THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: Under Discussion
Discussion thread: here (<- link to https://mail-archives.apache.org/mod_mbox/flink-dev/)
JIRA:
Pull-request : https://github.com/apache/flink/pull/3511
Released: TBD
Please keep the discussion on the mailing list rather than commenting on the wiki (wiki discussions get unwieldy fast).
Motivation
In Flink 1.2.0, NormalizedKeySorter is used during sort-approach operations regardless of the type of sorting key and execution environment. As a result, in some situations, more efficient operations can be used instead of generic ones. One of examples is Unsafe.copyMemory that allows Flink to copy memory in any length, however, it checks memory alignment first before actually copying. Thus, it consumes unnecessary CPU cycles when copying data that we already know it always fit into memory segment, such situation is swapping 2 records during sorting. Here, we can leverage knowledge of sorting key from TypeComparator and generate custom fixed-byte operators to manipulate those records instead of using copyMemory. Based on the same knowledge, we can also unroll loop during key comparison as well as remove unnecessary branching if key can fully determined sort order.
Execution environment is also important. Because Flink serializes the key of a record to MemorySegment in big-endian format regardless endianness of the worker, when retrieving it back for comparison it need to reverse the bytes first. In this case, we compensate this at serialization process in which we will need to do byte-reversing only once for each record instead of every comparison. This means that the number of byte-reversing will become O(n) instead of O(n log n).
These optimizations are studied in FLINK-4867 and the results are promising.
Sorter \ No. records | 10,000 | 100,000 | 1,000,000 |
Original NormalizedKeySorter | 4.70 ms | 61.53 ms | 609.00 ms |
SwapViaPutGetLong | 3.34 ms | 49.88 ms | 471.30 ms |
UseLittleEndian | 4.20 ms | 56.15 ms | 578.14 ms |
CompareUnrollLoop | 4.29 ms | 53.59 ms | 605.32 ms |
Table 1 : Comparison between optimization ideas from FLINK-4867 and original NormalizedKeySorter
Another potential improvement could be eliminating expensive mathematical operators such as division and modulo, for example, when computing memory segment index. One proposed solution that trying to improvement this problem is Greg Hogan ’s FLINK-3722. Another possible ones could be using bitwise operators or replacing divisors with a constant that we know at compile-time [1]. From our experiment, we have found that Greg's solution is the best one, so we will base our implementation on his pull-request.
Sorter \ No. records | 10,000 | 100,000 | 1,000,000 |
Original NormalizedKeySorter | 4.34 ms | 61.79 ms | 582.88 ms |
Flink-3722 NormalizedKeySorter | 3.00 ms | 35.90 ms | 386.95 ms |
DividedByConstant | 3.49 ms | 45.14 ms | 436.22 ms |
UsingBitwiseOperators | 3.33 ms | 42.22 ms | 419.98 ms |
Table 2 : Comparison between 3 approaches of optimization for division and modulo
Because these optimization techniques depend on knowledge of each execution context, for example, data-type of sorting key and endianness of machine, we would need to apply applicable optimizations on the fly. In other words, we will dynamically generate the most efficient sorter for each context on each worker.
External Libraries
In this proposal, we plan to use 2 external libraries that are the same as FLINK-3599 : Code Generation in Serializers is using, namely
- Janino: A Java compiler that we will use to compile the generated code.
- FreeMarker : a Java template engine.
Public Interfaces
A configuration option for enabling / disabling code generation feature.
Proposed Changes
1. Code generation functionalities
We plan to abstract these functionalities from Flink code. We will create 3 new classes and 1 template file to accomplish that.
Class Diagram

SorterFactory : responsible for instantiating a sorter object. It is an interface between core flink and code generation processes.
Attributes
TemplateManager templateManager
Janino’s ClassLoader classLoader
HashMap<String, Constructor> generatedSorter
Methods
createSorter(ExecutionConfig config, TypeSerializer serializer, TypeCompartor comparator, ArrayList<MemorySegment> memory)
This method first checks whether If code generation configuration is enabled or not. If it is not, instantiate original NormalizedKeySorter. If the feature is enabled, the method checks whether there is a constructor of the corresponding source code already in the cache using templateModel.getGeneratedCodeFilename() as a key. If the constructor is not there yet, ask TemplateManager to instantiate the sorter and cache the constructor. Otherwise use the cached constructor to instantiate the sorter.
SorterTemplateModel : responsible for constructing suitable code String of each optimizing section in a template file. These Strings will be exposed via getTemplateVariables() to TemplateManager.
- Attributes
String templateName
TypeComparator typeComparator
ArrayList<Integer> fixedByteChunks
- Methods
generatedSequenceFixedByteChunks()
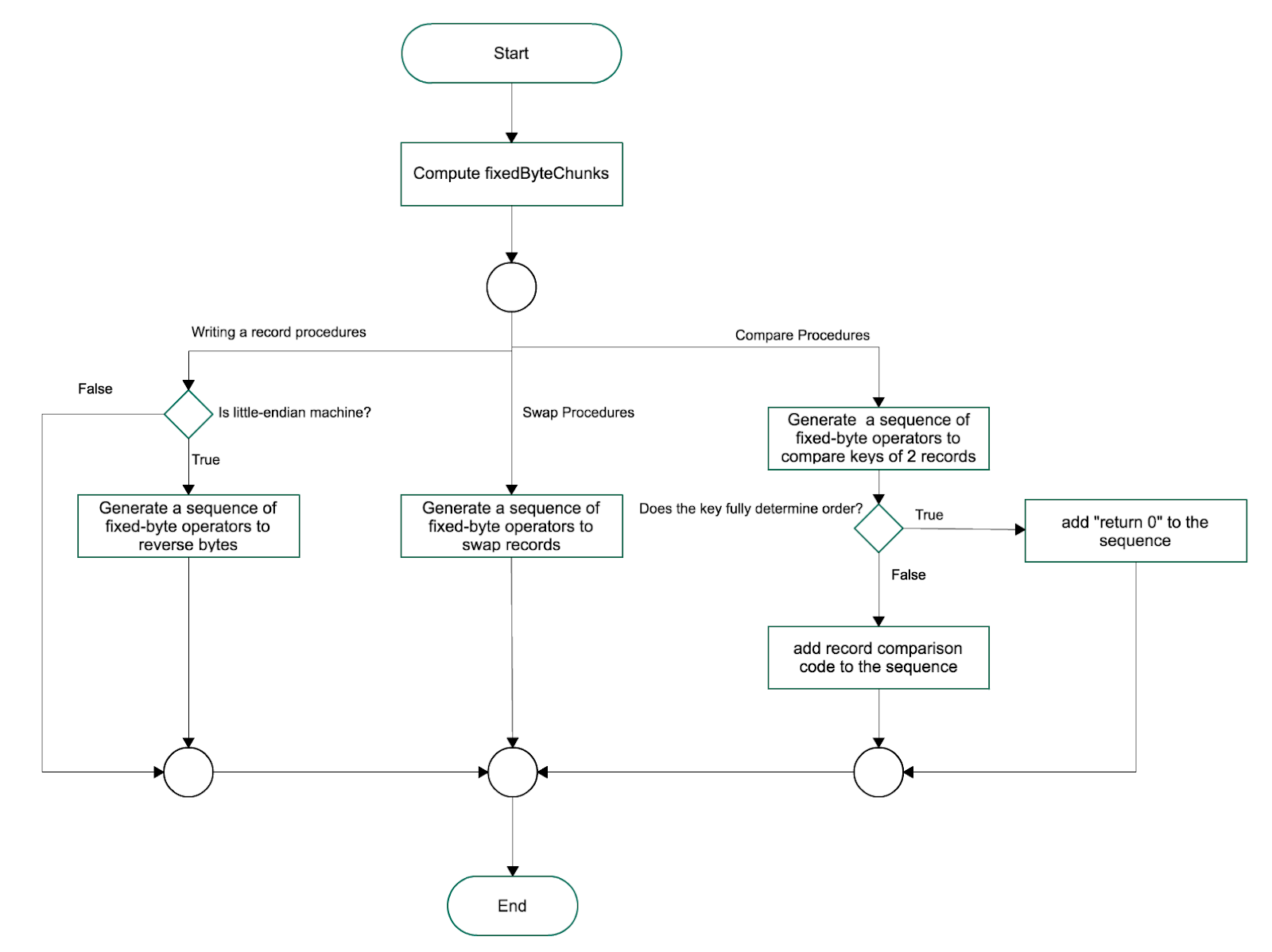
Based on number of bytes of the sorting key from typeComparator and record pointer(8 bytes), this method splits the bytes into fixed-byte chunks.
generateSwapProcedures()
Generate a sequence of MemorySegment’s fixed-byte operators to swap 2 records.
generateWriteProcedures()
Due to the fact that Flink serializes records into big-endian format, it needs to reverse bytes when retrieving 2 records to compare on little-endian machine. Hence, in this case, it is more efficient to move byte reversing to serialize process instead. In essence, this method generates a sequence of operators to reverse bytes after writing a record to a MemorySegment for little endian machine.
generateCompareProcedures()
Generate a sequence of MemorySegment’s fixed-byte operators to retrieve keys of 2 records for unsigned comparison. If the key is not fully determined order, add compare record operators to the sequence, otherwise just “return 0”.
getTemplateVariables()
This method returns HashMap of the generated sequences for each section in NormalizedKeySorter. This is consumed by TemplateManager.
getGeneratedCodeFilename()
This method determines name of the generated sorter based on chunk size and determinant of the key, for example LongIntFullyDeterminedKeySorter, or LongLongNonFullyDeterminedKeySorter. This is used by Janino to load the generated code as well as caching.
TemplateManager : responsible for generating source code file if it hasn’t been created yet.
- Attributes
- String templatePath
- String generatingPath ( based on Flink's temporary directory )
- HashMap<String, Boolean> generatedSorter
- Attributes
- Methods
- getGeneratedCode( SorterTemplateModel templateModel )
- Methods
Use templateModel.getTemplateVariables to render the corresponding blocks in “sorter.ftlh” template and store it at “taskmanager.temp.dirs”
sorter-template.ftlh : generic sorter template ( based on NormalizedKeySorter code )
Sequence Diagram of Code Generation

Code Generation Logics in SorterTemplateModel
2. Changes in existing Flink code
Classes that use NormalizedKeySorter will be updated at locations that they instantiate NormalizedKeySorter. As a result, code generation will be done on TaskManager. Therefore, instances of generated classes won’t need to be serialized and shipped across machines. Here is the list of classes that directly instantiate NormalizedKeySorter, and therefore will be directly affected by this improvement.
Compatibility, Deprecation, and Migration Plan
This change should not affect Flink’s functionalities, but It might have small impact on job startup time. More accurate result will be provided later. Also, we will introduce a configuration option that can be used to enable or disable this code generation feature.
Test Plan
We will test the correctness by creating several models and generating corresponding code and then verify whether the generated code sorts the data properly.
Rejected Alternatives
open for discussion.