THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
...
PartitionRecord and PartitionChangeRecord will both have a new Assignment field which replaces the current Replicas field: Directories field
{ "name": "ReplicasDirectories", "type": "[]int32uuid", "versions": "0", "entityType": "brokerId""1+",
"about": "The replicaslog directory ofhosting thiseach partitionreplica, sorted in the bysame preferredexact order as the Replicas field." },
(...)
{ "name": "Assignment", "type": "[]ReplicaAssignment", "versions": "1+",
"about": "The replicas of this partition, sorted by preferred order.", "fields": [
{ "name": "Broker", "type": "int32", "versions": "1+", "entityType": "brokerId",
"about": "The broker ID hosting the replica." },
{ "name": "Directory", "type": "uuid", "versions": "1+",
"about": "The log directory hosting the replica" }
]}}
Although not explicitly specified in the schema, the default value for Directory is Uuid.UNASSIGNED_DIR (Uuid.ZERO), as thatAlthough not explicitly specified in the schema, the default value for Directory is Uuid.UNASSIGNED_DIR (Uuid.ZERO), as that's the default default value for UUID types.
...
A AssignReplicasToDirs request including an assignment to Uuid.LOST_DIR conveys that the Broker is wanting to correct a replica assignment into a offline log directory, which cannot be identified.
This request is authorized with CLUSTER_ACTION on CLUSTER.
Proposed changes
Metrics
| MBean name | Description |
|---|---|
| kafka.server:type=KafkaServer,name=QueuedReplicaToDirAssignments | The number of replicas hosted by the broker that are either missing a log directory assignment in the cluster metadata or are currently found in a different log directory and are queued to be sent to the controller in a |
...
Currently, Replicas are considered offline if the hosting broker is offline. Additionally, replicas will also be considered offline if the replica references a log directory UUID (in the new field partitionRecord.Assignment.DirectoryDirectories) that is not present in the hosting Broker's latest registration under LogDirs and either:
...
When multiple log directories are configured, and some (but not all) of them become offline, the broker will communicate this change using the new field OfflineLogDirs in the BrokerHeartbeat request — indicating the UUIDs of the new offline log directories. The UUIDs for the newly failed log directories are included in the BrokerHeartbeat request until the broker receives a successful response. If the Broker is configured with a single log directory, this field isn't used, as the current behavior of the broker is to shutdown when no log directories are online.this change using the new field OfflineLogDirs in the BrokerHeartbeat request — indicating the UUIDs of the new offline log directories. The UUIDs for the accumulated failed log directories are included in every BrokerHeartbeat request until the broker restarts. If the Broker is configured with a single log directory, this field isn't used, as the current behavior of the broker is to shutdown when no log directories are online.
Log directory failure notifications are queued and batched together in all future broker heartbeat requestsLog directory failure notifications are queued and batched together in the next broker heartbeat request. If there are any queued partition-to-directory assignments — sent in AssignReplicasToDirs — to send to the controller, those that are respective to any of the newly failed log directories (i.e. assignments that are either into or out-of these directories) are prioritized and sent first. The broker retries these until it receives a successful reply, which conveys that the metadata change has been successfully persisted. This ensures that the Controller is in sync with regards to partition-to-directory assignments and can reliably determine which partitions need leadership and ISR update.
If the Broker repeatedly fails to communicate a log directory failure, or a replica assignment into a failed directory, after a configurable amount of time — log.dir.failure.timeout.ms — and it is the leader for any replicas in the failed log directory the broker will shutdown, as that is the only other way to guarantee that the controller will elect a new leader for those partitions.
...
When configured with multiple log.dirs, as the broker catches up with metadata, and sees the partitions which it should be hosting, it will check the associated log directory UUID for each partition (partitionRecord.Assignment.DirectoryDirectories).
- If the partition is not assigned to a log directory (refers to
Uuid.UNASSIGNED_DIR)- If the partition already exists, the broker uses the new RPC —
AssignReplicasToDirs— to notify the controller to change the metadata assignment to the actual log directory. - If the partition does not exist, the broker selects a log directory and uses the new RPC —
AssignReplicasToDirs— to notify the controller to create the metadata assignment to the actual log directory.
- If the partition already exists, the broker uses the new RPC —
- If the partition is assigned to an online log directory
- If the partition does not exist it is created in the indicated log directory.
- If the partition already exists in the indicated log directory and no future replica exists, then no action is taken.
- If the partition already exists in the indicated log directory, and there is a future replica in another log directory, then the broker starts the process to replicate the current replica to the future replica.
- If the partition already exists in another online log directory and is a future replica in the log directory indicated by the metadata, the broker will replace the current replica with the future replica after making sure that the future replica is fully caught up with the current replica.
- If the partition already exists in another online log directory, the broker uses the new RPC —
AssignReplicasToDirs— to the controller to change the metadata assignment to the actual log directory. The partition might have been moved to a different log directory whilst the broker was offline.
- If the partition is assigned to an unknown log directory or refers to
Uuid.LOST_DIR- If there are offline log directories, no action is taken — the assignment refers to a a log directory which may be offline, we don't want to fill the remaining online log directories with replicas that existed in the offline ones.
- If there are no offline directories, the broker selects a log directory and uses the new RPC —
AssignReplicasToDirs— to notify the controller to create the metadata assignment to the actual log directory.
...
The existing AlterReplicaLogDirs RPC is sent directly to the broker in question, which starts moving the replicas using a AlterReplicaLogDirs threads – ReplicaAlterLogDirsThread – this remains unchanged. But when the future replica first catches up with the main replica, instead of immediately promoting the future replica, the broker will:
- Asynchronously communicate the log directory change to the controller using the new RPC –
AssignReplicasToDirs. - Keep the
AlterReplicaLogDirsthread goingReplicaAlterLogDirsThreadgoing. The future replica is still the future replica, and it continues to copy from the main replica – which still in the original log directory – as new records are appended.
...
The diagram below illustrates the sequence of steps involved in moving a replica between log directories.

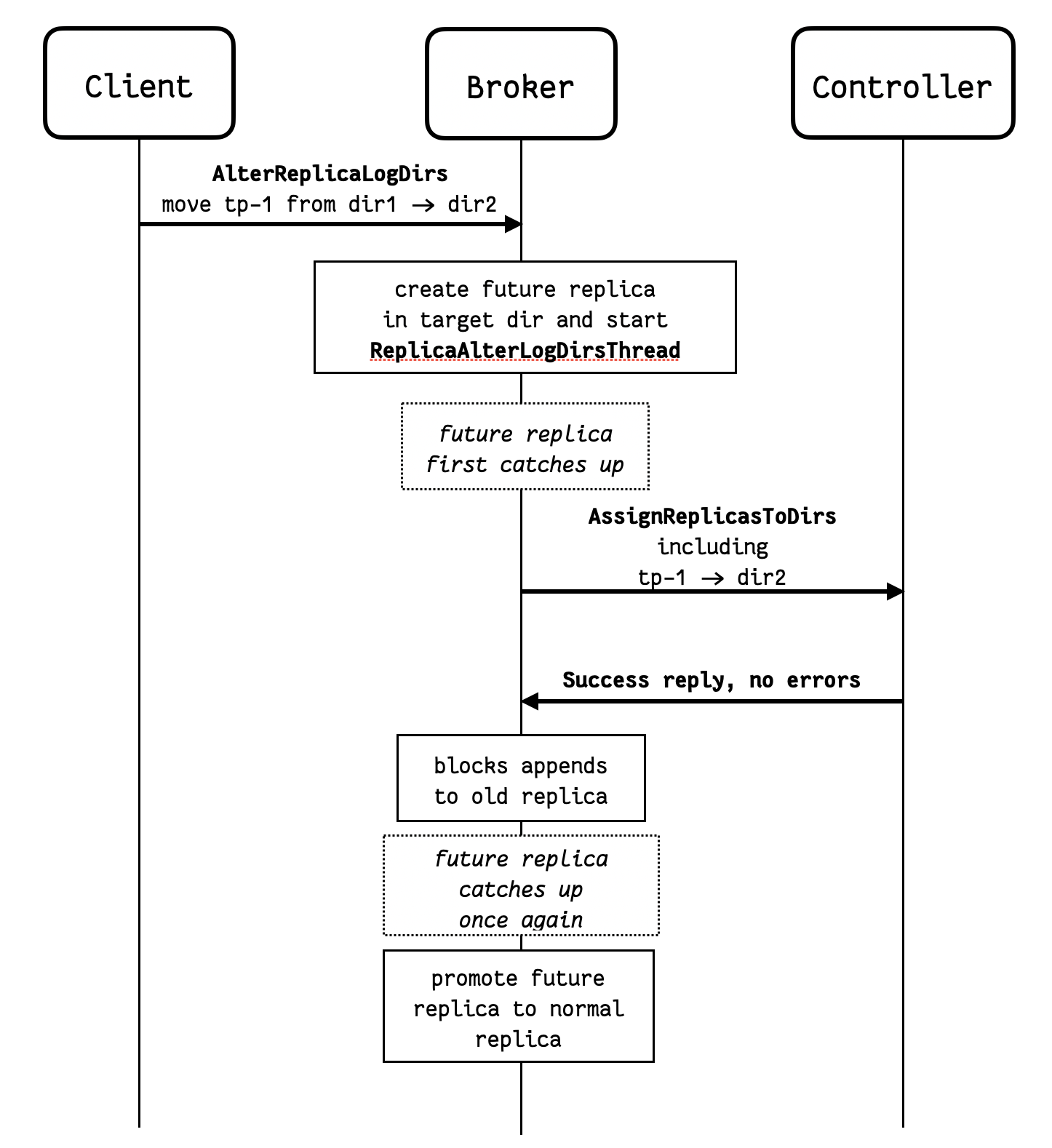
In the diagram above, notice that if dir1 fails after the AssignReplicasToDirs RPC is sent, but before the future replica is promoted, then the controller will not know to update leadership and ISR for the partition. If the destination directory has failed, it won't be possible to promote the future replica, and the Broker needs to revert the assignment (cancelled locally if still queued). If the source directory has failed, then the future replica might not catch up, and the Controller might not update leadership and ISR for the partition. In this exceptional case, the broker issues a AssignReplicasToDirs RPC to the Controller to assignment the replica to UUID.LOST_DIR - this lets the Controller know that it needs to update leadership and ISR for this partition too.
...
- As per KIP-866, a separate Controller quorum is setup first, and only then the existing brokers are reconfigured and upgraded.
- When configured for the migration and while still in ZK mode, brokers will:
- update meta.properties to generate and include
directory.id; - send
BrokerRegistrationRequestincluding the log directory UUIDs; - shutdown if any directory fails;
- sends assignments via the
AssignReplicasToDirsRPCnotify the controller of log directory failures via BrokerHeartbeatRequest.
- update meta.properties to generate and include
- During the migration, the controller:
- persists log directories indicated in broker registration requests in the cluster metadata;
- relies on heartbeat requests to detect log directory failure instead of monitoring the ZK znode for notifications;
- still uses full
LeaderAndIsrrequests to process log directory failures for any brokers still running in ZK modepersists directory assignments received via theAssignReplicasToDirsRPC.
- The brokers restarting into KRaft mode will want to stay fenced until their log directory assignments for all hosted partitions are persisted in the cluster metadata.
- The active controller will also ensure that any given broker stays fenced until it learns of all partition to log directory assignments in that specific broker via the new
AssignReplicasToDirsRPC. - During the migration, existing replicas are assumed and assigned to log directory
Uuid.MIGRATING_DIRuntil the actual log directory is learnt by the active controller from a broker running in KRaft mode.
...