THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
- General Questions
- Contents
- How do I get started with Tapestry?
- Why does Tapestry use Prototype (in versions before 5.4)? Why not insert favorite JavaScript library here?
- Why does Tapestry have its own Inversion of Control Container? Why not Spring or Guice?
- How do I upgrade from Tapestry 4 to Tapestry 5?
- How do I upgrade from one version of Tapestry 5 to another?
- Why are there both Request and HttpServletRequest?
- Templating and Markup
- Contents
- Why do I get a SAXParseException when I use an HTML entity, such as in my template?
- Why do some images in my page show up as broken links?
- What's the difference between id and t:id?
- Why do my images and stylesheets end up with a weird URLs like /assets/meta/zeea17aee26bc0cae/layout/layout.css?
- How do I add a CSS class to a Tapestry component?
- Page And Component Classes
- Contents
- What's the difference between a page and a component?
- How do I store my page classes in a different package?
- Why do my instance variables have to be private?
- Why don't my informal parameters show up in the rendered markup?
- Why do I get java.lang.LinkageError when I invoke public methods of my page classes?
- Which is better, using magic method names (i.e., beginRender()) or annotations (i.e. BeginRender)?
- Why do I have to inject a page? Why can't I just create one using new?
- Link Components
- JavaScript
- Ajax Components
- Contents
- Do I have to specify both id and t:id for Zone components?
- How do I update the content of a Zone from an event handler method?
- How to I update multiple zones in a single event handler?
- What's that weird number in the middle of the client ids after a Zone is updated?
- Why do I sometimes get the exception "The rendered content did not include any elements that allow for the positioning of the hidden form field's element." when rendering an empty Zone?
- Injection
- Contents
- What's the difference between the @Component and @InjectComponent annotations?
- What's the difference between the @InjectPage and @InjectContainer annotations?
- I get an exception because I have two services with the same interface, how do I handle this?
- What's the difference between @Inject and @Environmental?
- But wait ... I see I used the @Inject annotation and it still worked. What gives?
- Ok, but Request is a singleton service, not an environmental, and I can inject that. Is Tapestry really thread safe?
- I use @Inject on a field to inject a service, but the field is still null, what happened?
- Tapestry Inversion of Control Container
- Integration with existing applications
- Limitations
- Hibernate Support
- Maven Support
General Questions
Contents
- How do I get started with Tapestry?
- Why does Tapestry use Prototype (in versions before 5.4)? Why not insert favorite JavaScript library here?
- Why does Tapestry have its own Inversion of Control Container? Why not Spring or Guice?
- How do I upgrade from Tapestry 4 to Tapestry 5?
- How do I upgrade from one version of Tapestry 5 to another?
- Why are there both Request and HttpServletRequest?
How do I get started with Tapestry?
The easiest way to get started is to use Apache Maven to create your initial project; Maven can use an archetype (a kind of project template) to create a bare-bones Tapestry application for you. See the Getting Started page for more details.
Even without Maven, Tapestry is quite easy to set up. You just need to download the binaries and setup your build to place them inside your WAR's WEB-INF/lib folder. The rest is just some one-time configuration of the web.xml deployment descriptor.
Why does Tapestry use Prototype (in versions before 5.4)? Why not insert favorite JavaScript library here?
An important goal for Tapestry is seamless DHTML and Ajax integration. To serve that goal, it was important that the built in components be capable of Ajax operations, such as dynamically re-rendering parts of the page. Because of that, it made sense to bundle a well-known JavaScript library as part of Tapestry.
At the time (this would be 2006-ish), Prototype and Scriptaculous were well known and well documented, whereas jQuery was just getting started.
The intent has always been to make this aspect of Tapestry pluggable. Tapestry 5.4 includes the option of either Prototype or jQuery, and future versions of Tapestry will likely remove Prototype as an option..
Why does Tapestry have its own Inversion of Control Container? Why not Spring or Guice?
An Inversion of Control Container is the key piece of Tapestry's infrastructure. It is absolutely necessary to create software as robust, performant and extensible as Tapestry.
Tapestry IoC includes a number of features that distinguish itself from other containers:
- Configured in code, not XML
- Built-in extension mechanism for services: configurations and contributions
- Built-in aspect oriented programming model (service decorations and advice)
- Easy modularization
- Best-of-breed exception reporting
Because Tapestry is implemented on top of its IoC container, and because the container makes it easy to extend or replace any service inside the container, it is possible to make the small changes to Tapestry needed to customize it to any project's needs.
In addition – and this is critical – Tapestry allows 3rd party libraries to be built that fully participate in the configurability of Tapestry itself. This means that such libraries can be configured the same way Tapestry itself is configured, and such libraries can also configure Tapestry itself. This distributed configuration requires an IOC container that fully supports such configurability.
How do I upgrade from Tapestry 4 to Tapestry 5?
There is no existing tool that supports upgrading from Tapestry 4 to Tapestry 5; Tapestry 5 is a complete rewrite.
Many of the basic concepts in Tapestry 4 are still present in Tapestry 5, but refactored, improved, streamlined, and simplified. The basic concept of pages, templates and components are largely the same. Other aspects, such as server-side event handling, is markedly different.
Tapestry 5 is designed so that it can live side-by-side in the same servlet as a Tapestry 4 app, without package namespace conflicts, sharing session data and common resources such as images and CSS. This means that you can gradually migrate a Tapestry 4 app to Tapestry 5 one page (or one portion of the app) at a time.
How do I upgrade from one version of Tapestry 5 to another?
Main Article: How to Upgrade.
A lot of effort goes into making an upgrade from one Tapestry 5 release to another go smoothly. In the general case, it is just a matter of updating the version number in your Maven build.xml or Gradle build.gradle file and executing the appropriate commands (e.g., gradle idea or mvn eclipse:eclipse) to bring your local workspace up to date with the latest binaries.
After changing dependencies, you should always perform a clean recompile of your application.
We make every effort to ensure backwards-compatibility. Tapestry is mostly coded in terms of interfaces; those interfaces are stable to a point: interfaces your code is expected to implement are usually completely frozen; interfaces your code is expected to invoke, such as the interfaces to IoC services, are stable, but may have new methods added in a release; existing methods are not changed.
In rare cases a choice is necessary between fixing bugs (or adding essential functionality) and maintaining complete backwards compatibility; in those cases, an incompatible change may be introduced. These are always discussed in detail in the Release Notes for the specific release. You should always read the release notes before attempting an upgrade, and always (really, always) be prepared to retest your application afterwards.
Note that you should be careful any time you make use of internal APIs (you can tell an API is internal by the package name, org.apache.tapestry5.internal). Internal APIs may change at any time; there's no guarantee of backwards compatibility. Please always check on the documentation, or consult the user mailing list, to see if there's a stable, public alternative. If you do make use of internal APIs, be sure to get a discussion going so that your needs can be met in the future by a stable, public API.
Why are there both Request and HttpServletRequest?
Tapestry's Request interface is very close to the standard HttpServletRequest interface. It differs in a few ways, omitting some unneeded methods, and adding a couple of new methods (such as isXHR()), as well as changing how some existing methods operate. For example, getParameterNames() returns a sorted List of Strings; HttpServletRequest returns an Enumeration, which is a very dated approach.
However, the stronger reason for Request (and the related interfaces Response and Session) is to enable the support for Portlets at some point in the future. By writing code in terms of Tapestry's Request, and not HttpServletRequest, you can be assured that the same code will operate in both Servlet Tapestry and Portlet Tapestry.
Templating and Markup
Main Article: Component Templates
Contents
- Why do I get a SAXParseException when I use an HTML entity, such as in my template?
- Why do some images in my page show up as broken links?
- What's the difference between id and t:id?
- Why do my images and stylesheets end up with a weird URLs like /assets/meta/zeea17aee26bc0cae/layout/layout.css?
- How do I add a CSS class to a Tapestry component?
Why do I get a SAXParseException when I use an HTML entity, such as in my template?
Tapestry uses a standard SAX parser to read your templates. This means that your templates must be well formed: open and close tags must balance, attribute values must be quoted, and entities must be declared. The easiest way to accomplish this is to add a DOCTYPE to your the top of your template:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
Part of the DOCTYPE is the declaration of entities such as .
Alternately, you can simply use the numeric version:   This is the exact same character and will render identically in the browser.
Starting in release 5.3, Tapestry introduces an XHTML doctype when no doctype is present; this means that common HTML entities will work correctly.
Why do some images in my page show up as broken links?
You have to be careful when using relative URLs inside page templates; the base URL may not always be what you expect. For example, inside your ViewUser.tml file, you may have:
<img class="icon" src="icons/admin.png"/>${user.name} has Administrative access
This makes sense; ViewUser.tml is in the web context, as is the icons folder. The default URL for this page will be /viewuser (assuming that ViewUser class is in the root-package.pages package).
However, the ViewUser page might use a page activation context to identify which user is to be displayed:
public class ViewUser @Property @PageActivationContext private User user; . . .
With a page activation context, the URL for the page will incorporate the ID of the User object, something like /viewuser/37371. This is why the relative URL to the admin.png image is broken: the base path is relative to the page's URL, not to the page template. (In fact, the page template may not even be in the web context, it may be stored on the classpath, as component templates are.)
One solution would be to predict what the page URL will be, and adjust the path for that:
<img class="icon" src="../icons/admin.png"/>${user.name} has Administrative access
But this has its own problems; the page activation context may vary in length at different times, or the template in question may be a component used across many different pages, making it difficult to predict what the correct relative URL would be.
The best solution for this situation, one that will be sure to work in all pages and all components, is to make use of the context: binding prefix:
<img class="icon" src="${context:icons/admin.png}"/>${user.name} has Administrative access
The src attribute of the <img> tag will now be bound to a dynamically computed value: the location of the image file relative to the web application context. This is especially important for components that may be used on different pages.
What's the difference between id and t:id?
You might occasionally see something like the following in a template:
<t:zone id="status" t:id="statusZone">
Why two ids? Why are they different?
The t:id attribute is the Tapestry component id. This id is unique within its immediate container. This is the id you might use to inject the component into your page class:
@InjectComponent private Zone statusZone;
The other id is the client id, a unique id for the rendered element within the client-side DOM. JavaScript that needs to access the element uses this id. For example:
$('status').hide();
In many components, the id attribute is an informal parameter; a value from the template that is blindly echoed into the output document. In other cases, the component itself has an id attribute. Often, in the latter case, the Tapestry component id is the default value for the client id.
Why do my images and stylesheets end up with a weird URLs like /assets/meta/zeea17aee26bc0cae/layout/layout.css?
Tapestry doesn't rely on the servlet container to serve up your static assets (images, stylesheets, flash movies, etc.). Instead, Tapestry processes the requests itself, streaming assets to the browser.
Asset content will be GZIP compressed (if the client supports compression, and the content is compressible). In addition, Tapestry will set a far-future expires header on the content. This means that the browser will not ask for the file again, greatly reducing network traffic.
The weird hex string is a fingerprint; it is a hash code computed from the actual content of the asset. If the asset ever changes, it will have a new fingerprint, and so will be a new path and a new (immutable) resource. This approach, combined with a far-future expires header also provided by Tapestry, ensures that clients aggressively cache assets as they navigate your site, or even between visits.
How do I add a CSS class to a Tapestry component?
As they say, "just do it". The majority of Tapestry components support informal parameters, meaning that any extra attributes in the element (in the template) will be rendered out as additional attributes. So, you can apply a CSS class or style quite easily:
<t:textfield t:id="username" class="big-green"/>
You can even use template expansions inside the attribute value:
<t:textfield t:id="username" class="${usernameClass}"/>
and
public String getUsernameClass()
{
return isUrgent() ? "urgent" : null;
}
When an informal parameter is bound to null, then the attribute is not written out at all.
You can verify which components support informal parameters by checking the component reference, or looking for the @SupportsInformalParameters annotation in the components' source file.
Page And Component Classes
Main article: Component Classes
Contents
- What's the difference between a page and a component?
- How do I store my page classes in a different package?
- Why do my instance variables have to be private?
- Why don't my informal parameters show up in the rendered markup?
- Why do I get java.lang.LinkageError when I invoke public methods of my page classes?
- Which is better, using magic method names (i.e., beginRender()) or annotations (i.e. BeginRender)?
- Why do I have to inject a page? Why can't I just create one using new?
What's the difference between a page and a component?
There's very little difference between the two. Pages classes must be in the root-package.pages package; components must be in the root-package.components. Pages may provide event handlers for certain page-specific events (such as activate and passivate). Components may have parameters.
Other than that, they are more equal than they are different. They may have templates or may render themselves in code (pages usually have a template, components are more likely to render only in code).
The major difference is that Tapestry page templates may be stored in the web context directory, as if they were static files (they can't be accessed from the client however; a specific rule prevents access to files with the .tml extension).
It is possible that this feature may be removed in a later release. It is preferred that page templates be stored on the classpath, like component templates.
How do I store my page classes in a different package?
Tapestry is very rigid here; you can't. Page classes must go in root-package.pages, component classes in root-package.components, etc.
You are allowed to create sub-packages, to help organize your code better and more logically. For example, you might have root-package.pages.account.ViewAccount, which would have the page name "account/viewaccount". (Tapestry would also create an alias "account/view", by stripping off the redundant "account" suffix. Either name is equally valid in your code, and Tapestry will use the shorter name, "account/view" in URLs.)
In addition, it is possible to define additional root packages for the application:
public static void contributeComponentClassResolver(Configuration<LibraryMapping> configuration) {
configuration.add(new LibraryMapping("", "com.example.app.tasks"));
configuration.add(new LibraryMapping("", "com.example.app.chat"));
}
LibraryMappings are used to resolve a library prefix to one or more package names. The empty string represents the application itself; the above example adds two additional root packages; you might see additional pages under com.example.app.tasks.pages, for example.
Tapestry doesn't check for name collisions, and the order the packages are searched for pages and components is not defined. In general, if you can get by with a single root package for your application, that is better.
Why do my instance variables have to be private?
In Tapestry 5.3.1 and earlier all instance variables must be private. Starting in version 5.3.2 instance variables can also be protected or package private (that is, not public), or they can even be public if final or annotated with the deprecated @Retain.
Tapestry does a large amount of transformation to your simple POJO classes as it loads them into memory. In many cases, it must locate every read or write of an instance variable and change its behavior; for example, reading a field that is a component parameter will cause a property of the containing page or component to be read.
Restricting the scope of fields allows Tapestry to do the necessary processing one class at a time, as needed, at runtime. More complex Aspect Orient Programming systems such as AspectJ can perform similar transformations (and much more complex ones), but they require a dedicated build step (or the introduction of a JVM agent).
Why don't my informal parameters show up in the rendered markup?
Getting informal parameters to work is in two steps. First, you must make a call to the ComponentResources.renderInformalParameters() method, but just as importantly, you must tell Tapestry that you want the component to support informal parameters, using the SupportsInformalParameters annotation. Here's a hypothetical component that displays an image based on the value of a Image object (presumably, a database entity):
@SupportsInformalParameters
public class DBImage
{
@Parameter(required=true)
private Image image;
@Inject
private ComponentResources resources;
boolean beginRender(MarkupWriter writer)
{
writer.element("img", "src", image.toClientURL(), "class", "db-image");
resources.renderInformalParameters(writer);
writer.end();
return false;
}
}
Why do I get java.lang.LinkageError when I invoke public methods of my page classes?
In Tapestry, there are always two versions of page (or component) classes. The first version is the version loaded by standard class loader: the simple POJO version that you wrote.
The second version is much more complicated; it's the transformed version of your code, with lots of extra hooks and changes to allow the class to operate inside Tapestry. This includes implementing new interfaces and methods, adding new constructors, and changing access to existing fields and methods.
Although these two classes have the same fully qualified class name, they are distinct classes because they are loaded by different class loaders.
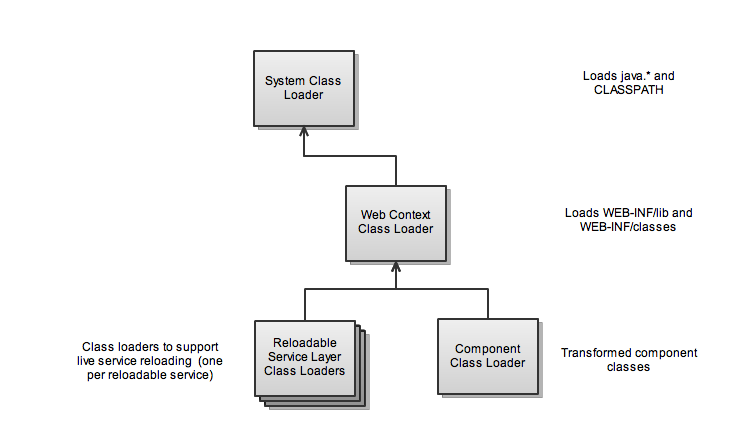
In a Tapestry application, most application classes are loaded from the middle class loader. Additional class loaders are used
to support live service reloading, and live component reloading (along with component class transformation).
When a page or component is passed as a parameter to a service, a failure occurs (how it is reported varies in different JDK releases) because of the class mismatch.
The solution is to define an interface with the methods that the service will invoke on the page or component instance. The service will expect an object implementing the interface (and doesn't care what class loader loaded the implementing class).
Just be sure to put the interface class in a non-controlled package, such as your application's root-package (and not root-package.pages).
Which is better, using magic method names (i.e., beginRender()) or annotations (i.e. BeginRender)?
There is no single best way; this is where your taste may vary. Historically, the annotations came first, and the method naming conventions came later.
The advantage of using the method naming conventions is that the method names are more concise, which fewer characters to type, and fewer classes to import.
The main disadvantage of the method naming conventions is that the method names are not meaningful. onSuccessFromLoginForm() is a less meaningful name than storeUserCredentialsAndReturnToProductsPage(), for example.
The second disadvantage is you are more susceptible to off-by-a-character errors. For example, onSucessFromLoginForm() will never be called because the event name is misspelled; this would not happen using the annotation approach:
@OnEvent(value=EventConstants.SUCCESS, component="loginForm")
Object storeUserCredentialsAndReturnToProductsPage()
{
. . .
}
The compiler will catch a misspelling of the constant SUCCESS. Likewise, local constants can be defined for key components, such as "loginForm".
Ultimately, it's developer choice. HLS prefers the method naming conventions in nearly all cases, especially prototypes and demos, but can see that in some projects and some teams, an annotation-only approach is best.
Why do I have to inject a page? Why can't I just create one using new?
Tapestry tranforms your class at runtime. It tends to build a large constructor for the class instance. Further, an instance of the class is useless by itself, it must be wired together with its template and its sub-components.
On top of that, Tapestry keeps just once instance of each page in memory (since 5.2). It reworks the bytecode of the components so that a single instance can be shared across multiple request handling threads.
____
This page has moved to Forms and Form Components FAQ
Link Components
Main Articles: Page Navigation, Component Parameters
Contents
How do I add query parameters to a PageLink or ActionLink?
These components do not have parameters to allow you to specify query parameters for the link; they both allow you to specify a context (one or more values to encode into the request path).
However, you can accomplish the same thing with a little code and markup. For example, to create a link to another page and pass a query parameter, you can replace your PageLink component with a standard <a> tag:
<a href="${profilePageLink}">Display Profile (w/ full details)</a>
In the matching Java class, you can create the Link programmatically:
@Inject
private PageRenderLinkSource linkSource;
public Link getProfilePageLink()
{
Link link = linkSource.createPageRenderLinkWithContext(DisplayProfile.class, user);
link.addParameterValue("detail", true);
return link;
}
... and in the DisplayProfile page:
DisplayProfile.java (partial)
public class DisplayProfile
{
void onActivate(@RequestParameter("detail") boolean detail)
{
. . .
}
}
The @RequestParameter annotation directs Tapestry to extract the query parameter from the request and coerce it to type boolean. You can use any reasonable type for such a parameter (int, long and Date are common).
A similar technique can be used to add query parmeters to component event URLs (the type generated by the ActionLink or EventLink components), by injecting the ComponentResources, and invoking method createEventLink().
How do I create a Link back to the current page from a component?
Sometimes it is useful to create a link back to the current page, but you don't always know the name of the page (the link may appear inside a deeply nested subcomponent). Fortunately, this is easy.
<t:pagelink page="prop:componentResources.pageName">refresh page</t:pagelink>
Every component has an extra property, componentResources, added to it: it's the instance of ComponentResources that represents the link between your code and all of Tapestry's structure around your class. One of the properties of ComponentResources is pageName, the name of the page. By binding the PageLink's page parameter with the "prop:" binding prefix, we ensure that we bind to a computed property; this is necessary because the PageLink.page parameter defaults to the "literal:" binding prefix.
As an added benefit, if the page class is ever renamed or moved to a different package, the pageName property will automatically adjust to the new name.
JavaScript
Main articles: Client-Side JavaScript, Legacy JavaScript
Contents
Why do I get a "Tapestry is undefined" error on form submit? (5.3 and earlier)
This client-side error is clear but can be awkward to solve. It means your browser has not been able to load the tapestry.js file properly. The question is, why? It can be due to multiple reasons, some of them below:
- First, check if 'tapestry.js' is present in the head part of your resulting HTML page.
If you have set the tapestry.combine-scripts configuration symbol to true, Tapestry generates one single URL to retrieve all the JS files. Sometimes, this can produce long URLs that browsers are unable to retrieve. Try setting the symbol to false.
This only applies to Tapestry 5.1.
- If you have included jQuery in conjunction with Tapestry's prototype, that will cause a conflict with the '$' selector used by both. In this case, you should put jQuery on top of the stack and turn on the jQuery.noConflict mode.
- Also, if you have included a custom or third-party JS library on top of the stack that causes the JavaScript parsing to fail, then check the JavaScript syntax in that library.
- If you have used a tool to minimize your JavaScript libraries, this can lead to JavaScript syntax errors, so check if it works with all the JavaScript files unpacked.
What's the difference between the T5 object and the Tapestry object in the browser? (5.3 and earlier)
Both of these objects are namespaces: containers of functions, constants, and nested namespaces.
The T5 object is a replacement for the Tapestry object, starting in release 5.3. Increasingly, functions defined by the Tapestry object are being replaced with similar or equivalent functions in the T5 object.
This is part of an overall goal, spanning at least two releases of Tapestry, to make Tapestry JavaScript framework agnostic; which is to say, not depend specifically on Prototype or jQuery. Much of the code in the Tapestry object is specifically linked to Prototype and Scriptaculous.
The T5 object represents a stable, documented, set of APIs that are preferred when building components for maximum portability between underlying JavaScript frameworks. In other words, when building component libraries, coding to the T5 object ensures that your component will be useful regardless of whether the final application is built using Prototype, jQuery or something else.
Ajax Components
Main article: Ajax and Zones
Contents
- Do I have to specify both id and t:id for Zone components?
- How do I update the content of a Zone from an event handler method?
- How to I update multiple zones in a single event handler?
- What's that weird number in the middle of the client ids after a Zone is updated?
- Why do I sometimes get the exception "The rendered content did not include any elements that allow for the positioning of the hidden form field's element." when rendering an empty Zone?
Do I have to specify both id and t:id for Zone components?
The examples for the Zone component (in the Component Reference) consistently specify both id and t:id and this is probably a good idea.
Generally speaking, if you don't specify the client-side id (the id attribute), it will be the same as the Tapestry component id (t:id).
However, there are any number of exceptions to this rule. The Zone may be rendering inside a Loop (in which case, each rendering will have a unique client side id). The Zone may be rendering as part of a partial page render, in which case, a random unique id is inserted into the id. There are other examples where Tapestry component ids in nested components may also clash.
The point is, to be sure, specify the exact client id. This will be the value for the zone parameter of the triggering component (such as a Form, PageLink, ActionLink, etc.).
How do I update the content of a Zone from an event handler method?
When a client-side link or form triggers an update, the return value from the event handler method is used to construct a partial page response; this partial page response includes markup content that is used to update the Zone's client-side <div> element.
Where does that content come from? You inject it into your page.
<t:zone id="search" t:id="searchZone">
<t:form t:id="searchForm" zone="searchZone">
<t:textfield t:id="query" size="20"/>
<input type="submit" value="Search"/>
</t:form>
</t:zone>
<t:block id="searchResults">
<ul>
<li t:type="loop" source="searchHits" value="searchHit">${searchHit}</li>
</ul>
</t:block>
@Inject
private Block searchResults;
Object onSuccessFromSearchForm()
{
searchHits = searchService.performSearch(query);
return searchResults;
}
So, when the search form is submitted, the resulting search hits are collected. In the same request, the searchResults block is rendered, package, and sent to the client. The form inside the client-side Zone <div> is replaced with the list of hits.
In many cases, you just want to re-render the Zone itself, to display updated content. In that case, you don't need a separate <t:block>, instead you can use @InjectComponent to inject the Zone object itself, and return the Zone's body:
@InjectComponent
private Zone statusZone;
Object onActionFromUpdateStatus()
{
return statusZone.getBody();
}
How to I update multiple zones in a single event handler?
To do this, you must know, on the server, the client ids of each Zone. That's one of the reasons that you will generally set the Zone's client id (via the Zone's id parameter), rather than let Tapestry assign a client id for you.
From the event handler method, instead of returning a Block or a Component, return a multi-zone update:
Multiple Zone Update (5.3+)
@Inject
private Block searchResults;
@Inject
private Block statusBlock;
@Inject
private AjaxResponseRenderer ajaxResponseRenderer;
void onSuccessFromSearchForm()
{
searchHits = searchService.performSearch(query);
message = String.format("Found %,d matching documents", searchHits.size());
ajaxResponseRenderer.addRender("results", searchResults).addRender("status", statusBlock);
}
Note: Users of Tapestry 5.2 and earlier (which didn't support AjaxResponseRenderer) must replace that last line with: return new MultiZoneUpdate("results", searchResults).add("status", statusBlock);
AjaxResponseRenderer adds other useful commands as well. It also has the advantage that a simple return value can be returned to render content for the Zone that triggered the request.
What's that weird number in the middle of the client ids after a Zone is updated?
You might start with markup in your template for a component such as a TextField:
<t:textfield t:id="firstName"/>
When the component initially renders as part of a full page render, you get a sensible bit of markup:
<input id="firstName" name="firstName" type="text">
But when the form is inside a Zone and rendered as part of a zone update, the ids get weird:
<input id="firstName_12a820cc40e" name="firstName" type="text">
What's happening here is that Tapestry is working to prevent unwanted id clashes as part of the page update. In an HTML document, each id is expected to be unique; most JavaScript is keyed off of the id field, for instance.
In a full page render, components don't just use their component id (t:id) as their client id; instead they use the JavaScriptSupport environmental to allocate a unique id. When there's no loops or conflicts, the client id matches the component id.
When the component is inside a loop, a suffix is appended: firstName, firstName_0, firstName_1, etc.
When the component is rendered as part of an Ajax partial page update, the rules are different. Since Tapestry doesn't know what content has been rendered onto the page previously, it can't use its normal tricks to ensure that ids are unique.
Instead, Tapestry creates a random-ish unique id suffix, such as "12a820cc40e" in the example; this suffix is appended to all allocated ids to ensure that they do not conflict with previously rendered ids.
Why do I sometimes get the exception "The rendered content did not include any elements that allow for the positioning of the hidden form field's element." when rendering an empty Zone?
As part of Tapestry's form processing, it must write a hidden input element with information needed when the form is submitted. Since the content of a Zone may be changed or removed, a hidden field is created just for the Zone, separate from the rest of the enclosing form.
At the same time, Tapestry wants to position the <input> field in a valid location, and HTML defines some constraints for that; an input field must appear inside a <p> or <div> element. If your zone is initially empty, there's no place to put the hidden element, and Tapestry will complain.
The solution is simple: just add a <div> element to the body of the zone. This ensures that there's a place for the hidden input field. An empty <div> element (even one containing a hidden form field) will not affect page layout.
Injection
Main article: Injection
Contents
- What's the difference between the @Component and @InjectComponent annotations?
- What's the difference between the @InjectPage and @InjectContainer annotations?
- I get an exception because I have two services with the same interface, how do I handle this?
- What's the difference between @Inject and @Environmental?
- But wait ... I see I used the @Inject annotation and it still worked. What gives?
- Ok, but Request is a singleton service, not an environmental, and I can inject that. Is Tapestry really thread safe?
- I use @Inject on a field to inject a service, but the field is still null, what happened?
What's the difference between the @Component and @InjectComponent annotations?
The @Component annotation is used to define the type of component, and its parameter bindings. When using @Component, the template must not define the type, and any parameter bindings are merged in:
<a t:id="home" class="nav">Back to home</a>
@Component(parameters={ "page=index" })
private PageLink home;
Here the type of component is defined by the field type. The field name is matched against the t:id in the template. The page parameter is set in the Java class, and the informal class parameter is set in the template. If the tag in the template was <t:pagelink>, or if the template tag included the attribute t:type="pagelink", then you would see an exception.
By contrast, @InjectComponent expects the component to be already defined, and doesn't allow any configuration of it:
<t:form t:id="login"> .... </t:form>
@InjectComponent private Form login;
Again, we're matching the field name to the component id, and you would get an error if the component is not defined in the template.
What's the difference between the @InjectPage and @InjectContainer annotations?
The @InjectPage annotation is used to inject some page in the application into a field of some other page. You often see it used from event handler methods:
@InjectPage
private ConfirmRegistration confirmRegistration;
Object onSuccessFromRegistrationForm()
{
confirmRegistration.setStatus("Registration accepted");
confirmRegistration.setValidationCode(userRegistrationData.getValidationCode());
return confirmRegistration;
}
This code pattern is used to configure peristent properties of a page before returning it; Tapestry will send a client redirect to the page to present the data.
@InjectContainer can be used inside a component or a mixin. In a component, it injects the immediate container of the component; this is often the top-level page object.
In a mixin, it injects the component to which the mixin is attached.
I get an exception because I have two services with the same interface, how do I handle this?
It's not uncommon to have two or more services that implement the exact same interface. When you inject, you might start by just identifying the type of service to inject:
@Inject private ComponentEventResultProcessor processor;
Which results in the error: Service interface org.apache.tapestry5.services.ComponentEventResultProcessor is matched by 3 services: AjaxComponentEventResultProcessor, ComponentEventResultProcessor, ComponentInstanceResultProcessor. Automatic dependency resolution requires that exactly one service implement the interface.
We need more information than just the service interface type in order to identify which of the three services to inject. One possibility is to inject with the correct service id:
@InjectService("ComponentEventResultProcessor")
private ComponentEventResultProcessor processor;
This works ... but it is clumsy. If the service id, "ComponentEventResultProcessor", ever changes, this code will break. It's not refactoring safe.
Instead, we should use marker annotations. If we look at TapestryModule, where the ComponentEventResultProcessor service is defined, we'll see it identifies the necessary markers:
@Marker(
{ Primary.class, Traditional.class })
public ComponentEventResultProcessor buildComponentEventResultProcessor(
Map<Class, ComponentEventResultProcessor> configuration)
{
return constructComponentEventResultProcessor(configuration);
}
When a service has marker annotations, the annotations present at the point of injection (the field, method parameter, or constructor parameter) are used to select a matching service. The list of services that match by type is then filtered to only include services that have all of the marker annotations present at the point of injection.
@Inject @Traditional @Primary private ComponentEventResultProcessor processor;
The two marker annotations, @Traditional and @Primary, ensure that only a single service matches.
What's the difference between @Inject and @Environmental?
@Inject is relatively general; it can be used to inject resources specific to a page or component (such as ComponentResources, Logger, or Messages), or it can inject services or other objects obtained from the Tapestry IoC container. Once the page is loaded, the values for these injections never change.
@Environmental is different; it exposes a request-scoped, dynamically bound value:
- "Request scoped": different threads (processing different requests) will see different values when reading the field.
- "Dynamically bound": the value is explicitly placed into the Environment, and can be overridden at any time.
Environmentals are a form of loosely connected communication between an outer component (or even a service) and an inner component. Example: the Form component places a FormSupport object into the environment. Other components, such as TextField, use the FormSupport when rendering to perform functions such as allocate unique control names or register client-side validations. The TextField doesn't require that the Form component be the immediate container component, or even an ancestor: a Form on one page may, indirectly, communicate with a TextField on some entirely different page. Neither component directly links to the other, the FormSupport is the conduit that connects them.
The term "Environmental" was chosen as the value "comes from the environment".
But wait ... I see I used the @Inject annotation and it still worked. What gives?
In certain cases, Tapestry exposes a service (which can be injected) that is a proxy to the environmental; this is primarily for common environmentals, such as JavaScriptSupport, that may be needed outside of component classes. You can see this in TapestryModule:
TapestryModule.java (partial)
/**
* Builds a proxy to the current {@link JavaScriptSupport} inside this thread's {@link Environment}.
*
* @since 5.2.0
*/
public JavaScriptSupport buildJavaScriptSupport()
{
return environmentalBuilder.build(JavaScriptSupport.class);
}
This kind of logic is based on the EnvironmentalShadowBuilder service.
Ok, but Request is a singleton service, not an environmental, and I can inject that. Is Tapestry really thread safe?
Yes, of course Tapestry is thread safe. The Request service is another special case, as seen in TapestryModule:
TapestryModule.java (partial)
public Request buildRequest()
{
return shadowBuilder.build(requestGlobals, "request", Request.class);
}
RequestGlobals is a per-thread service. The Request service is a global singleton created by the PropertyShadowBuilder service, but is just a proxy. It has no internal state; invoking a method on the Request service just turns around and extracts the Request object from the per-thread RequestGlobals and invokes the same method there.
I use @Inject on a field to inject a service, but the field is still null, what happened?
This can happen when you use the wrong @Inject annotation; for example, com.google.inject.Inject instead of org.apache.tapestry5.ioc.annotations.Inject. This can occur when you have TestNG on the classpath, for example, and your IDE is too helpful. Double check your imports when things seem weird.
Also remember that @Inject on fields works for components and for service implementations or other objects that Tapestry instantiates, but not on arbitrary objects (that are created via Java's new keyword).
Tapestry Inversion of Control Container
Main article: Tapestry IoC
Contents
Related Articles
Why do I need to define an interface for my services? Why can't I just use the class itself?
First of all: you can do exactly this, but you lose some of the functionality that Tapestry's IoC container provides.
The reason for the split is so that Tapestry can provide functionality for your service around the core service implementation. It does this by creating proxies: Java classes that implement the service interface. The methods of the proxy will ultimately invoke the methods of your service implementation.
One of the primary purposes for proxies is to encapsulate the service's life cycle: most services are singletons that are created just in time. Just in time means only as soon as you invoke a method. What's going on is that the life cycle proxy (the object that gets injected into pages, components or other service implementations) checks on each method invocation to see if the actual service exists yet. If not, it instantiates and configures it (using proper locking to ensure thread safety), then delegates the method invocation to the service.
If you bind a service class (not a service interface and class), then the service is fully instantiated the first time it is injected, rather than at that first method invocation. Further, you can't use decorations or method advice on such a service.
The final reason for the service interface / implementation split is to nudge you towards always coding to an interface, which has manifest benefits for code structure, robustness, and testability.
My service starts a thread; how do I know when the application is shutting down, to stop that thread?
This same concern applies to any long-lived resource (a thread, a database connection, a JMS queue connection) that a service may hold onto. Your code needs to know when the application has been undeployed and shutdown. This is actually quite easy, by adding some post-injection logic to your implementation class.
MyServiceImpl.java
public class MyServiceImpl implements MyService
{
private boolean shuttingDown;
private final Thread workerThread;
public MyServiceImpl()
{
workerThread = new Thread(. . .);
}
. . .
@PostInjection
public void startupService(RegistryShutdownHub shutdownHub)
{
shutdownHub.addRegistryShutdownListener(new Runnable()
{
public void run()
{
shuttingDown = true;
workerThread.interrupt();
}
});
}
}
After Tapestry invokes the constructor of the service implementation, and after it performs any field injections, it invokes post injection methods. The methods must be public and return void. Parameters to a post injection method represent further injections ... in the above example, the RegistryShutdownHub is injected into the PostInjection method, since it is only used inside that one method.
It is not recommended that MyServiceImpl take RegistryShutdownHub as a constructor parameter and register itself as a listener inside the constructor. Doing so is an example of unsafe publishing, an unlikely but potential thread safety issue.
This same technique will work for any kind of resource that must be cleaned up or destroyed when the registry shuts down.
Be careful not to invoke methods on any service proxy objects as they will also be shutting down with the Registry. A RegistryShutdownListener should not be reliant on anything outside of itself.
How do I make my service startup with the rest of the application, rather than lazily?
Tapestry services are designed to be lazy; they are only fully realized when needed: when the first method on the service interface is invoked.
Sometimes a service does extra work that is desirable at application startup: examples may be registering message handlers with a JMS implementation, or setting up indexing. Since the service's constructor (or @PostInjection methods) are not invoked until the service is realized.
The solution is the @EagerLoad annotation; service implementation classes marked with this annotation are loaded when the Registry is first startup, rather than lazily.
Integration with existing applications
Contents
You may have an existing JSP (or Struts, Spring MVC, etc.) application that you want to migrate to Tapestry. It's quite common to do this in stages, moving some functionality into Tapestry and leaving other parts, initially, in the other system. You may need to prevent Tapestry from handling certain requests.
How do I make a form on a JSP submit into Tapestry?
Tapestry's Form component does a lot of work while an HTML form is rendering to store all the information needed to handle the form submission in a later request; this is all very specific to Tapestry and the particular construction of your pages and forms; it can't be reproduced from a JSP.
Fortunately, that isn't necessary: you can have a standard HTML Form submit to a Tapestry page, you just don't get to use all of Tapestry's built in conversion and validation logic.
All you need to know is how Tapestry converts page class names to page names (that appear in the URL). It's basically a matter of stripping off the root-package.pages prefix from the fully qualified class name. So, for example, if you are building a login screen as a JSP, you might want to have a Tapestry page to receive the user name and password. Let's assume the Tapestry page class is com.example.myapp.pages.LoginForm; the page name will be loginform (although, since Tapestry is case insensitive, LoginForm would work just as well), and the URL will be /loginform.
LoginForm.tml
<form method="post" action="/loginform"> <input type="text" value="userName"/> <br/> <input type="password" value="password"/> <br/> <input type="submit" value="Login"/> </form>
On the Tapestry side, we can expect that the LoginForm page will be activated; this means that its activate event handler will be invoked. We can leverage this, and Tapestry's RequestParameter annotation:
LoginForm.java
public class LoginForm
{
void onActivate(@RequestParameter("userName") String userName, @RequestParameter("password") String password)
{
// Validate and store credentials, etc.
}
}
The RequestParameter annotation extracts the named query parameter from the request, coerces its type from String to the parameter type (here, also String) and passes it into the method.
How do I share information between a JSP application and the Tapestry application?
From the servlet container's point of view, there's no difference between a servlet, a JSP, and an entire Tapestry application. They all share the same ServletContext, and (once created), the same HttpSession.
On the Tapestry side, it is very easy to read and write session attributes:
ShowSearchResults.java
public class ShowSearchResults
{
@SessionAttribute
private SearchResults searchResults;
}
Reading the instance variable searchResults is instrumented to instead read the corresponding HttpSession attribute named "searchResults". You can also specify the value attribute of the SessionAttribute annotation to override the default attribute name.
Writing to the field causes the corresponding HttpSession attribute to be modified.
The session is automatically created as needed.
How do I put the Tapestry application inside a folder, to avoid conflicts?
Support for this was added in 5.3; see the notes on the configuration page.
This page has moved to Specific Errors FAQ
Limitations
Contents
How do I add new components to an existing page dynamically?
The short answer here is: you don't. The long answer here is you don't have to, to get the behavior you desire.
One of Tapestry basic values is high scalability: this is expressed in a number of ways, reflecting scalability concerns within a single server, and within a cluster of servers.
Although you code Tapestry pages and components as if they were ordinary POJOs (Plain Old Java Objects -- Tapestry does not require you to extend any base classes or implement any special interfaces), as deployed by Tapestry they are closer to a traditional servlet: a single instance of each page services requests from multiple threads. Behind the scenes, Tapestry transforms you code, rewriting it on the fly.
What this means is that any incoming request must be handled by a single page instance. Therefore, Tapestry enforces the concept of static structure, dynamic behavior.
Tapestry provides quite a number of ways to vary what content is rendered, well beyond simple conditionals and loops. It is possible to "drag in" components from other pages when rendering a page (other FAQs will expand on this concept). The point is, that although a Tapestry page's structure is very rigid, the order in which the components of the page render does not have to be top to bottom.
Why doesn't my service implementation reload when I change it?
Main article: Service Implementation Reloading
Live service reloading has some limitations:
- The service must define a service interface.
- The service implementation must be on the file system (not inside a JAR).
- The implementation must be instantiated by Tapestry, not inside code (even code inside a module class).
- The service must use the default scope (reloading of perthread scopes is not supported).
Consider the following example module:
public static void bind(ServiceBinder binder)
{
binder.bind(ArchiveService.class, ArchiveServiceImpl.class);
}
public static JobQueue buildJobQueue(MessageService messageService, Map<String,Job> configuration)
{
JobQueueImpl service = new JobQueueImpl(configuration);
messageService.addQueueListener(service);
return service;
}
ArchiveService is reloadable, because Tapestry instantiates ArchiveServiceImpl itself. On the other hand, Tapestry invokes buildJobQueue() and it is your code inside the method that instantiates JobQueueImpl, so the JobQueue service will not be reloadable.
Finally, only classes whose class files are stored directly on the file system, and not packaged inside JARs, are ever reloadable ... generally, only the services of the application being built (and not services from libraries) will be stored on the file system. This reflects the intent of reloading: as an agile development tool, but not something to be used in deployment.
How do I run multiple Tapestry applications in the same web application?
Running multiple Tapestry 5 applications is not supported; there's only one place to identify the application root package, so even configuring multiple filters into multiple folders will not work.
Support for multiple Tapestry applications in the same web application was a specific non-goal in Tapestry 5 (it needlessly complicated Tapestry 4). Given how loosely connected Tapestry 5 pages are from each other, there doesn't seem to be an advantage to doing so ... and certainly, in terms of memory utilization, there is a significant down side, were it even possible.
You can run a Tapestry 4 app and a Tapestry 5 app side-by-side (the package names are different, for just this reason), but they know nothing of each other, and can't interact directly. This is just like the way you could have a single WAR with multiple servlets; the different applications can only communicate via URLs, or shared state in the HttpSession.
Hibernate Support
Main article: Hibernate
Contents
How do I get Hibernate to startup up when the application starts up, rather than lazily with the first request for the application?
This was a minor problem in 5.0; by 5.1 it is just a matter of overriding the configuration system tapestry.hibernate-early-startup to "true".
Maven Support
Contents
Why do Maven project names and other details show up in my pages?
Tapestry and maven both use the same syntax for dynamic portions of files: the ${...} syntax. When Maven is copying resources from src/main/resources, and when filtering is enabled (which is not the default), then any expansions in Tapestry templates that match against Maven project properties are substituted. If you look at the deployed application you'll see that ${name} is gone, replaced with your project's name!
The solution is to update your pom.xml and ignore any .tml files when copying and filtering:
pom.xml (partial)
<resource>
<directory>src/main/resources</directory>
<excludes>
<exclude>**/*.tml</exclude>
</excludes>
<filtering>true</filtering>
</resource>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.tml</include>
</includes>
<filtering>false</filtering>
</resource>
Unknown macro: {htmlcomment}
Update here after adding new headings to child pages. Forces a rebuild of the main TOC.
A random number: 1234