THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: Under discussion
Discussion thread: here
JIRA: here TBD
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
Being able to centrally monitor and troubleshoot problems with Kafka clients is becoming increasingly important as the use of Kafka is expanding within organizations as well as for hosted Kafka services. The typical Kafka client user is now an application owner with little experience in operating Kafka clients, while the cluster operator has profound Kafka knowledge but little insight in the client application.
While the broker already tracks request-level metrics for connected clients, there is a gap in the end-to-end monitoring when it comes to visibility of client internals, be it queue sizes, internal latencies, error counts, application behaviour (such as message processing rate), etc. These are Kafka client metrics, and not application metrics.
This proposal aims to provide a generic and standardised interface through which a cluster operator or an external system may request and a client can push client-side metrics to the broker, a plugin interface for how those metrics are handled by the broker, and a minimum set of standard pre-defined metrics that a Kafka client should expose through this interface. A supporting client should have metrics enabled by default and not require any extra configuration, and will provide at least the standardised metrics as outlined later in this proposal.
One of the key goals of this KIP is to have the proposed metrics and telemetry interface generally available and enabled by default in all of the mainstream Kafka clients, allowing troubleshooting and monitoring as needed without interaction from cluster end-users.
User privacy is an important concern and extra care is taken in this proposal to not expose any information that may compromise the privacy of the client user.
Public Interfaces
This KIP introduces the following new public interfaces:
- New PushTelemetryRequest protocol request type.
- Updated metrics receiver interface in the broker to accustom for the new semantics and format.
- A new CLIENT_METRICS ConfigEntry resource type for configuring metrics subscriptions.
- kafka-client-metrics.sh CLI script to configure and list client metrics subscriptions.
Default behaviour
The metric collection is opt-in on the broker and opt-out on the client.
For metrics to be collected a MetricsPlugin (see below) must be configured on the brokers, and at least one metrics subscription must be configured through the Admin API. Only then will metrics subscriptions be propagated to clients, and only then will clients push metrics to the broker. It is thus up to the cluster operator to explicitly enable client metrics collection.
Protocol
GetTelemetrySubscriptionsRequestV0 {
ClientInstanceId uuid // UUID4 unique for this client instance.
// Must be set to Null on the first request, and to the
// returned ClientInstanceId from the first response
// for all subsequent requests to any broker.
}
GetTelemetrySubscriptionsResponseV0 {
ThrottleTime int32 // Standard throttling
ErrorCode int16 // Error code
ClientInstanceId uuid // Assigned client instance id if ClientInstanceId was Null in the request, else Null.
SubscriptionId int32 // Unique identifier for the current subscription set for this client instance.
AcceptedCompressionTypes Array[int8] // The compression types the broker accepts for PushTelemetryRequest.CompressionType.
// Calculated as a bitmask of (1 << MessageHeaderV2.Attributes.CompressionType).
PushIntervalMs int32 // Configured push interval, which is the lowest configured interval in the current subscription set.
DeltaTemporality bool // If True; monotonic/counter metrics are to be emitted as deltas to previous sample.
// If False; monotonic/counter metrics are to be emitted as cumulative absolute values.
RequestedMetrics Array[string] // Requested Metrics prefix string match.
// Empty array: No metrics subscribed.
// Array[0] empty string: All metrics subscribed.
// Array[..]: prefix string match
}
PushTelemetryRequestV0 {
ClientInstanceId uuid // UUID4 unique for this client instance, as retrieved in the first GetTelemetrySubscriptionsRequest.
SubscriptionId int32 // SubscriptionId from the GetTelemetrySubscriptionsResponse for the collected metrics.
Terminating bool // Client is terminating.
CompressionType int8 // Compression codec used for .Metrics (ZSTD, LZ4, Snappy, GZIP, None).
// Same values as that of the current MessageHeaderV2.Attributes.
Metrics binary // Format specified by ContentType, possibly compressed.
}
PushTelemetryResponseV0 {
ThrottleTime int32 // Standard and metric-specific throttling
ErrorCode int16 // Error code
}
Metrics format
The metrics format for PushTelemetryRequestV0 is OpenTelemetry Protobuf protocol definitions version 0.11.
Future versions of PushTelemetryRequest and GetTelemetrySubscriptionsRequest may include a content-type field to allow for updated OTLP format versions (or additional formats), but this field is currently not included since only one format is specified by this proposal.
SubscriptionId
The SubscriptionId is a unique identifier for a client instance's subscription set, the id is generated by calculating a CRC32 of the configured metrics subscriptions matching the given client including the PushIntervalMs, XORed with the ClientInstanceId. This SubscriptionId is returned to the client in the GetTelemetrySubscriptionsResponse and the client passes that SubscriptionId in each subsequent PushTelemetryRequest for those received metrics. If the configured subscriptions are updated and resulting in a change for a client instance, the SubscriptionId is recalculated. Upon the next PushTelemetryRequest using the previous SubscriptionId, the broker will find that the received and expected SubscriptionIds differ and it will return UnknownSubscriptionId back to the client. When a client receives this error code it will immediately send a GetTelemetrySubscriptionsRequest to retrieve the new subcription set along with a new SubscriptionId.
This mechanism provides a way for the broker to propagate an updated subscription set to the client and is similar to the use of Epochs in other parts of the protocol, but simplified in that no state needs to be persisted - the configured subscription set + client instance id is the identifier itself.
Broker metrics receiver
The broker will expose a plugin interface for client telemetry to be forwarded to or collected by external systems. In particular, since we already collect data in OpenTelemetry format, one goal is to make it possible for a plugin to forward metrics directly to an OpenTelemetry collector.
The existing MetricsReporter plugin interface was built for plugins to pull metrics from the broker, but does not lend itself to the model where the broker pushes metric samples to plugins.
In order to minimize the complexity of additional configuration mechanisms, we are proposing to reuse the existing metrics reporter configuration mechanisms, but allow plugins to implement a new interface (trait) to indicate if they support receiving client telemetry.
This also allows a plugin to reuse the existing labels passed through the MetricsContext (e.g. broker, cluster id, and configured labels) and add them to the OpenTelemetry resource labels as needed.
/**
* A {@link MetricsReporter} may implement this interface to indicate support for collecting client telemetry on the server side
*/
@InterfaceStability.Evolving
public interface ClientTelemetry {
/**
* Called by the broker to create a ClientTelemetryReceiver instance.
* This instance may be cached by the broker.
*
* This method will always be called after the initial call to
* {@link MetricsReporter#contextChange(MetricsContext)}
* on the MetricsReporter implementing this interface.
*
* @return
*/
ClientTelemetryReceiver clientReceiver();
}
@InterfaceStability.Evolving
public interface ClientTelemetryReceiver {
/**
* Called by the broker when a client reports telemetry. The associated request context can be used
* by the plugin to retrieve additional client information such as client ids or endpoints.
*
* This method may be called from the request handling thread, and as such should avoid blocking.
*
* @param context the client request context for the corresponding PushTelemetryRequest api call
* @param payload the encoded telemetry payload as sent by the client
*/
void exportMetrics(AuthorizableRequestContext context, ClientTelemetryPayload payload);
}
@InterfaceStability.Evolving
public interface ClientTelemetryPayload {
/**
* Client's instance id.
*/
Uuid clientInstanceId();
/**
* Indicates whether client is terminating, e.g., the last metrics push from this client instance.
*/
boolean isTerminating();
/**
* Metrics data content-type / serialization format.
* Currently "application/x-protobuf;type=otlp+metrics0.11"
*/
String contentType();
/**
* Serialized uncompressed metrics data.
*/
ByteBuffer data();
}
Client API
Retrieve broker-generated client instance id, may be used by application to assist in mapping the client instance id to the application instance through log messages or other means.
The following method should be added to the Producer, Consumer, and Admin client interfaces;
/** * @returns the client's assigned instance id used for metrics collection. */ public String clientInstanceId(Duration timeout)
If the client has not yet requested a client instance id from the broker this call will block up to the timeout. If no client instance id can be retrieved within the timeout an error is returned/raised (timeout, feature not supported by broker, auth failure, etc).
Client configuration
enable.metrics.push=true|false (default: true) -Allows disabling the functionality outlined in this proposal which should be enabled by default.
New error codes
UnknownSubscriptionId - See Error handling chapter.
Proposed Changes
Overview
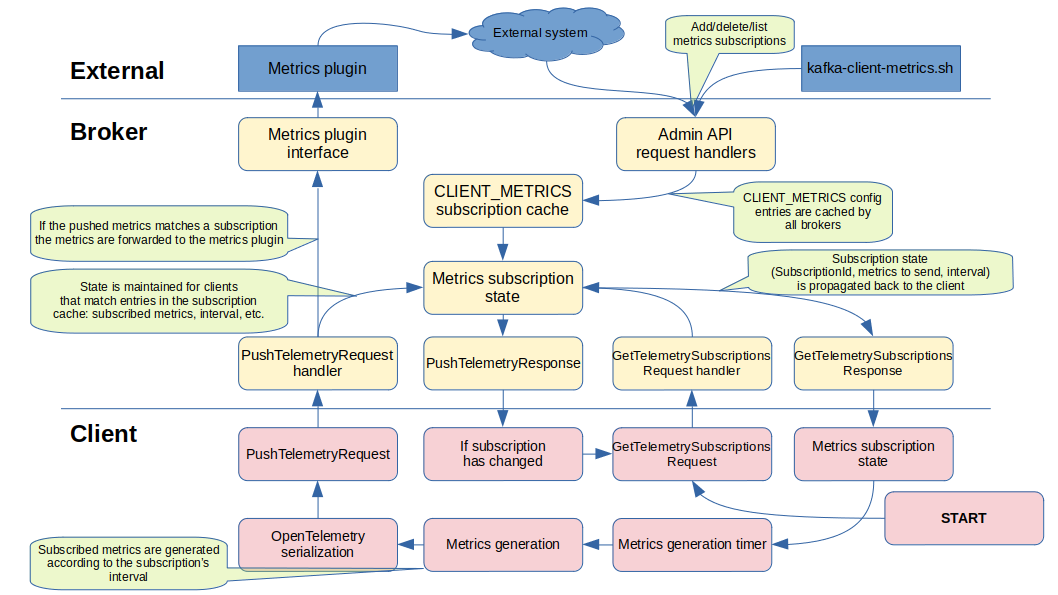
This feature is made up of the following components:
- GetTelemetrySubscriptionsRequest|Response - protocol request used by the client to acquire its initial Client instance ID and to continually retrieve updated metrics subscriptions.
- PushTelemetryRequest|Response - protocol request used by the client to send metrics to any broker it is connected to.
- Standardised metrics - a set of standardised metrics that all supporting clients should provide.
- AdminAPI config - the AdminAPI configuration interface with a new CLIENT_METRICS resource type is used to manage metrics subscriptions.
- Client metrics plugin / extending the MetricsReporter interface - a broker plugin interface that performs something meaningful with the metrics. This plugin will typically forward the metrics to a time series database. It is recommended that any broker-side processing is kept to a minimum for scalability and performance reasons.
Client identification (CLIENT_INSTANCE_ID)
The value of metrics collection is limited if the metrics can’t be tied to an entity, in this case a client instance. While aggregate metrics do provide some value in trends and superficial monitoring, for metrics to be truly useful there needs to be a way to identify a particular client instance, where it runs, by who, etc.
While Kafka has a per-request client.id (which most Kafka clients allow to be optionally configured), it is in no way unique and can’t be used, despite its name, to identify a single client instance.
Other seemingly unique identifiers such as authentication principals, client IP source address and port, etc, are either not guaranteed to be unique (there may not be authentication involved or not specific to a single client instance), or not a singleton (a client will have multiple connections to the cluster each connection with its own unique address+port combination).
Since this KIP intends to have metrics enabled by default in supporting clients we can’t rely on the client.id being properly set by the application owner, so we have to resort to some other mechanism for a client instance to uniquely identify itself. There are ideally two entities that we would like to identify in metrics:
- Client instance - a single instance of a producer, consumer, Admin client, etc.
- Application process instance - a single application runtime, which may contain multiple client instances. E.g. a Kafka Streams application with a mix of Admin, producer and consumer instances.
This proposal suggests that as part of the initial metrics handshake the broker generates a unique client instance id UUID4 and returns it to the client. The client must use the returned client instance id for the remaining lifetime of the client instance regardless of which broker it communicates with.
The client should provide an API for the application to read the generated client instance id as to assist in mapping and identification of the client based on the collected metrics. As an alternative or complement the client may log its client instance id as soon as it has acquired it from the cluster. This allows live and post-mortem correlation between collected metrics and a client instance.
As it is not feasible for a Kafka client instance to automatically generate or acquire a unique identity for the application process it runs in, and as we can’t rely on the user to configure one, we treat the application instance id as an optional future nice-to-have that may be included as a metrics label if it has been set by the user. This allows a more direct mapping of client instance to application instance and vice versa. However, due to these constraints and the need for zero-configuration on the client, adding an application instance id configuration property is outside the scope of this proposal.
Kafka Streams applications have an application.id configured and this identity should be included as the application_id metrics label.
Mapping
Mapping the client instance id to an actual application instance running on a (virtual) machine can be done by inspecting the metrics resource labels, such as the client source address and source port, or security principal, all of which are added by the receiving broker. This will allow the operator together with the user to identify the actual application instance.
Metrics naming and format
The OpenTelemetry specification will be used as the metrics serialization format as well as to define how metrics are constructed when it comes to naming, metric type, semantics, etc.
See the OpenTelemetry metrics specification for more information.
Encoding
While future protocol-level request could allow for other metrics formats, Kafka will only ship with OpenTelemetry and it is required for a client that claims support of this KIP to use the OpenTelemetry v0.11 protobuf format.
Metric payloads are encoded as OpenTelemetry MetricsData protobuf objects.
Naming
Metrics will be named in a hierarchical format:
<namespace>.<metric.name>
E.g.:
org.apache.kafka.client.producer.partition.queue.bytes
The metric namespace is org.apache.kafka for the standard metrics, vendor/implementation specific metrics may be added in separate namespaces, e.g:
librdkafka.client.producer.xmitq.latency
com.example.client.python.object.count
The Apache Kafka Java client will provide implementation specific metrics in something akin to:
org.apache.kafka.client.java.producer.socket.buffer.full.count
Metrics may hold any number of key=value labels which provide the multi-dimensionality of metrics, e.g., the per-partition queue bytes metric described above would have (at least) the following labels:
topic=mytopic
partition=3
acks=all
A client instance is considered a metric resource and the resource-level (thus client instance level) labels could include:
client_software_name=confluent-kafka-python
client_software_version=v2.1.3
client_instance_id=B64CD139-3975-440A-91D4
idempotence=true
transactional_id=someTxnApp
Sparse metrics
To keep metrics volume down it is recommended that a client only sends metrics with a recorded value.
Metric aggregation temporality
Metrics are to be sent as either DELTA or CUMULATIVE values, depending on the value of DeltaTemporality in the GetTelemetrySubscriptionsResponse.
CUMULATIVE metrics allow for missed/dropped transmits without loss of precision at the cost of increased processing and complexity required in upstream systems.
While clients must support both temporalities, the broker will only send GetTelemetrySubscriptionsResponse.DeltaTemporality=True. Configuration properties or extensions to the Metrics plugin interface on the broker to change the temporality is outside the scope of this KIP and may be addressed at a later time as the need arises.
Serialized size
As an example, the serialized size prior to compression of all producer and standard metrics defined in this KIP for a producer producing to 50 partitions gives approximately 100 kB.
Compression
As metric names and labels are highly repetative it is recommended that the serialized metrics are compressed prior to sending them to the broker if the serialized uncompressed size exceeds 1000 bytes.
The PushTelemtryRequest.CompressionType must then be set to the corresponding compression type value as defined for MessageV2.
Preliminary tests indicate that a compression ratio up to 10x is possible for the standard metrics using ZStd.
Decompression of the metrics data will be performed by the broker prior to passing the data to the metrics plugin.
Client behaviour
A client that supports this metric interface and identifies a supportive broker (through detecting at least GetTelemetrySubscriptionsRequestV0 in the ApiVersionResponse) will start off by sending a GetTelemetrySubscriptionsRequest with the ClientInstanceId field set to Null to one randomly selected connected broker to gather its client instance id, the subscribed metrics, the push interval, accepted compression types, etc. This handshake with a Null ClientInstanceId is only performed once for a client instance's lifetime. Sub-sequent GetTelemetrySubscriptionsRequests must include the ClientInstanceId returned in the first response, regardless of broker.
Upon receiving the GetTelemetrySubscriptionsResponse the client shall update its internal metrics collection to match the received subscription (absolute update) and update its push interval timer according to the returned PushIntervalMs. The first metrics push should be randomized between 0.5 * PushIntervalMs and 1.5 * PushIntervalMs, this is to ensure that not all clients start pushing metrics at the same time after a cluster comes back up after some downtime.
If GetTelemetrySubscriptionsResponse.RequestedMetrics indicates that no metrics are desired (RequestedMetrics is Null) the client should send a new GetTelemetrySubscriptionsResponse after the PushIntervalMs has expired.
Connection selection
The client may send telemetry requests to any broker, but shall prefer using an already available connection rather than creating a new connection - to keep the number of cluster connections down.
It should also keep using the same broker connection for telemetry requests until the connection goes down, at which time it may choose to reconnect and continue using the same broker, or switch over to another broker connection. Using a persistent connection for PushTelemetryRequests is important so that metrics throttling can be properly performed by the receiving broker, and also avoids maintaining metrics state for the client instance id on multiple brokers.
Client termination
When a client is being shut down it should send its final metrics regardless of the PushIntervalMs time, and only if the client has an active metrics subscription.
To avoid the receiving broker’s metrics rate-limiter to discard this out-of-profile push the PushTelemetryRequest.Terminating field must be set to true. A broker must only allow one such consecutive digression and otherwise throttle the client as if this field was not set.
The metrics should contain the reason for the client termination by including the client.terminating metric with the label “reason” set to a human readable explanation why the client is being shut down, such as “Fatal error: Static consumer fenced by newer instance”, or “Consumer closed by application”.
Error handling
Actions to be taken by the client if the GetTelemetrySubscriptionsResponse.Error or PushTelemetryResponse.ErrorCode is set to a non-zero value.
Error code | Reason | Client action |
..AuthorizationFailed | Client is not permitted to send metrics. | Log a warning to the application and schedule the next GetTelemetrySubscriptionsRequest in 30 minutes. |
InvalidRecord | Broker failed to decode or validate the client’s encoded metrics. | Log a warning to the application and schedule the next GetTelemetrySubscriptionsRequest to 5 minutes. |
| UnknownSubscriptionId | Client sent a PushTelemetryRequest with an invalid or outdated SubscriptionId, the configured subscriptions have changed. | Send a GetTelemetrySubscriptionRequest to update the client's subscriptions. |
UnsupportedCompressionType | Client’s compression type is not supported by the broker. | Send a GetTelemetrySubscriptionRequest to get an up to date list of the broker's supported compression types (and any subscription changes). |
The 5 and 30 minute retries are to eventually trigger a retry and avoid having to restart clients if the cluster metrics configuration is disabled temporarily, e.g., by operator error, rolling upgrades, etc.
Retries should preferably be attempted on the same broker connection, in particular for UnknownSubscriptionId, but another broker connection may be utilized at the discretion of the client.
How error and warnings are propagated to the application is client and language specific, simply logging the error is sufficient.
Opting out
Client metrics should be enabled by default in the client but a user may disable the metrics functionality by setting the enable.metrics.push property to false.
Although metrics are enabled in a client, the client will only push metrics that have been configured/subscribed in the cluster.
Also see the Privacy chapter below.
Receiving broker behaviour
We allow clients to send the GetTelemetrySubscriptions and PushTelemetry requests to any connected broker that reports support for both these APIs in its ApiVersionResponse.
If GetTelemetrySubscriptionsRequest.ClientInstanceId is Null the broker will generate a unique id for the client and return it in the response. Sub-sequent requests from the client to any broker must have the ClientInstanceId set to this returned value.
The broker should add additional metrics labels to help identify the client instance before forwarding the metrics to an external system. These are labels such as the namespace, cluster id, client principal, client source address and port, etc. As the metrics plugin may need to add additional metrics on top of this the generic metrics receiver in the broker will not add these labels but rely on the plugins to do so, this avoids deserializing and serializing the received metrics multiple times in the broker.
See Broker added labels below for the list of labels that should be added by the plugin.
If there is no client metrics receiver plugin configured on the broker it will respond to GetTelemetrySubscriptionsRequests with RequestedMetrics set to Null and a -1 SubscriptionId. The client should send a new GetTelemetrySubscriptionsRequest after the PushIntervalMs has expired. This allows the metrics receiver to be enabled or disabled without having to restart the broker or reset the client connection.
PushTelemetryRequest handling
Validation
Validation of the encoded metrics is the task of the ClientMetricsReceiver, if the compression type is unsupported the response will be returned with ErrorCode set to UnsupportedCompressionType. Should decoding or validation of the binary metrics blob fail the ErrorCode will be set to InvalidRecord.
Rate-limiting and PushIntervalMs
The receiving broker’s standard quota-based throttling should operate as usual for PushTelemetryRequest, but in addition to that the PushTelemetryRequest is also subject to rate-limiting based on the calculated next desired PushIntervalMs interval derived from the configured metrics subscriptions. Should the client send a push request prior to expiry of the previously calculated PushIntervalMs the broker will discard the metrics and return a PushTelemetryResponse with the ThrottleTime set to remaining PushIntervalMs time.
The one exception to this rule is when the client sets the PushTelemetryRequest.Terminating field to true indicating that the client is terminating, in this case the metrics should be accepted by the broker, but a consecutive request must ignore the Terminating field and apply rate-limiting as if the field was not set. The Terminating flag may be reused upon the next expiry of PushIntervalMs.
Metrics subscription
Metrics subscriptions are configured through the standard Kafka Admin API configuration interface with the new resource-type CLIENT_METRICS, the resource-name is any string - it does not have significance to the metrics system other than to group metrics subscriptions in the configuration interface. The configuration is made up of the following ConfigEntry names:
metrics- a comma-separated list of metric name prefixes, e.g.,"client.producer.partition., client.io.wait". Whitespaces are ignored.interval- metrics push interval in milliseconds. Defaults to 5 minutes if not specified.match_<selector>- Client matching selector that is evaluated as an anchored regexp (i.e., "something.*" is treated as "^something.*$"). Any client that matches all of thematch_..selectors will be eligible for this metrics subscription. Initially supported selectors:client_instance_id- CLIENT_INSTANCE_ID UUID string representation.client_id- client's reported client.id in the GetTelemetrySubscriptionsRequest.client_software_name- client software implementation name.client_software_version- client software implementation version.client_source_address- client connection's source address from the broker's point of view.client_source_port- client connection's source port from the broker's point of view.
Example using the standard kafka-configs.sh tool:
$ kafka-configs.sh --bootstrap-server $BROKERS \ --entity-type client_metrics \ --entity-name ‘basic_producer_metrics’ \ --alter \ --add-config 'metrics=[org.apache.kafka/client.producer.partition.queue., org.apache.kafka/client.io.wait],interval=15000,match_client_instance_id=b69cc35a-7a54-4790-aa69-cc2bd4ee4538'
Or using the dedicated tool (preferred):
# Subscription for a specific client instance id
$ kafka-client-metrics.sh --bootstrap-server $BROKERS \
--add \
--name 'Troubleshoot_b69cc35a' \ # A descriptive name makes it easier to clean up old subscriptions.
--match client_instance_id=b69cc35a-7a54-4790-aa69-cc2bd4ee4538 \ # Match this specific client instance
--metric org.apache.kafka/client.producer.partition.queue. \ # prefix-match
--metric org.apache.kafka/client.producer.partition.latency \
--interval-ms 15000
# Subscription for all kafka-python v1.2.* clients
# A unique name is automatically generated when --name is omitted.
$ kafka-client-metrics.sh --bootstrap-server $BROKERS \
--add \
--metric org.apache.kafka/client.consumer. \ # prefix-match
--interval-ms 60000
--match 'client_software_name=kafka-python' \ # match kafka-python 1.2.*
--match 'client_software_version=1\.2\..*'
As the assumption is that the number of CLIENT_METRICS configuration entries will be relatively small (<100), all brokers with a configured metrics plugin will monitor and cache the configuration entries for the CLIENT_METRICS resource type.
As a GetTelemetrySubscriptionsRequest is received for a previously unknown client instance id the CLIENT_METRICS config cache is scanned for any configured metric subscriptions whose match selectors match that of the client. The resulting matching configuration entries are compiled into a list of subscribed metrics which is returned in GetTelemetrySubscriptionsResponse.RequestedMetrics along with the minimum configured collection interval (this can be improved in future versions by including a per-metric interval so that each subscribed metric is collected with its configured interval, but in its current form longer-interval metrics are included “for free” if there are shorter-interval metrics in the subscription set). The CRC32 checksum is also calculated based on the compiled metrics and is returned as the SubscriptionId in the response, as well as stored in the per-client-instance cache on the broker to track configuration changes.
This client instance specific state is maintained in broker memory up to MAX(60*1000, PushIntervalMs * 3) milliseconds and is used to enforce the push interval rate-limiting. There is no persistence of client instance metrics state across broker restarts or between brokers.
New broker metrics
The following brokers metrics should be added:
- ClientMetricsInstanceCount - current number of client metric instances being managed by this broker. E.g., the number of unique CLIENT_INSTANCE_IDs with an empty or non-empty subscription set.
- ClientMetricsActiveInstanceCount - current number of active client metric instances being managed by this broker. E.g., the number of unique CLIENT_INSTANCE_IDs with a non-empty subscription set.
- ClientMetricsNewInstanceCount - total number of GetTelemetrySubscriptionsRequests with a Null CLIENT_INSTANCE_IDs
- ClientMetricsUnknownInstanceCount - total number of metrics requests for unknown CLIENT_INSTANCE_IDs.
- ClientMetricsThrottleCount - total number of throttled PushTelemetryRequests due to a higher PushTelemetryRequest rate than the allowed PushIntervalMs.
- ClientMetricsPluginExportCount - the total number of metrics requests being pushed to metrics plugins, e.g., the number of exportMetrics() calls.
- ClientMetricsPluginExportTimeMs - the amount of time plugins spent handling pushed metrics, e.g., the amount of time spent in exportMetrics().
- ClientMetricsPluginErrorCount - the total number of exceptions raised from plugin's exportMetrics().
Client metrics and metric labels
Clients that support this KIP must provide the following metrics, as long as they’re relevant for the client implementation. These metrics do not need to be strictly comparable between client implementations, e.g., io.wait.time may have somewhat different semantics between Java client and librdkafka, but should have the same meaning.
We try to avoid metrics that are available or derivable from existing broker metrics, such as request rates, etc.
All standard metrics are prefixed with “org.apache.kafka.”, this prefix is omitted from the following tables for brevity.
A client implementation must not add additional metrics or labels under the “org.apache.kafka.” prefix without a corresponding accepted KIP.
Private metrics
The default metrics collection on the client must take extra care not to expose any information about the application and system it runs on as they may identify internal projects, infrastructure, etc, that the user may not want to expose to the Kafka infrastructure owner. This includes information such as hostname, operating system, credentials, runtime environment, etc. None of the metrics defined in this proposal expose any such information.
OpenTelemetry specifies a range of relevant metrics:
Private or host metrics are outside the scope of this specification.
Metric types
The metric types in the following tables correspond to the OpenTelemetry v1 metrics protobuf message types. A short summary:
- Sum - Monotonic total count meter (Counter). Suitable for total number of X counters, e.g., total number of bytes sent.
- Gauge - Non-monotonic current value meter (UpDownCounter). Suitable for current value of Y, e.g., current queue count.
- Histogram - Value distribution meter (ValueRecorder). Suitable for latency values, etc.
For simplicy a client implementation may choose to provide an average value as Gauge instead of a Histogram. These averages should be using the original Histogram metric name + ".avg60s" (or whatever the averaging period is), e.g., "client.request.rtt.avg10s".
Client instance-level metrics
Metric name | Type | Labels | Description |
client.connection.creations | Sum | broker_id | Total number of broker connections made. |
client.connection.count | Gauge | Current number of broker connections. | |
client.connection.errors | Sum | reason | Total number of broker connection failures. Label ‘reason’ indicates the reason: disconnect - remote peer closed the connection. auth - authentication failure. TLS - TLS failure. timeout - client request timeout. close - client closed the connection. |
client.request.rtt | Histogram | broker_id request_type | Average request latency / round-trip-time to broker and back. request_type is the protocol request type CamelCase name as specified in the Kafka protocol definition. |
client.request.queue.latency | Histogram | broker_id | Average request queue latency waiting for request to be sent to broker. |
client.request.queue.count | Gauge | broker_id | Number of requests in queue waiting to be sent to broker. |
client.request.success | Sum | broker_id request_type | Number of successful requests to broker, that is where a response is received without no request-level error (but there may be per-sub-resource errors, e.g., errors for certain partitions within an OffsetCommitResponse). |
client.request.errors | Sum | broker_id request_type reason | Number of failed requests. Label ‘reason’ indicates the reason: timeout - client timed out the request, disconnect - broker connection was closed before response could be received, error - request-level protocol error. |
client.io.wait.time | Histogram | Amount of time waiting for socket I/O writability (POLLOUT). A high number indicates socket send buffer congestion. |
As the client will not know the broker id of its bootstrap servers the broker_id label should be set to to the negative index of the broker in the client's bootstrap.servers list, starting at -1.
Client instance-level Producer metrics
Metric name | Type | Labels | Description |
client.producer.record.bytes | Gauge | Total number of record memory currently in use by producer. This includes the record fields (key, value, etc) as well as any implementation specific overhead (objects, etc). | |
client.producer.record.count | Gauge | Total number of records currently handled by producer. | |
client.producer.queue.max.bytes | Gauge | Total amount of queue/buffer memory allowed on the producer queue(s). | |
client.producer.queue.bytes | Gauge | Current amount of memory used in producer queues. | |
client.producer.queue.max.messages | Gauge | Maximum amount of messages allowed on the producer queue(s). | |
client.producer.queue.messages | Gauge | Current number of messages on the producer queue(s). |
Client instance-level Consumer metrics
Metric name | Type | Labels | Description |
client.consumer.poll.interval | Histogram | The interval at which the application calls poll(), in seconds. | |
client.consumer.poll.last | Gauge | The number of seconds since the last poll() invocation. | |
client.consumer.poll.latency | Histogram | The time it takes poll() to return a new message to the application | |
client.consumer.commit.count | Sum | Number of commit requests sent. | |
| client.consumer.group.assignment.strategy | String | Current group assignment strategy in use. | |
client.consumer.group.assignment.partition.count | Gauge | Number of currently assigned partitions to this consumer by the group leader. | |
client.consumer.assignment.partition.count | Gauge | Number of currently assigned partitions to this consumer, either through the group protocol or through assign(). | |
client.consumer.group.rebalance.count | Sum | Number of group rebalances. | |
| client.consumer.group.error.count | Sum | error | Consumer group error counts. The error label depicts the actual error, e.g., "MaxPollExceeded", "HeartbeatTimeout", etc. |
client.consumer.record.queue.count | Gauge | Number of records in consumer pre-fetch queue. | |
client.consumer.record.queue.bytes | Gauge | Amount of record memory in consumer pre-fetch queue. This may also include per-record overhead. | |
client.consumer.record.application.count | Sum | Number of records consumed by application. | |
client.consumer.record.application.bytes | Sum | Memory of records consumed by application. | |
client.consumer.fetch.latency | Histogram | FetchRequest latency. | |
client.consumer.fetch.count | Sum | Total number of FetchRequests sent. | |
client.consumer.fetch.failures | Sum | Total number of FetchRequest failures. |
Client topic-level Producer metrics
Metric name | Type | Labels | Description |
client.producer.partition.queue.bytes | Gauge | topic partition acks=all|none|leader | Number of bytes queued on partition queue. |
client.producer.partition.queue.count | Gauge | topic partition acks=all|none|leader | Number of records queued on partition queue. |
client.producer.partition.latency | Histogram | topic partition acks=all|none|leader | Total produce record latency, from application calling send()/produce() to ack received from broker. |
client.producer.partition.queue.latency | Histogram | topic partition acks=all|none|leader | Time between send()/produce() and record being sent to broker. |
client.producer.partition.record.retries | Sum | topic partition acks=all|none|leader | Number of ProduceRequest retries. |
client.producer.partition.record.failures | Sum | topic partition acks=all|none|leader reason | Number of records that permanently failed delivery. Reason is a short string representation of the reason, which is typically the name of a Kafka protocol error code, e.g., “RequestTimedOut”. |
client.producer.partition.record.success | Sum | topic partition acks=all|none|leader | Number of records that have been successfully produced. |
The “partition” label should be -1 for not yet partitioned messages, as they are not yet assigned to a partition queue.
Host process metrics (optional)
These metrics provide runtime information about the operating system process the client runs in.
Metric name | Type | Labels | Description |
client.process.memory.bytes | Gauge | Current process/runtime memory usage (RSS, not virtual). | |
client.process.cpu.user.time | Sum | User CPU time used (seconds). | |
client.process.cpu.system.time | Sum | System CPU time used (seconds). | |
| client.process.io.wait.time | Sum | IO wait time (seconds). | |
client.process.pid | Gauge | The process id. Can be used, in conjunction with the client host name to map multiple client instances to the same process. |
Standard client resource labels
Label name | Description |
| application_id | application.id (Kafka Streams only) |
client_rack | client.rack (if configured) |
group_id | group.id (consumer) |
group_instance_id | group.instance.id (consumer) |
group_member_id | Group member id (if any, consumer) |
transactional_id | transactional.id (producer) |
Broker-added labels
The following labels should be added by the broker plugin as metrics are received
Label name | Description |
client_instance_id | The generated CLIENT_INSTANCE_ID. |
| client_id | client.id as reported in the Kafka protocol header. |
client_software_name | The client’s implementation name as reported in ApiVersionRequest. |
client_software_version | The client’s version as reported in ApiVersionRequest. |
client_source_address | The client connection’s source address. |
client_source_port | The client connection’s source port. |
principal | Client’s security principal. Content depends on authentication method. |
broker_id | Receiving broker’s node-id. |
Security
Since client metric subscriptions are primarily aimed at the infrastructure operator that is managing the Kafka cluster it should be sufficient to limit the config control operations to the CLUSTER resource.
There will be no permission checks on the PushTelemetryRequest itself.
API Request | Resource | ACL |
DescribeConfigs | CLUSTER | DESCRIBE,READ |
AlterConfigs | CLUSTER | WRITE |
| GetTelemetrySubscriptionsRequest | N/A | N/A |
PushTelemetryRequest | N/A | N/A |
See the Private metrics chapter above for privacy/integrity.
Tools
kafka-client-metrics.sh is a wrapper tool around kafka-configs.sh that makes it easier to set up metric subscriptions.
bin/kafka-client-metrics.sh [arguments] --bootstrap-server <brokers>
List configured metrics:
--list
[--name <descriptive-config-name>]
Add metrics:
--add
[ --name <descriptive-config-name> ]
--metric <metric-prefix>.. # may repeat
--interval-ms <interval>
--match <selector=regex> # optional, may repeat
Delete metrics:
--delete
--name <descriptive-config-name>
Example workflows
Example workflows showcasing how this feature may be used for proactive and reactive purposes.
Proactive monitoring
The Kafka cluster is configured to collect all standard metrics pushed by the client at an interval of 60 seconds, the metrics plugin forwards the collected metrics to an imaginary system that monitors a set of well known metrics and triggers alarms when trends go out of profile.
The monitoring system detects an anomaly for CLIENT_INSTANCE_ID=4e6fb54c-b8e6-4517-889b-e15b99c09c20’s metric org.apache.kafka.client.producer.partition.queue.latency which for more than 180 seconds has exceeded the threshold of 5000 milliseconds.
Before sending the alert to the incident management system the monitoring system collects a set of labels that are associated with this CLIENT_INSTANCE_ID, such as:
- client.id
- client_source_address and client_source_port on broker id X (1 or more such mappings based on how many connections the client has used to push metrics).
- principal
- tenant
- client_software_name and client_software_version
- In case of consumer: group_id, group_instance_id (if configured) and the latest known group_member_id.
- In case of transactional producer: transactional_id
This collection of information, along with the triggered metric, is sent to the incident management system for further investigation or aggregation, and provides enough information to identify who and where the client is run. Further action might be to contact the organization or team that matches the principal, transactional.id, source address, etc, for further investigation.
Reactive monitoring
The Kafka cluster configuration for metrics collection (i.e., metrics subscriptions) is irrelevant to this use-case, given that a metrics plugin is enabled on the brokers. The metrics plugin is configured to write metrics to a topic. A support system with an interactive interface is reading from this metrics topic, and has an Admin client to configure the cluster with desired metrics subscriptions.
The application owner reports a lagging consumer that is not able to keep up with the incoming message rate and asks for the Kafka operator to help troubleshoot. The application owner, who unfortunately does not know the client instance id of the consumer, provides the client.id, userid, and source address.
The Kafka operator adds a metrics subscription for metrics matching prefix “org.apache.kafka.client.consumer.” and with the client_source_address and client_id as matching selector. Since this is a live troubleshooting case the metrics push interval is set to a low 10 seconds.
The metrics subscription propagates through configuration change notifications to all brokers which update their local metrics subscription config cache and regenerates the SubscriptionId.
Upon the next intervalled PushTelemetryRequest or GetTelemetrySubscriptionsRequest from the clients matching the given source address and client_id the receiving broker sees that the SubscriptionId no longer matches its metrics subscription cache, the client retrieves the new metrics subscription and schedules its next metrics push to a random value between PushIntervalMs * 0.5 .. PushIntervalMs * 1.5.
Upon the next PushTelemetryRequest, which now includes metrics for the subscribed metrics, the metrics are written to the output topic and the PushIntervalMs is adjusted to the configured interval of 10 seconds. This repeats until the metrics subscription configuration is changed.
Multiple consumers from the same source address and using the same client_id may now be pushing metrics to the cluster. The support system starts receiving the metrics and displays the matching client metrics to the operator. If the operator is able to further narrow down the client instance through other information in the metrics it may alter the metrics subscription to match on that client's client_instance_id. But in either case the metrics matching the given client.id are displayed to the operator.
The operator identifies an increasing trend in client.consumer.processing.time which indicates slow per-message processing in the application and reports this back to the application owner, ruling out the client and Kafka cluster from the problem space.
The operator removes the metrics subscription which causes the next PushTelemetryResponse to return an error indicating that the metrics subscription has changed, causing the client to get its new subscription which is now back to empty.
Future work
Tracing and logging are outside the scope of this proposal but the use of OpenTelemetry allows for those additional two methods within the same semantics and nomenclature outlined by this proposal.
Compatibility, Deprecation, and Migration Plan
What impact (if any) will there be on existing users?
Clients
Short of the configuration property to disable telemetry (enable.metrics.push=false - enabled by default) there are no user-facing changes to client users.
Depending on metrics subscription intervals there might be increased CPU and network load, but for modestly set subscription intervals this should be negligible.
Broker
The Kafka admin needs to explicitly configure a Metrics reporter plugin that supports the new push-based telemtry interface. If no such plugin is configured the telemetry collection is disabled and there will be no user-facing changes.
Depending on the metrics subscription patterns and intervals there is likely to be increased CPU and network load as brokers will receive, decompress and forward pushed client telemetry to the metrics plugin.
If we are changing behavior how will we phase out the older behavior?
No behavioural changes.
If we need special migration tools, describe them here.
None.
When will we remove the existing behavior?
Not relevant.
Rejected Alternatives
Send metrics out-of-band directly to collector
There are plenty of existing solutions that allows a client implementation to send metrics directly to a collector, but it falls short to meet the enabled-by-default requirements of this KIP:
- will require additional client-side configuration: endpoints, authentication, etc.
- may require additional network filtering and our routing configuration to allow the client host to reach the collector endpoints. By using the Kafka protocol we already have a usable connection.
- adds another network protocol the client needs to handle and its runtime dependencies (libraries..).
Dedicated Metrics coordinator based on client instance id
An earlier version of this proposal had the notion of metrics coordinator which was selected based on the client instance id. This metrics coordinator would be responsible for rate-limiting pushed metrics per client instance. To avoid each client to have a connection to its metric coordinator the proposal suggested using the impersonation/request-forwarding functionality suggested in a contemporary design by Jason G.
Since this made the broker-side implementation more complex and did not provide fool-proof control of misbehaving clients (a rogue client could simply generate new instance ids on each request) it was decided that the value of this functionality was not in par with the implementation cost and thus removed from the proposal.
JMX
Scales poorly, Java-specific, commonly mistaken for a trick bike.
Combine with Dynamic client configuration
The Push interface is well suited for propagating client configuration to clients, but to keep scope down we leave that out of this proposal. It should be straightforward to extend and repurpose the interface described in this proposal to also support dynamic client configuration, log/event retrieval, etc, at a later time.
Use native Kafka protocol framing for metrics
The Kafka protocol has flexible fields that would allow us to construct the metrics serialization with pure Kafka protocol fields, but this would duplicate the efforts of the OpenTelemetry specification where Kafka would have to maintain its own specification. On the broker side the native Kafka protocol metrics would need to be converted to OpenTelemetry (or other) format anyway.
The OpenTelemetry serialization format is all Protobufs and should thus be generally available across all client implementation languages.