THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: Under Discussion
Discussion thread: here [Change the link from the KIP proposal email archive to your own email thread]
JIRA: here [Change the link from KAFKA-1 to your own ticket]
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
This KIP will go over scenarios where we might expect disruptive servers and discuss how Pre-Vote (as originally detailed in the Raft paper and in KIP-650) along with Followers rejecting Pre-Vote Requests can ensure correctness when it comes to network partitions (as well as quorum reconfiguration and failed disk scenarios).
Pre-Vote is the idea of “canvasing” the cluster to check if it would receive a majority of votes - if yes it increases its epoch and sends a disruptive vote request. If not, it does not increase its epoch and does not send a vote request.
Followers rejecting Pre-Vote Requests entails servers rejecting any pre-vote requests received prior to their own fetch timeout expiring. The idea here is if we've recently heard from a leader, we should not attempt to elect a new one just yet.
Throughout this KIP, we will differentiate between Pre-Vote and the original Vote request behavior with "Pre-Vote" and "standard Vote".
Disruptive server scenarios
When a follower becomes partitioned from the rest of the quorum, it will continuously increase its epoch to start elections until it is able to regain connection to the leader/rest of the quorum. When the server regains connectivity, it will disturb the rest of the quorum as they will be forced to participate in an unnecessary election. While this situation only results in one leader stepping down, as we start supporting larger quorums these events may occur more frequently per quorum.
For instance, here's a great example from https://decentralizedthoughts.github.io/2020-12-12-raft-liveness-full-omission/ which demonstrates a scenario where we could have flip-flopping leadership changes.
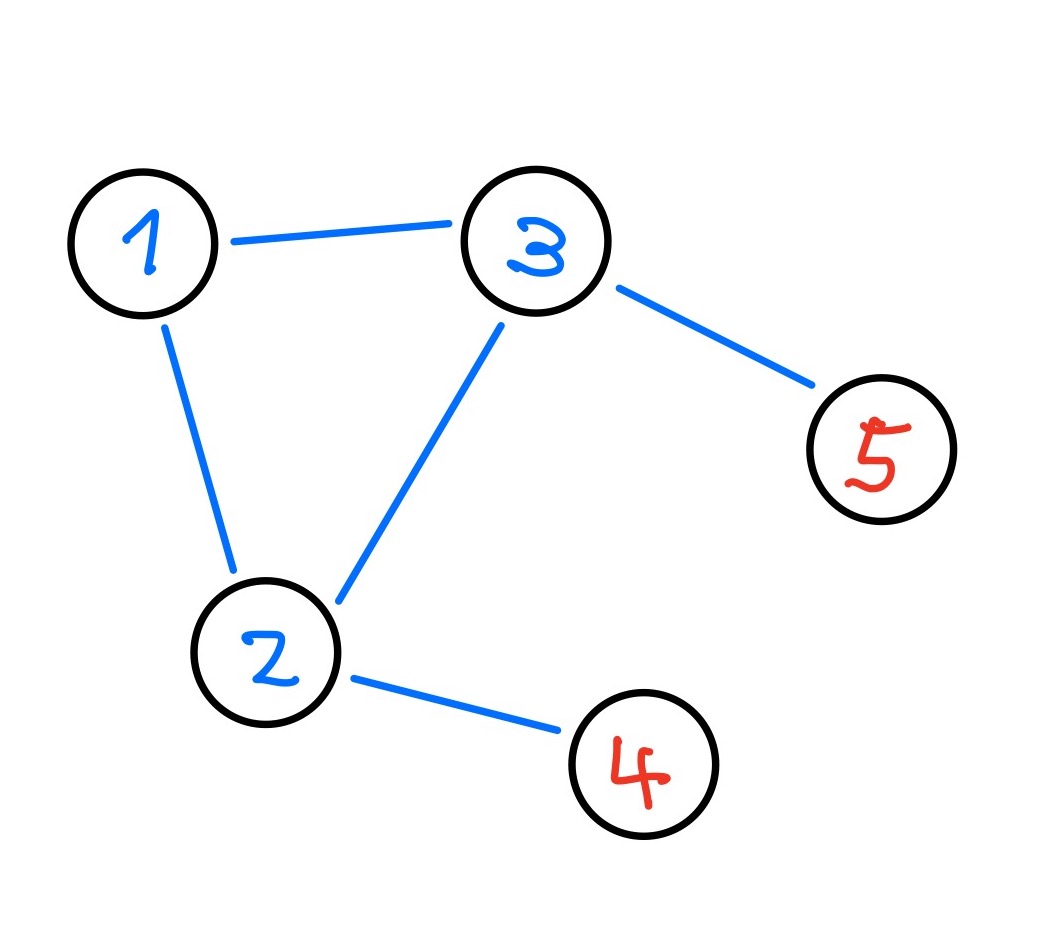
Let's say server 3 is the current leader. Server 4 will eventually start an election because it is unable to find the leader, causing Server 2 to transition to Unattached. Server 4 will not be able to receive enough votes to become leader, but Server 2 will be able to once its election timer expires. As Server 5 is also unable to communicate to Server 2, this kicks off a back and forth of leadership transition between Servers 2 and 3.
While network partitions may be the main issue we expect to encounter/mitigate impact for, it’s possible that bugs and user error create similar effects to network partitions that we need to guard against. For instance, a bug which causes fetch requests to periodically timeout or setting controller.quorum.fetch.timeout.ms and other related configs too low.
Public Interfaces
We will add a new field PreVote to VoteRequests and VoteResponses to signal whether the requests and responses are for Pre-Votes. The server does not increase its epoch prior to sending a Pre-Vote request, but will still report [epoch + 1]
{
"apiKey": 52,
"type": "request",
"listeners": ["controller"],
"name": "VoteRequest",
"validVersions": "0-1",
"flexibleVersions": "0+",
"fields": [
{ "name": "ClusterId", "type": "string", "versions": "0+",
"nullableVersions": "0+", "default": "null"},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "CandidateEpoch", "type": "int32", "versions": "0+",
"about": "The bumped epoch of the candidate sending the request"},
{ "name": "CandidateId", "type": "int32", "versions": "0+", "entityType": "brokerId",
"about": "The ID of the voter sending the request"},
{ "name": "LastOffsetEpoch", "type": "int32", "versions": "0+",
"about": "The epoch of the last record written to the metadata log"},
{ "name": "LastOffset", "type": "int64", "versions": "0+",
"about": "The offset of the last record written to the metadata log"},
{ "name": "PreVote", "type": "boolean", "versions": "1+",
"about": "Whether the request is a PreVote request (no epoch increase) or not."}
...
}{
"apiKey": 52,
"type": "response",
"name": "VoteResponse",
"validVersions": "0-1",
"flexibleVersions": "0+",
"fields": [
{ "name": "ErrorCode", "type": "int16", "versions": "0+",
"about": "The top level error code."},
{ "name": "Topics", "type": "[]TopicData",
"versions": "0+", "fields": [
{ "name": "TopicName", "type": "string", "versions": "0+", "entityType": "topicName",
"about": "The topic name." },
{ "name": "Partitions", "type": "[]PartitionData",
"versions": "0+", "fields": [
{ "name": "PartitionIndex", "type": "int32", "versions": "0+",
"about": "The partition index." },
{ "name": "ErrorCode", "type": "int16", "versions": "0+"},
{ "name": "LeaderId", "type": "int32", "versions": "0+", "entityType": "brokerId",
"about": "The ID of the current leader or -1 if the leader is unknown."},
{ "name": "LeaderEpoch", "type": "int32", "versions": "0+",
"about": "The latest known leader epoch"},
{ "name": "VoteGranted", "type": "bool", "versions": "0+",
"about": "True if the vote was granted and false otherwise"},
{ "name": "PreVote", "type": "boolean", "versions": "1+",
"about": "Whether the response is a PreVote response or not."}
...
}Proposed Changes
We add a new state Prospective for servers which are sending Pre-Vote requests as well as new state transitions. The original (left) and new states (right) are below for comparison.
* Unattached|Resigned transitions to:
* Unattached: After learning of a new election with a higher epoch
* Voted: After granting a vote to a candidate
* Candidate: After expiration of the election timeout
* Follower: After discovering a leader with an equal or larger epoch
*
* Voted transitions to:
* Unattached: After learning of a new election with a higher epoch
* Candidate: After expiration of the election timeout
*
* Candidate transitions to:
* Unattached: After learning of a new election with a higher epoch
* Candidate: After expiration of the election timeout
* Leader: After receiving a majority of votes
*
* Leader transitions to:
* Unattached: After learning of a new election with a higher epoch
* Resigned: When shutting down gracefully
*
* Follower transitions to:
* Unattached: After learning of a new election with a higher epoch
* Candidate: After expiration of the fetch timeout
* Follower: After discovering a leader with a larger epoch
* Unattached|Resigned transitions to:
* Unattached: After learning of a candidate with a higher epoch (clarifying language) * Voted: After granting a standard vote to a candidate (clarifying language) * Prospective: After expiration of the election timeout * Follower: After discovering a leader with an equal or larger epoch * * Voted transitions to:
* Unattached: After learning of a candidate with a higher epoch * Prospective: After expiration of the election timeout * Follower: After discovering a leader with an equal or larger epoch (missed in original docs)
* * Prospective transitions to:
* Unattached: After learning of a candidate with a higher epoch
* Candidate: After receiving a majority of pre-votes * Follower: After discovering a leader with an equal or larger epoch
* * Candidate transitions to:
* Unattached: After learning of a candidate with a higher epoch * Prospective: After expiration of the election timeout * Leader: After receiving a majority of standard votes * Follower: After discovering a leader with an equal or larger epoch (missed in original docs) * * Leader transitions to:
* Unattached: After learning of a candidate with a higher epoch
* * Follower transitions to:
* Unattached: After learning of a candidate with a higher epoch * Prospective: After expiration of the election timeout * Follower: After discovering a leader with a larger epoch
A candidate will now send a VoteRequest with the PreVote field set to true and CandidateEpoch set to its [epoch + 1] when its election timeout expires. If [majority - 1] of VoteResponse grant the vote, the candidate will then bump its epoch up and send a VoteRequest with PreVote set to false which is our standard vote that will cause state changes for servers receiving the request.
When servers receive VoteRequests with the PreVote field set to true, they will respond with VoteGranted set to
trueif the epoch and offsets in the Pre-Vote request satisfy the same conditions as a standard votefalseif otherwise
When a server receives VoteResponses, it will follow it up with another VoteRequest with PreVote set to either true (send another Pre-Vote) or false (send a standard vote)
false(standard vote) if the server has received [majority - 1] VoteResponses withVoteGrantedset totruewithin [election.timeout.ms + a little randomness]true(another Pre-Vote) if the server receives [majority] VoteResponse withVoteGrantedset tofalsewithin [election.timeout.ms + a little randomness]trueif the server receives less than [majority] VoteResponse withVoteGrantedset tofalsewithin [election.timeout.ms + a little randomness] and the first bullet point does not apply- Explanation for why we don't send a standard vote at this point is explained in rejected alternatives.
If a server happens to receive multiple VoteResponses from another server for a particular VoteRequest, it can take the first and ignore the rest. We could also choose to take the last, but taking the first is simpler. A server does not need to worry about persisting its election state for a Pre-Vote response like we currently do for VoteResponses because the direct result of the Pre-Vote phase does not elect leaders.
How does this prevent unnecessary leadership loss?
We prevent servers from increasing their epoch prior to establishing they can win an election.
Can this prevent necessary elections?
Yes. If a leader is unable to receive fetch responses from a majority of servers, it can impede followers that are able to communicate with it from voting in an eligible leader that can communicate with a majority of the cluster. This is the reason why an additional "Check Quorum" safeguard is needed which is what KAFKA-15489 implements. Check Quorum ensures a leader steps down if it is unable to receive fetch responses from a majority of servers.
Do we still need to reject VoteRequests received within fetch timeout if we have implemented Pre-Vote and Check Quorum?
Yes. Specifically we would be rejecting Pre-Vote requests received within fetch timeout. What this means in terms of state transitions is that Followers will not transition to Unattached when they learn of new elections with higher epochs. If they have heard from a leader within fetch timeout there is no need to consider electing a new leader.
The following are two scenarios which explain why Pre-Vote and Check Quorum are not enough to prevent disruptive servers. The second scenario is out of scope and should be covered by KIP-853: KRaft Controller Membership Changes or future work.
- Scenario A: We can image a scenario where two servers (S1 & S2) are both up-to-date on the log but unable to maintain a stable connection with each other. Let's say S1 is leader. S2 may be unable to find the leader, will start an election, and may get elected. Since S1 might be unable to find the new leader now, it will start an election and may get elected. This could continue in a cycle.
- Scenario B: A server in an old configuration (e.g. S1 in the below diagram pg. 41) starts a “pre-vote” when the leader is temporarily unavailable, and is elected because it is as up-to-date as the majority of the quorum. The Raft paper argues we can not rely on the original leader replicating fast enough to get past this scenario, however unlikely that it is. We can imagine some bug/limitation with quorum reconfiguration causes S1 to continuously try to reconnect with the quorum (i.e. start elections) when the leader is trying to remove it from the quorum.
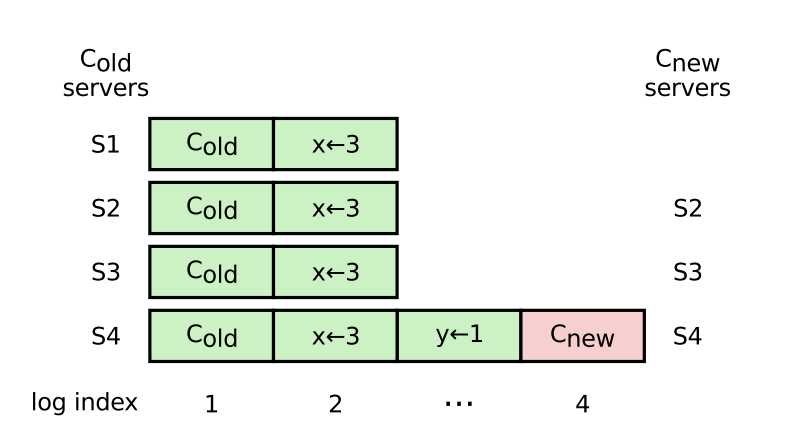
Rejecting Pre-Vote requests received within fetch timeout
As mentioned in the prior section, a server should reject Pre-Vote requests received from other servers if its own fetch timeout has not expired yet. The logic now looks like the following for servers receiving VoteRequests with PreVote set to true
When servers receive VoteRequests with the PreVote field set to true, they will respond with VoteGranted set to
trueif they haven't heard from a leader in fetch.timeout.ms and all conditions that normally need to be met for VoteRequests are satisfiedfalseif they have heard from a leader in fetch.timeout.ms (could help cover Scenario A & B from above) or conditions that normally need to be met for VoteRequests are not satisfied- (Not in scope) To address the disk loss and 'Servers in new configuration' scenario, one option would be to have servers respond
falseto vote requests from servers that have a new disk and haven't caught up on replication
Compatibility
We can gate Pre-Vote with a new VoteRequest and VoteResponse version. Instead of sending a Pre-Vote, a server will transition from Prospective immediately to Candidate if it knows of other servers which do not support Pre-Vote yet. This will result in the server sending standard votes which are understood by servers on older software versions.
Test Plan
This will be tested with unit tests, integration tests, system tests, and TLA+.
Rejected Alternatives
Rejecting VoteRequests received within fetch timeout (w/o Pre-Vote)
This was originally proposed in the Raft paper as a necessary safeguard to prevent Scenario A from occurring, but we can see how this could extend to cover all the other disruptive scenarios mentioned.
When a partitioned server rejoins and forces the cluster to participate in an election …
if a majority of the cluster is not receiving fetch responses from the current leader, they consider the vote request and make the appropriate state transitions. An election would be needed in this case anyways.
if the rest of the cluster is still receiving fetch responses from the current leader, they reject the vote request from the disruptive follower. No one transitions to a new state (e.g. Unattached) as a result of the vote request, current leader is not disrupted.
For a server in an old configuration (that’s not in the new configuration) …
if the current leader is still responding to fetch requests in a reasonable amount of time, the server is prevented from starting and winning elections, which would delay reconfiguration.
if the current leader is not responding to fetch requests, then the server could still win an election (this scenario calls for an election anyways). KIP-853 should cover preventing this case if necessary.
For a server w/ new disk/data loss …
if the current leader is still responding to fetch requests in a reasonable amount of time, the server is prevented from starting and winning elections, which could lead to loss of committed data.
if the current leader is not responding to fetch requests, we can reject VoteRequests from the server w/ new disk/data loss if it isn't sufficiently caught up on replication. KIP-853 should cover this case w/ storage ids if necessary.
However, this would not be a good standalone alternative to Pre-Vote because once a server starts a disruptive election (disruptive in the sense that the current leader still has majority), its epoch may increase while none of the other servers' epochs do. The most likely way for the server to rejoin the quorum now with its inflated epoch would be to win an election.
Separate RPC for Pre-Vote
This would be added toil with no real added benefits. Since a Pre-Vote and a standard Vote are similar in concept, it makes sense to cover both with the same RPC. We can add clear logging and metrics to easily differentiate between Pre-Vote and standard Vote requests.
Covering disk loss scenario in scope
This scenario shares similarities with adding new servers to the quorum, which KIP-853: KRaft Controller Membership Changes would handle. If a server loses its disk and fails to fully catch up to the leader prior to another server starting an election, it may vote for any server which is at least as caught up as itself (which might be less than the last leader). One way to handle this is to add logic preventing servers with new disks (determined via a unique storage id) from voting prior to sufficiently catching up on the log. Another way is to reject pre-vote requests from these servers. We leave this scenario to be covered by KIP-853 or future work because of the similarities with adding new servers.
Time | Server 1 | Server 2 | Server 3 |
|---|---|---|---|
T0 | Leader with majority of quorum (Server 1, Server 3) caught up with its committed data | Lagging follower | Follower |
T1 | Disk failure | ||
T2 | Leader → Unattached state | Follower → Unattached state | Comes back up w/ new disk, triggers an election before catching up on replication |
Will not be elected | |||
T4 | Election ms times out and starts an election | ||
T5 | Votes for Server 2 | Votes for Server 2 | |
T6 | Elected as leader leading to data loss |
Sending Standard Votes after failure to win Pre-Vote
When a server receives VoteResponses, it will follow it up with another VoteRequest with PreVote set to either true (send another Pre-Vote) or false (send a standard vote). If the server receives less than [majority] VoteResponse with VoteGranted set to false and has not received [majority - 1] VoteResponses with VoteGranted set to true within [election.timeout.ms + a little randomness], the server could send a standard vote at this point. An argument for doing this might be that it's safer to start sending non-Pre-Vote requests when we encounter unideal situations (e.g. unable to communicate with 1 server in a 3 server quorum) so we know we fallback to the original protocol. We can do this, but it should be safe for a server to continually send Pre-Vote requests if it does not receive a majority of VoteGranted responses - either the leader is able to communicate with the entire cluster or another server can start a Pre-Vote. If the cluster is truly partitioned and no server is able to communicate with a majority of the cluster, there is no point in servers sending out non-Pre-Vote requests anyways.