THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: "Under Discussion"
Discussion thread:
JIRA:
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
In Kafka, Producers have the option of either waiting for the message to be committed or not, depending on their preference for tradeoff between latency and durability. This preference is controlled by the acks setting that the producer uses.
Currently, the acks config accepts these values:
acks=0- If set to zero then the producer will not wait for any acknowledgment from the server at all.
acks=1- This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers.
acks=all- This means the leader will wait for the full set of in-sync replicas to acknowledge the record.
For acks=all case, the simple flow is like this:
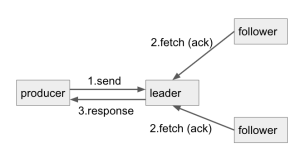
It looks perfect. But there's a caveat here. Like the doc said, acks=all will "wait for the full set of in-sync replicas to acknowledge the record", so if there's only 1 replica in in-sync replicas, it will have the same effect as acks=1 (even though we have replication-factor set to 3).
To get the expected durability, users also need to set min.insync.replicas config correctly. In the doc of min.insync.replicas config:
When min.insync.replicas and acks used together, it allows you to enforce greater durability guarantees. A typical scenario would be to create a topic with a replication factor of 3, set min.insync.replicas to 2, and produce with acks of "all". This will ensure that the producer raises an exception if a majority of replicas do not receive a write.
In the typical scenario: replication factor = 3, min.insync.replicas=2, acks=all, we ensure at least 2 replicas acks, which means, we can tolerate 1 replica out-of-sync or down (ex: rolling update) and still make the write process successfully. This keeps high availability and durability in Kafka.
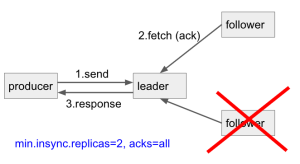
Let's step back and think again. In the case of replication factor = 3 and all 3 replicas are in-sync replica, if we can achieve high durability with 2 replicas ack, then, could we increase write throughput by just need 2 replicas ack, not 3 of them?
This is what we have now for acks=all , we need to wait for the slowest follower acks (i.e. 500ms) before we can respond to the producer.

I'd like to propose a new config: acks=min.insync.replicas (i.e. the number of replica acks is decided by the min.insync.replicas config in topic/broker) , we just need to wait for the fastest follower acks (i.e. 100ms) then respond to the producer.
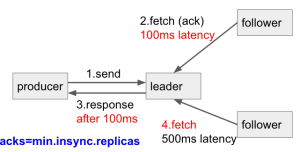
Furthermore, with this config, we can have fine-grained acks setting for each topic. For example,
Topic A, we can tolerate data lose, but require high throughput, we set min.insync.replicas=1
Topic B, we don't want data lose, we set min.insync.replicas=2
So, with current acks=all config, the producer will wait for all 3 replicas acks (suppose in-sync replicas are 3) for both topics A and B. If we want to achieve different durability setting, we need 2 producers to handle 2 topics.
But with the proposed acks=min.insync.replicas, we can achieve that with 1 producer, and define different durability level in topic min.insync.replicas config.
Public Interfaces
Proposed Changes
Describe the new thing you want to do in appropriate detail. This may be fairly extensive and have large subsections of its own. Or it may be a few sentences. Use judgement based on the scope of the change.
Compatibility, Deprecation, and Migration Plan
- What impact (if any) will there be on existing users?
- If we are changing behavior how will we phase out the older behavior?
- If we need special migration tools, describe them here.
- When will we remove the existing behavior?
Test Plan
Describe in few sentences how the KIP will be tested. We are mostly interested in system tests (since unit-tests are specific to implementation details). How will we know that the implementation works as expected? How will we know nothing broke?
Rejected Alternatives
If there are alternative ways of accomplishing the same thing, what were they? The purpose of this section is to motivate why the design is the way it is and not some other way.