makes writing C extensions for Python as easy as Python itself.
Examples
We can write an easy example to understand the difference between Cython and your module created with Python.
This example (from Cython official web) is about the integration of the function f (x) in [a, b].
# Pure Python Code def f(x): return x ** 2 - x def integrate_f(a, b, N): s = 0 dx = (b - a) / N for i in range(N): s += f(a + i * dx) return s * dx |
# Cython Code cdef double f(double x): return x ** 2 - x cpdef integrate_f(double a, double b, int N): cdef int i cdef double s, dx s = 0 dx = (b - a) / N for i in range(N): s += f(a + i * dx) return s * dx |
Check out the table below which shows how much speed Cython gave us for different number function calls. We got over 150X speedup with Cython!
nCalls | Pure code time(s) | Cython Code time(s) | Speedup |
10000 | 2.165466 | 0.012378 | 174x |
50000 | 10.803928 | 0.061041 | 176x |
100000 | 21.277053 | 0.114681 | 185x |
200000 | 41.897756 | 0.219027 | 191x |
500000 | 105.50863 | 0.544354 | 193x |
1000000 | 218.101658 | 1.07485 | 202x |

As we can see, although the syntax of Cython is similar to python, Cython can bring huge performance improvements.
Proposed Changes
Overview
- Introduces Cython implementation of coder and operations
- Doc changes for building sdist and wheel packages from source code
- Solutions for packages building
Introduce Cython Implementation of Coder and Operations
Workflow of Processing Data
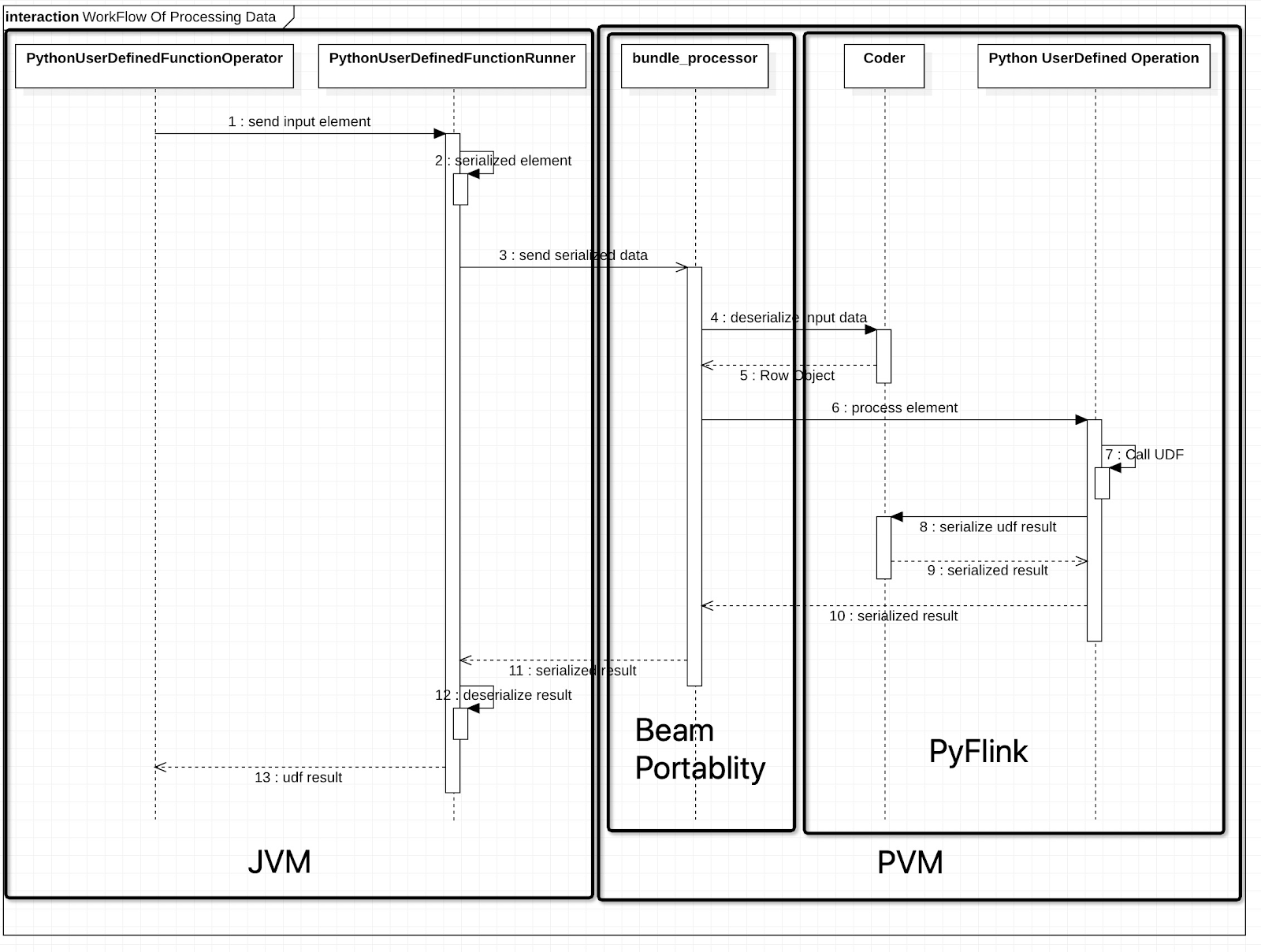
As we can see from the workflow,
- PVM is bottleneck because PVM is much slower than JVM in performance
- The bundle_processor is part of Beam Portability Framework utilized by PyFlink. Beam has done a lot of optimizations on it, so this part is not the part we need to optimize.
- We can optimize the Coder and Python User-Defined Operations modules to improve our performance.
By optimizing the data structure and algorithm logic used by these two modules, compared to PyFlink 1.10, we have optimized about 5X.
If we use Cython, we can optimize 6X on the basis of master code. Compared to PyFlink 1.10, it is optimized by 30X.
Performance Improvements
Next, let's take a look at the test code we used and compare it with the detailed test performance data of release-1.10, master and code optimized with Cython.
Test Code
@udf(input_types=[DataTypes.INT(False)], result_type=DataTypes.INT(False))
|
End To End Performance comparison
Check out the table below which shows how much speed Cython gave us for different rows and columns test data. When there is only one column of data, the inc func is called once for each row of data, so all the overhead lies in the framework. When there are ten columns of data, the inc func will be called ten times for each row of data, Therefore, compared with the case of 10 rows and one column, the more time is spent in calculation, so the end-to-end promotion multiple is not as large as that of 10 rows and one column.
rows, columns | PyFlink 1.10 | master | master-Cython | Cython speedup (release-1.10) | Cython seedup (master) |
10kw, 1 | 2154s | 441s | 70s | 30X | 6x |
10kw, 10 | 5697s | 1221s | 254s | 22X | 5X |

From the data in the table and diagram, we can find that using Cython can greatly improve our performance.
Doc Changes for Building Sdist And Wheel Package From Source Code
Docs Changes for Building from Source Code
We need to add one step at the beginning to install the relational dependencies for compiling cython code in the progress of building sdist and wheel packages in building from source code doc page[1].
cd flink-python # pip install dependencies pip install -r dev/requirements.txt |
Next, we can build sdist and wheel package in flink-python directory
python setup.py sdist bdist_wheel |
The sdist and wheel package will be found under ./flink-python/dist/. Either of them could be used for pip installation, such as:
python -m pip install dist/*.tar.gz |
Release Changes for Deploy Python artifacts to PyPI
We need to add a step to download wheels from the Artifacts page of the Azure Pipeline built results and upload corresponding wheels to PyPI[2].
# 1. Downloads wheels from Azure Artifacts
# 2. Put the downloaded wheel packages in dist folder of flink-python module cd flink-python mkdir dist(optional) ## move all downloaded wheel packages to the dist folder(manually) # 3. Run the supported script to restore executable permission ## Script files in packages downloaded from Azure will lose executable permissions dev/restore-executable.sh #3 Upload the wheel packages to PyPI, e.g. twine upload --repository-url https://upload.pypi.org/legacy/ dist/*.whl |

Solutions For Packages Building
After the introduction of cython, in addition to the sdist package installation, we will also provide the wheel package installation method.
After investigating some mainstream Python projects, we found that there are mainly the following three solutions for building cross platform wheel packages in PyFlink :
- Creates another project to build wheel packages. Apache-beam created a beam-wheels repository for the sole purpose of building wheel packages.
- Introduces github actions to build wheel packages.
- Adds building wheel packages logic to current Azure CI of Flink
Props | Cons | |
Solution 1 | We can learn from beam-wheels | 1. Beam have already discussed about to change this solution to github actions as solution 2 2. Need to create another repository |
Solution 2 | 1. Github actions comes with a strong level of integration with GitHub 2. We can build our wheel packages very simply by using many action tools,such as (actions/setup-java, actions/setup-python, actions/upload-artifact) | 1. It introduces another build CI system of github actions which increases the burden of maintaining 2. Github action is still very young |
Solution 3 | The logic of building wheel package could be integrated into the current Azure CI directly | N/A |
Solution 3 is preferred now as we already have built stable Azure CI in Flink and it is convenient to add the logic of building wheel packages to Azure CI.
Public Interfaces
Coder Cython Implementation
The current implementation of the coder is a pure python implementation.We will add two python files to support Cython implementation of coder.
- fast_coder_impl.pxd
- fast_coder_impl.pyx
fast_coder_impl.pxd will define the corresponding declaration of coder and fast_coder_impl.pyx will provide specific implementation.
# fast_coder_impl.pxd cdef class FlattenRowCoderImpl(StreamCoderImpl): cdef list _input_field_coders cdef list _output_field_coders cdef unsigned char* _input_field_type cdef unsigned char* _output_field_type cdef libc.stdint.int32_t _input_field_count cdef libc.stdint.int32_t _output_field_count cdef libc.stdint.int32_t _input_leading_complete_bytes_num cdef libc.stdint.int32_t _output_leading_complete_bytes_num cdef libc.stdint.int32_t _input_remaining_bits_num cdef libc.stdint.int32_t _output_remaining_bits_num cdef bint*_null_mask cdef unsigned char*_null_byte_search_table cdef char* _output_data cdef char* _output_row_data cdef size_t _output_buffer_size cdef size_t _output_row_buffer_size cdef size_t _output_pos cdef size_t _output_row_pos cdef size_t _input_pos cdef size_t _input_buffer_size cdef char* _input_data cdef list row cpdef _init_attribute(self) cdef _consume_input_data(self, WrapperInputElement wrapper_input_element, size_t size) cpdef _write_null_mask(self, value) cdef _read_null_mask(self) cdef _copy_before_data(self, WrapperFuncInputStream wrapper_stream, OutputStream out_stream) cdef _copy_after_data(self, OutputStream out_stream) cpdef _dump_field(self, unsigned char field_type, CoderType field_coder, item) cdef _dump_row(self) cdef _dump_byte(self, unsigned char val) cdef _dump_smallint(self, libc.stdint.int16_t v) cdef _dump_int(self, libc.stdint.int32_t v) cdef _dump_bigint(self, libc.stdint.int64_t v) cdef _dump_float(self, float v) cdef _dump_double(self, double v) cdef _dump_bytes(self, char*b) cpdef _load_row(self) cpdef _load_field(self, unsigned char field_type, CoderType field_coder) cdef unsigned char _load_byte(self) except? -1 cdef libc.stdint.int16_t _load_smallint(self) except? -1 cdef libc.stdint.int32_t _load_int(self) except? -1 cdef libc.stdint.int64_t _load_bigint(self) except? -1 cdef float _load_float(self) except? -1 cdef double _load_double(self) except? -1 cdef bytes _load_bytes(self) |
Operation Cython Implementation
Similarly to coder, We will add two python files to support Cython implementation of Operation.
- fast_operations.pxd
- fast_operations.pyx
fast_operations.pxd will define the corresponding declaration of Operations and fast_operations.pyx will provide specific implementation.
# fast_operations.pxd cdef class StatelessFunctionOperation(Operation): cdef Operation consumer cdef StreamCoderImpl _value_coder_impl cdef dict variable_dict cdef list user_defined_funcs cdef libc.stdint.int32_t _func_num cdef libc.stdint.int32_t _constant_num cdef object func cpdef generate_func(self, udfs) @cython.locals(func_args=str, func_name=str) cpdef str _extract_user_defined_function(self, user_defined_function_proto) @cython.locals(args_str=list) cpdef str _extract_user_defined_function_args(self, args) @cython.locals(j_type=libc.stdint.int32_t, constant_value_name=str) cpdef str _parse_constant_value(self, constant_value) cdef class ScalarFunctionOperation(StatelessFunctionOperation): pass cdef class TableFunctionOperation(StatelessFunctionOperation): pass |
Pipeline of Building Wheel Packages
We need to add a pipeline to build python wheel packages to Azure CI of Flink.
# build-python-wheels.yml # 1. compile Flink source code jobs: - job compie - script: STAGE=compile ${{parameters.environment}} ./tools/azure_controller.sh compile displayName: Build - task: PublishPipelineArtifact@1 inputs: path: $(CACHE_FLINK_DIR) artifact: FlinkCompileCacheDir-${{parameters.stage_name}} # 2. build wheel packages - job: BuildWheels dependsOn: compile_${{parameters.stage_name}} strategy: matrix: linux: vm-label: 'ubuntu-16.04' mac: vm-label: 'macOS-10.15' pool: vmImage: $(vm-label) steps: # download artifacts - task: DownloadPipelineArtifact@2 inputs: path: $(CACHE_FLINK_DIR) artifact: FlinkCompileCacheDir-${{parameters.stage_name}} # recreate "build-target" symlink for python tests - script: | mkdir -p flink-dist/target/flink-$(VERSION)-bin ln -snf $(CACHE_FLINK_DIR)/flink-dist/target/flink-$(VERSION)-bin/flink-$(VERSION) `pwd`/flink-dist/target/flink-$(VERSION)-bin/flink-$(VERSION) displayName: Recreate 'build-target' symlink - script: | cd flink-python bash dev/build-wheels.sh displayName: Build wheels - task: PublishPipelineArtifact@0 inputs: artifactName: 'wheel_$(Agent.OS)_$(Agent.JobName)' targetPath: 'flink-python/dist' |
We will include the build-python-wheels.yml into the nightly builds, so that we can collect daily build wheel packages information
/tools/azure-pipelines/build-apache-repo.yml jobs: - stage: cron_build … # other jobs - template: build-python-wheels.yml # Add a job of building wheel packages |
When a new release is released, we will manually trigger a nightly build on the release branch. After that, we can download the wheel packages and push them to PyPI.
Compatibility, Deprecation, and Migration Plan
This FLIP won’t destroy compatibility.
Implementation Plan
- Support coder Cython implementation
- Support operation Cython implementation
- Add building wheel packages to Azure CI
[1] https://ci.apache.org/projects/flink/flink-docs-master/flinkDev/building.html#build-pyflink
Authors: Xingbo Huang, Robert Metzger, Jincheng Sun
Status
Current state: Released
Discussion thread: http://apache-flink-mailing-list-archive.1008284.n3.nabble.com/DISCUSS-FLIP-121-Support-Cython-Optimizing-Python-User-Defined-Function-tt39577.html
JIRA:
Released: 1.11
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Scalar Python UDF (FLIP-58) has already been supported in release 1.10 and Python UDTF will be supported in the coming release of 1.11. In release 1.10, we focused on supporting UDF features and did not make many optimizations in terms of performance. Although we have made a lot of optimizations in master, Cython can further greatly improve the performance of Python UDF.
Background
Cython is an optimizing static compiler for both the Python programming language and the extended Cython programming language (based on Pyrex). It makes writing C extensions for Python as easy as Python itself.
Examples
We can write an easy example to understand the difference between Cython and your module created with Python.
This example (from Cython official web) is about the integration of the function f (x) in [a, b].
# Pure Python Code def f(x): return x ** 2 - x def integrate_f(a, b, N): s = 0 dx = (b - a) / N for i in range(N): s += f(a + i * dx) return s * dx |
# Cython Code cdef double f(double x): return x ** 2 - x cpdef integrate_f(double a, double b, int N): cdef int i cdef double s, dx s = 0 dx = (b - a) / N for i in range(N): s += f(a + i * dx) return s * dx |
Check out the table below which shows how much speed Cython gave us for different number function calls. We got over 150X speedup with Cython!
nCalls | Pure code time(s) | Cython Code time(s) | Speedup |
10000 | 2.165466 | 0.012378 | 174x |
50000 | 10.803928 | 0.061041 | 176x |
100000 | 21.277053 | 0.114681 | 185x |
200000 | 41.897756 | 0.219027 | 191x |
500000 | 105.50863 | 0.544354 | 193x |
1000000 | 218.101658 | 1.07485 | 202x |
As we can see, although the syntax of Cython is similar to python, Cython can bring huge performance improvements.
Proposed Changes
Overview
- Introduces Cython implementation of coder and operations
- Doc changes for building sdist and wheel packages from source code
- Solutions for packages building
Introduce Cython Implementation of Coder and Operations
Workflow of Processing Data
As we can see from the workflow,
- PVM is bottleneck because PVM is much slower than JVM in performance
- The bundle_processor is part of Beam Portability Framework utilized by PyFlink. Beam has done a lot of optimizations on it, so this part is not the part we need to optimize.
- We can optimize the Coder and Python User-Defined Operations modules to improve our performance.
By optimizing the data structure and algorithm logic used by these two modules, compared to PyFlink 1.10, we have optimized about 5X.
If we use Cython, we can optimize 6X on the basis of master code. Compared to PyFlink 1.10, it is optimized by 30X.
Performance Improvements
Next, let's take a look at the test code we used and compare it with the detailed test performance data of release-1.10, master and code optimized with Cython.
Test Code
@udf(input_types=[DataTypes.INT(False)], result_type=DataTypes.INT(False))
|
End To End Performance comparison
Check out the table below which shows how much speed Cython gave us for different rows and columns test data. When there is only one column of data, the inc func is called once for each row of data, so all the overhead lies in the framework. When there are ten columns of data, the inc func will be called ten times for each row of data, Therefore, compared with the case of 10 rows and one column, the more time is spent in calculation, so the end-to-end promotion multiple is not as large as that of 10 rows and one column.
rows, columns | PyFlink 1.10 | master | master-Cython | Cython speedup (release-1.10) | Cython seedup (master) |
10kw, 1 | 2154s | 441s | 70s | 30X | 6x |
10kw, 10 | 5697s | 1221s | 254s | 22X | 5X |
From the data in the table and diagram, we can find that using Cython can greatly improve our performance.
Doc Changes for Building Sdist And Wheel Package From Source Code
Docs Changes for Building from Source Code
We need to add one step at the beginning to install the relational dependencies for compiling cython code in the progress of building sdist and wheel packages in building from source code doc page[1].
cd flink-python # pip install dependencies pip install -r dev/requirements.txt |
Next, we can build sdist and wheel package in flink-python directory
python setup.py sdist bdist_wheel |
The sdist and wheel package will be found under ./flink-python/dist/. Either of them could be used for pip installation, such as:
python -m pip install dist/*.tar.gz |
Release Changes for Deploy Python artifacts to PyPI
We need to add a step to download wheels from the Artifacts page of the Azure Pipeline built results and upload corresponding wheels to PyPI[2].
# 1. Downloads wheels from Azure Artifacts
# 2. Put the downloaded wheel packages in dist folder of flink-python module cd flink-python mkdir dist(optional) ## move all downloaded wheel packages to the dist folder(manually) # 3. Run the supported script to restore executable permission ## Script files in packages downloaded from Azure will lose executable permissions dev/restore-executable.sh #3 Upload the wheel packages to PyPI, e.g. twine upload --repository-url https://upload.pypi.org/legacy/ dist/*.whl |
Solutions For Packages Building
After the introduction of cython, in addition to the sdist package installation, we will also provide the wheel package installation method.
After investigating some mainstream Python projects, we found that there are mainly the following three solutions for building cross platform wheel packages in PyFlink :
- Creates another project to build wheel packages. Apache-beam created a beam-wheels repository for the sole purpose of building wheel packages.
- Introduces github actions to build wheel packages.
- Adds building wheel packages logic to current Azure CI of Flink
Props | Cons | |
Solution 1 | We can learn from beam-wheels | 1. Beam have already discussed about to change this solution to github actions as solution 2 2. Need to create another repository |
Solution 2 | 1. Github actions comes with a strong level of integration with GitHub 2. We can build our wheel packages very simply by using many action tools,such as (actions/setup-java, actions/setup-python, actions/upload-artifact) | 1. It introduces another build CI system of github actions which increases the burden of maintaining 2. Github action is still very young |
Solution 3 | The logic of building wheel package could be integrated into the current Azure CI directly | N/A |
Solution 3 is preferred now as we already have built stable Azure CI in Flink and it is convenient to add the logic of building wheel packages to Azure CI.
Public Interfaces
Coder Cython Implementation
The current implementation of the coder is a pure python implementation.We will add two python files to support Cython implementation of coder.
- fast_coder_impl.pxd
- fast_coder_impl.pyx
fast_coder_impl.pxd will define the corresponding declaration of coder and fast_coder_impl.pyx will provide specific implementation.
# fast_coder_impl.pxd cdef class FlattenRowCoderImpl(StreamCoderImpl): cdef list _input_field_coders cdef list _output_field_coders cdef unsigned char* _input_field_type cdef unsigned char* _output_field_type cdef libc.stdint.int32_t _input_field_count cdef libc.stdint.int32_t _output_field_count cdef libc.stdint.int32_t _input_leading_complete_bytes_num cdef libc.stdint.int32_t _output_leading_complete_bytes_num cdef libc.stdint.int32_t _input_remaining_bits_num cdef libc.stdint.int32_t _output_remaining_bits_num cdef bint*_null_mask cdef unsigned char*_null_byte_search_table cdef char* _output_data cdef char* _output_row_data cdef size_t _output_buffer_size cdef size_t _output_row_buffer_size cdef size_t _output_pos cdef size_t _output_row_pos cdef size_t _input_pos cdef size_t _input_buffer_size cdef char* _input_data cdef list row cpdef _init_attribute(self) cdef _consume_input_data(self, WrapperInputElement wrapper_input_element, size_t size) cpdef _write_null_mask(self, value) cdef _read_null_mask(self) cdef _copy_before_data(self, WrapperFuncInputStream wrapper_stream, OutputStream out_stream) cdef _copy_after_data(self, OutputStream out_stream) cpdef _dump_field(self, unsigned char field_type, CoderType field_coder, item) cdef _dump_row(self) cdef _dump_byte(self, unsigned char val) cdef _dump_smallint(self, libc.stdint.int16_t v) cdef _dump_int(self, libc.stdint.int32_t v) cdef _dump_bigint(self, libc.stdint.int64_t v) cdef _dump_float(self, float v) cdef _dump_double(self, double v) cdef _dump_bytes(self, char*b) cpdef _load_row(self) cpdef _load_field(self, unsigned char field_type, CoderType field_coder) cdef unsigned char _load_byte(self) except? -1 cdef libc.stdint.int16_t _load_smallint(self) except? -1 cdef libc.stdint.int32_t _load_int(self) except? -1 cdef libc.stdint.int64_t _load_bigint(self) except? -1 cdef float _load_float(self) except? -1 cdef double _load_double(self) except? -1 cdef bytes _load_bytes(self) |
Operation Cython Implementation
Similarly to coder, We will add two python files to support Cython implementation of Operation.
- fast_operations.pxd
- fast_operations.pyx
fast_operations.pxd will define the corresponding declaration of Operations and fast_operations.pyx will provide specific implementation.
# fast_operations.pxd cdef class StatelessFunctionOperation(Operation): cdef Operation consumer cdef StreamCoderImpl _value_coder_impl cdef dict variable_dict cdef list user_defined_funcs cdef libc.stdint.int32_t _func_num cdef libc.stdint.int32_t _constant_num cdef object func cpdef generate_func(self, udfs) @cython.locals(func_args=str, func_name=str) cpdef str _extract_user_defined_function(self, user_defined_function_proto) @cython.locals(args_str=list) cpdef str _extract_user_defined_function_args(self, args) @cython.locals(j_type=libc.stdint.int32_t, constant_value_name=str) cpdef str _parse_constant_value(self, constant_value) cdef class ScalarFunctionOperation(StatelessFunctionOperation): pass cdef class TableFunctionOperation(StatelessFunctionOperation): pass |
Pipeline of Building Wheel Packages
We need to add a pipeline to build python wheel packages to Azure CI of Flink.
# build-python-wheels.yml # 1. compile Flink source code jobs: - job compie - script: STAGE=compile ${{parameters.environment}} ./tools/azure_controller.sh compile displayName: Build - task: PublishPipelineArtifact@1 inputs: path: $(CACHE_FLINK_DIR) artifact: FlinkCompileCacheDir-${{parameters.stage_name}} # 2. build wheel packages - job: BuildWheels dependsOn: compile_${{parameters.stage_name}} strategy: matrix: linux: vm-label: 'ubuntu-16.04' mac: vm-label: 'macOS-10.15' pool: vmImage: $(vm-label) steps: # download artifacts - task: DownloadPipelineArtifact@2 inputs: path: $(CACHE_FLINK_DIR) artifact: FlinkCompileCacheDir-${{parameters.stage_name}} # recreate "build-target" symlink for python tests - script: | mkdir -p flink-dist/target/flink-$(VERSION)-bin ln -snf $(CACHE_FLINK_DIR)/flink-dist/target/flink-$(VERSION)-bin/flink-$(VERSION) `pwd`/flink-dist/target/flink-$(VERSION)-bin/flink-$(VERSION) displayName: Recreate 'build-target' symlink - script: | cd flink-python bash dev/build-wheels.sh displayName: Build wheels - task: PublishPipelineArtifact@0 inputs: artifactName: 'wheel_$(Agent.OS)_$(Agent.JobName)' targetPath: 'flink-python/dist' |
We will include the build-python-wheels.yml into the nightly builds, so that we can collect daily build wheel packages information
/tools/azure-pipelines/build-apache-repo.yml jobs: - stage: cron_build … # other jobs - template: build-python-wheels.yml # Add a job of building wheel packages |
When a new release is released, we will manually trigger a nightly build on the release branch. After that, we can download the wheel packages and push them to PyPI.
Compatibility, Deprecation, and Migration Plan
This FLIP won’t destroy compatibility.
Implementation Plan
- Support coder Cython implementation
- Support operation Cython implementation
- Add building wheel packages to Azure CI
[1] https://ci.apache.org/projects/flink/flink-docs-master/flinkDev/building.html#build-pyflink