THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: "Under Discussion"
Discussion thread: pending (link to https://mail-archives.apache.org/mod_mbox/flink-dev/)
JIRA: will be created once accepted
Released: Flink 1.4 or 1.5
Motivation
The default behavior of the streaming runtime is to copy every element between chained operators.
That operation was introduced for “safety” reasons, to avoid the number of cases where users can create incorrect programs by reusing mutable objects (a discouraged pattern, but possible). For example when using state backends that keep the state as objects on heap, reusing mutable objects can theoretically create cases where the same object is used in multiple state mappings.
The effect is that many people that try Flink get much lower performance than they could possibly get. From empirical evidence, almost all users that I (Stephan) have been in touch with eventually run into this issue eventually.
There are multiple observations about that design:
- Object copies are extremely costly. While some simple copy virtually for free (types reliably detected as immutable are not copied at all), many real pipelines use types like Avro, Thrift, JSON, etc, which are very expensive to copy.
- Keyed operations currently only occur after shuffles. The operations are hence the first in a pipeline and will never have a reused object anyways. That means for the most critical operation, this precaution is unnecessary.
- The mode is inconsistent with the contract of the
DataSetAPI, which does not copy at each step - To prevent these copies, users can select
enableObjectReuse(), which is misleading, since it does not really reuse mutable objects, but avoids additional copies.
Public Interfaces
Interfaces changed
The interface of the ExecutionConfig add the method setObjectReuseMode(ObjectReuseMode), and deprecates the methods enableObjectReuse() and disableObjectReuse().
Behavior changed
The default object passing behavior changes, meaning that it can affect the correctness of prior DataStream programs that assume the original “COPY_PER_OPERATOR” behavior (see below).
Proposed Changes
Summary
I propose to change the default behavior of the DataStream runtime to be the same as the DataSet runtime. That means that new objects are chosen on every deserialization, and no copies are made as the objects are passed on along the pipelines.
Details
I propose to drop the execution config flag objectReuse and instead introduce an ObjectReuseMode enumeration with better control of what should happen. There will be three different types:
DEFAULT
This is the default in the
DataSetAPIThis will become the default in the
DataStreamAPIThis happens in the
DataStreamAPI whenenableObjectReuse()is activated.
COPY_PER_OPERATOR
The current default in the
DataStreamAPI
FULL_REUSE
This happens in the DataSet API when {{enableObjectReuse()}} is chosen.
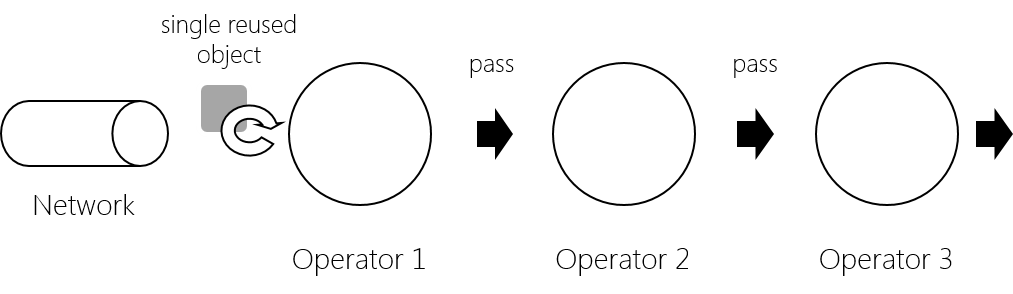
An illustration of the modes is as follows:
DEFAULT
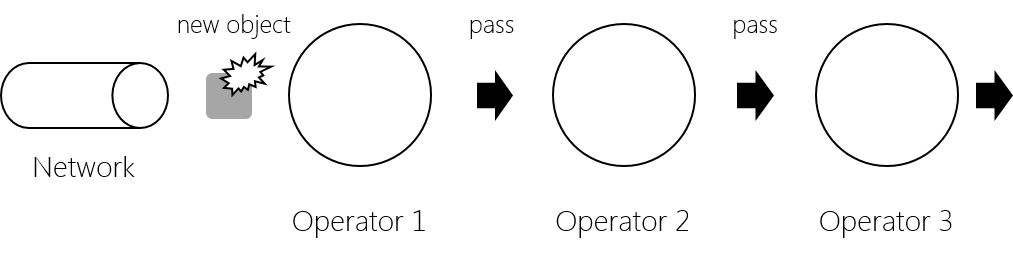
COPY_PER_OPERATOR

FULL_REUSE
Compatibility, Deprecation, and Migration Plan
Interfaces
No interface migration path is needed, because the interfaces are not broken, merely some methods get deprecated.
Behavior change
We have two
Variant 1:
Change the behavior, make it explicit on the release notes that we did that and what cases are affected,
This may actually be feasible, because the cases that are affected are quite pathological corner cases that only very bad implementations should encounter (see below)
Variant 2:
When users set the mode, always that mode is used.
When the mode is not explicitly set, we follow that strategy:
Change the CLI such that we know when users upgrade existing jobs (the savepoint to start from has a version prior to 1.4).
Use DEFAULT as the default for jobs that do not start from savepoint, or that start from savepoint >= 1.4
Use COPY_PER_OPERATOR as the default for upgraded jobs
Rejected Alternatives
None so far...