THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
This page is meant as a template for writing a KIP. To create a KIP choose Tools->Copy on this page and modify with your content and replace the heading with the next KIP number and a description of your issue. Replace anything in italics with your own description.
Status
Current state: [One of "Under Discussion", "Accepted", "Rejected"]
Discussion thread: here [Change the link from the KIP proposal email archive to your own email thread]
JIRA: here [Change the link from KAFKA-1 to your own ticket]
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
This KIP will go over scenarios where we might expect disruptive servers and discuss how Pre-Vote (as originally detailed in the Raft paper and in KIP-650) along with Rejecting VoteRequests received within fetch timeout can ensure correctness when it comes to network partitions (as well as quorum reconfiguration and failed disk scenarios).
Disruptive server scenarios
Network Partition
When a follower becomes partitioned from the rest of the quorum, it will continuously increase its epoch to start elections until it is able to regain connection to the leader/rest of the quorum. When the follower regains connectivity, it will disturb the rest of the quorum as they will be forced to participate in an unnecessary election. While this situation only results in one leader stepping down, as we start supporting larger quorums these events may occur more frequently per quorum.
When a leader becomes partitioned from the rest of the quorum, we can consider two scenarios -
it becomes aware that it should step down as a leader/initiates a new election
This is now the follower case covered above.it continues to believe it is the leader until rejoining the rest of the quorum
On rejoining the rest of the quorum, it will start receiving messages w/ a different epoch. If higher than its own, the node will … if lower than its own, the node will … (todo: finish and confirm)
Misc
While network partitions may be the main issue we expect to encounter/mitigate impact for, it’s possible that bugs and user error create similar effects to network partitions that we need to guard against. For instance, a bug which causes fetch requests to periodically timeout or a user setting controller.quorum.fetch.timeout.ms and other related configs too low could trigger disruptive election behavior.
Quorum reconfiguration
Servers in old configuration
When reconfiguring a quorum, servers in the old configuration which are not also in new configuration will stop receiving heartbeats from the leader which can lead to them starting new elections and forcing the current leader to step down. This is disruptive as the servers in the old configuration are not eligible to be elected and can continuously cause leadership to bounce prior to their complete removal.
In KRaft we follow a pull-based model instead - followers detect leader aliveness by follower-initiated fetch requests. If the leader does not respond within quorum.fetch.timeout.ms then the follower will start a new election. Rather than have the leader continue to respond to servers in the old configuration, KIP-595 proposes having the leader reject fetch requests from servers in old configurations and letting the servers know this way that they should shutdown now. We can either address this in KIP-853: KRaft Controller Membership Changes or in this KIP.
investigate this more, looks like we could use something like
BROKER_NOT_AVAILABLEerror code to signal to the follower they should shutdown
Servers in new configuration
What happens when a new node joins the quorum? If it were allowed to participate in elections without having fully replicated the leader’s log, could a node w/ a subset of the committed data be elected leader? Quorum reconfiguration only allows one addition/deletion at a time, and we are most vulnerable when the original configuration is small (3 node minimum). Given this, if a majority of the cluster is not caught up with the leader when we add a new node, we may lose data.
Ex: Majority is not caught up with leader prior to addition of new node, leading to data loss if a lagging follower receives a majority of votes
Time | Node 1 | Node 2 | Node 3 | Node 4 |
|---|---|---|---|---|
T0 | Leader | Lagging follower | Lagging follower | Added to quorum |
T1 | Leader → Unattached state | Follower → Unattached state | Follower → Unattached State | Starts an election before catching up on replication |
T2 | All nodes reject this node's vote request | |||
T3 | Election ms times out and this node starts an election | |||
T4 | Won’t vote for node 2 since node 2’s log is not as up-to-date as its own | Votes for itself | May vote for node 2 if node 2’s log is more up-to-date than theirs | Votes for node 2 |
If new nodes are sending pre-vote requests, we can easily reject them with no consequence (increase in epoch).
Disk Loss Scenario
This scenario share similarities with adding new nodes to the quorum. If a node loses its disk and fails to fully catch up to the leader prior to another node starting an election, it may vote for any node which is at least as caught up as itself (which might be less than the last leader).
Time | Node 1 | Node 2 | Node 3 |
|---|---|---|---|
T0 | Leader with majority of quorum (node 1, node 3) caught up with its committed data | Lagging follower | Follower |
T1 | Disk failure | ||
T2 | Leader → Unattached state | Follower → Unattached state | Comes back up w/ new disk, triggers an election before catching up on replication |
Will not be elected | |||
T4 | Election ms times out and starts an election | ||
T5 | Votes for Node 2 | Votes for Node 2 | |
T6 | Elected as leader leading to data loss |
Public Interfaces
Briefly list any new interfaces that will be introduced as part of this proposal or any existing interfaces that will be removed or changed. The purpose of this section is to concisely call out the public contract that will come along with this feature.
A public interface is any change to the following:
Binary log format
The network protocol and api behavior
Any class in the public packages under clientsConfiguration, especially client configuration
org/apache/kafka/common/serialization
org/apache/kafka/common
org/apache/kafka/common/errors
org/apache/kafka/clients/producer
org/apache/kafka/clients/consumer (eventually, once stable)
Monitoring
Command line tools and arguments
- Anything else that will likely break existing users in some way when they upgrade
Pre-Vote
Pre-vote is the idea of “canvasing” the cluster to check if it would receive a majority of votes - if yes it increases its epoch and sends a disruptive vote request. If not, it does not increase its epoch and does not send a vote request. The canvasing is done via a VoteRequest with a new field PreVote set to true. The candidate does not increase its epoch prior to sending the request out. The VoteResponse schema does not need any additional fields (still needs a version bump).
{
"apiKey": 52,
"type": "request",
"listeners": ["controller"],
"name": "VoteRequest",
"validVersions": "0-1",
"flexibleVersions": "0+",
"fields": [
{ "name": "ClusterId", "type": "string", "versions": "0+",
"nullableVersions": "0+", "default": "null"},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "CandidateEpoch", "type": "int32", "versions": "0+",
"about": "The bumped epoch of the candidate sending the request"},
{ "name": "CandidateId", "type": "int32", "versions": "0+", "entityType": "brokerId",
"about": "The ID of the voter sending the request"},
{ "name": "LastOffsetEpoch", "type": "int32", "versions": "0+",
"about": "The epoch of the last record written to the metadata log"},
{ "name": "LastOffset", "type": "int64", "versions": "0+",
"about": "The offset of the last record written to the metadata log"},
{ "name": "PreVote", "type": "boolean", "versions": "1+",
"about": "Whether the request is a PreVote request (no epoch increase) or not."}
]
...
}
How does this prevent unnecessary elections?
A node in an old configuration (and not in the new configuration) …
could be denied votes in the pre-vote phase based on the fact it is part of an old configuration. This can be handled by KIP-853. (todo: think through this more)
For a node w/ new disk/data loss …
could be denied votes in the pre-vote phase based on the fact it has a new disk. This would be handled by KIP-853.
When a partitioned node rejoins and forces the cluster to participate in an election …
all nodes reject the pre-vote request from the disruptive follower if its epoch is the same/older.
What becomes of the disruptive follower? The node continuously kicks off elections but is unable to be elected due to its stale epoch. It should rejoin the quorum when it discovers the higher epoch on the next valid election by another node (todo: check this for accuracy, there should be other ways for the node to become follower earlier).
Could this prevent necessary elections?
Yes, see “Check Quorum” for why we would need an additional safeguard
Do we still need to reject VoteRequests received within fetch timeout if we have implemented Pre-Vote?
Yes, except we would modify the logic to “Rejecting Pre-Vote requests received within fetch timeout”. We need to avoid bumping epochs without a new leader being elected else we may run into the issue where the node requesting the election(s) is now unable to rejoin the quorum because its epoch is greater than everyone else's despite not necessarily having as up-to-date a log. The following are two scenarios where just having Pre-Vote is not enough.
A node in an old configuration (e.g. S1 in the below diagram pg. 41) starts a “pre-vote” when the leader is temporarily unavailable, and is elected because it is as up-to-date as the majority of the quorum. The Raft paper argues we can not rely on the original leader replicating fast enough to get past this scenario, however unlikely that it is. We can imagine some bug/limitation with quorum reconfiguration causes S1 to continuously try to reconnect with the quorum (i.e. start elections) when the leader is trying to remove it from the quorum.
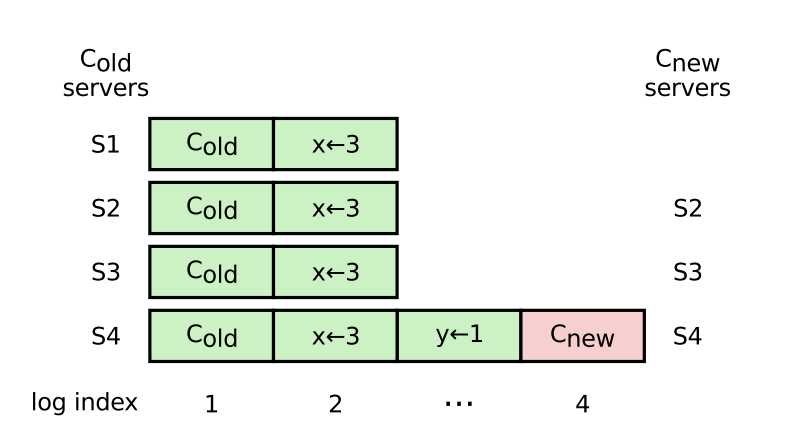
We can also imagine a non-reconfiguration scenario where two nodes, one of which is the leader, are simply unable to communicate with each other. Since the non-leader node is unable to find a leader, it will start an election and may get elected. Since the prior leader is now unable to find the new leader, it will start an election and may get elected. This could continue in a cycle.
Proposed Changes
Describe the new thing you want to do in appropriate detail. This may be fairly extensive and have large subsections of its own. Or it may be a few sentences. Use judgement based on the scope of the change.
Compatibility, Deprecation, and Migration Plan
- What impact (if any) will there be on existing users?
- If we are changing behavior how will we phase out the older behavior?
- If we need special migration tools, describe them here.
- When will we remove the existing behavior?
Test Plan
Describe in few sentences how the KIP will be tested. We are mostly interested in system tests (since unit-tests are specific to implementation details). How will we know that the implementation works as expected? How will we know nothing broke?
Rejected Alternatives
If there are alternative ways of accomplishing the same thing, what were they? The purpose of this section is to motivate why the design is the way it is and not some other way.