THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
本次实验主要有两个目的
- 验证在真实环境中是否能真正进行优化
- 找到通过一次性读取并缓存的优化策略来读取的阈值
1 实验环境
1.1 测试条件
1000个measurement
每个measurement 1000000row
32G内存
1.2 测试用例
Read All Vector Chunk
读一串连续的measurement,横坐标表示读取一个vector下连续的chunk的数量(从1开始)
select s001,s002,s003,..,s100 from root.sg_2.d1.vector
Read Bad Vector Chunk
读两个measurement,横坐标表示读取一个vector下的首尾chunk的间隔
select s001,s500 from root.sg_2.d1.vector
关于OS缓存,默认开启,使用vmtouch工具可以关闭
2 客户端计时
2.1 Read All OS不缓存
借助
vmtouch工具,保证OS不进行缓存
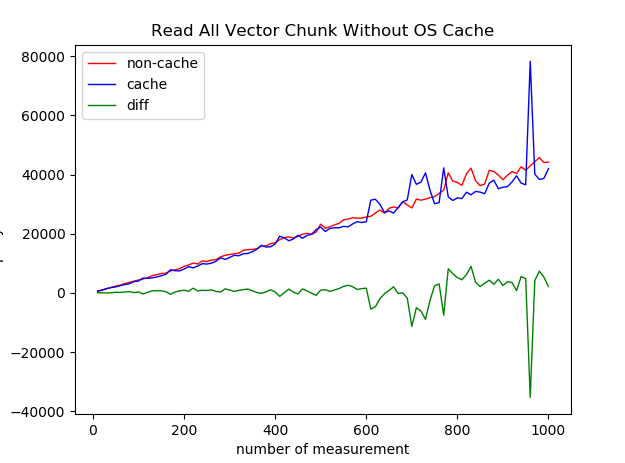
效果很不显著
2.2 Read All OS缓存(真实环境)
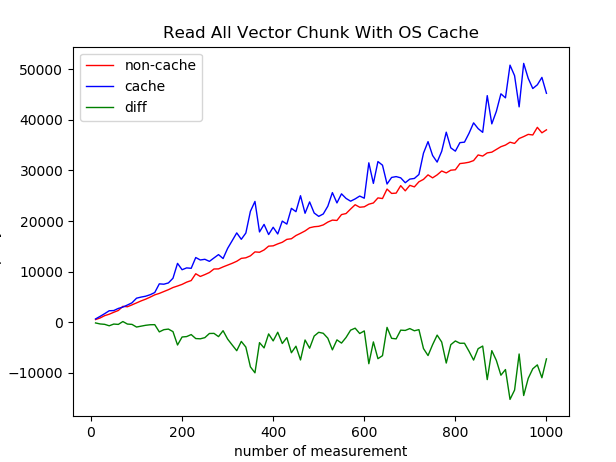
没有优化前的好
注意到,读取的时候data目录大小为2GB,vmtouch监控下全称被OS缓存,所以基本不涉及磁盘IO,同实验1的结论
2.3 Read Bad OS缓存(真实环境)
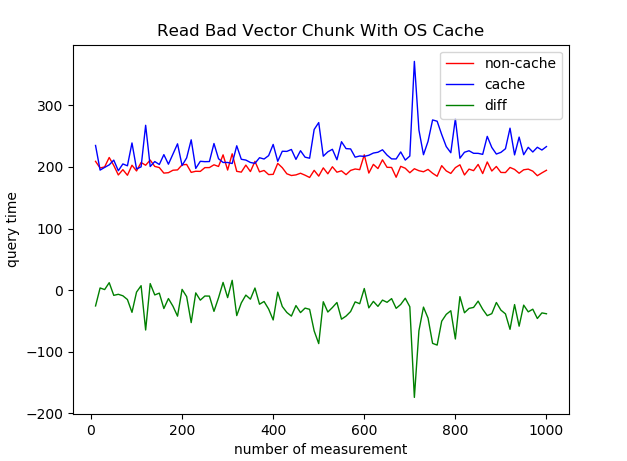
没有优化前的好
注意到,读取的时候data目录大小为2GB,vmtouch监控下全称被OS缓存,所以基本不涉及磁盘IO,同实验1的结论
3 服务端计时
3.1 Read All OS不缓存
2.1的实验理论上效果应该很显著,但是从图中看来并不是很明显。通过日志判断,IO大概只有几百~几千ms的开销,说明开销的大头在于数据的网络传输,而数据的网络传输难以控制,因此我在服务端进行计时,重新进行了实验。
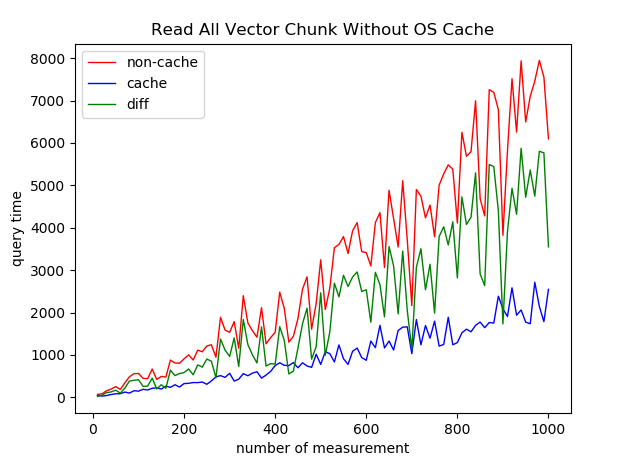
发现确实能大幅提升性能
TODO:多个客户端一起进行查询