THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: [ UNDER DISCUSSION | ACCEPTED | REJECTED ]
Discussion thread: <link to mailing list DISCUSS thread>
JIRA: SAMZA-TBD
Released:
Problem
Samza framework enables its users to build stateful stream processing applications–that is, applications that remember information about past events in a local state(store), which will be then used to influence the processing of future events from the stream. Local state is a fundamental and enabling concept in stream processing which is required and essential to support a majority of common use cases such as stream-stream join, stream-table join, windowing etc.
Every stream application in samza has many task instances which contains a custom user-defined function for processing events from a stream. Each task instance will have one to many associated local stores. Local store of a task instance is backed up by an log compacted kafka topic referred to as change-log. When a task instance commits, incremental local task store updates are flushed to the kafka topic. When a task instance runs on a host that doesn’t have latest local store, it’s restored by replaying messages from the change-log stream. For large stateful jobs, this restoration phase takes longer time, thus preventing the application from starting up and processing events from the input streams. Host affinity is a feature that maintains stickiness between a task and physical host and offers best-effort guarantees that a task instance will be assigned to run on the same physical it had ran before. This document discusses some potential approaches to support this feature in standalone deployment model.
Requirements:
Goals
- Support stateful stream processing in standalone stream applications.
- Minimize partition movements amongst stateless processors in the rebalance phase.
Non Goals
- In the embedded samza library model, users are expected to perform manual garbage collection of unused local state stores(to reduce the disk footprint) on nodes.
Proposed Changes
Overall idea intent behind this approach is to encapsulate the host aware task assignment to processors logic as a part of JobModel generation(specifically as a part of TaskNameGrouper implementation) in standalone. With existing host affinity implementation in samza-yarn, this happens outside of the JobModel generation(specifically in a ContainerAllocator implementation). The trouble with replicating this outside of JobModel generation in standalone(in the leader layer) is that, it creates an abstraction boundary spill over to the higher level layer which shouldn’t concern itself with intricacies/details of the task assignment to stream processors.
If an optimal assignment for each task to a particular processor is generated in the JobModel as part of the leader in a stateful processors group, each follower will just pick up their assignments from job model after the rebalance phase and start processing(similar to non-stateful jobs). The goal is to guarantee that the optimal assignment happens which minimizes the task movement between the processors. Local state of the tasks will be persisted in a directory(local.store.dir) provided through configuration by each processor.
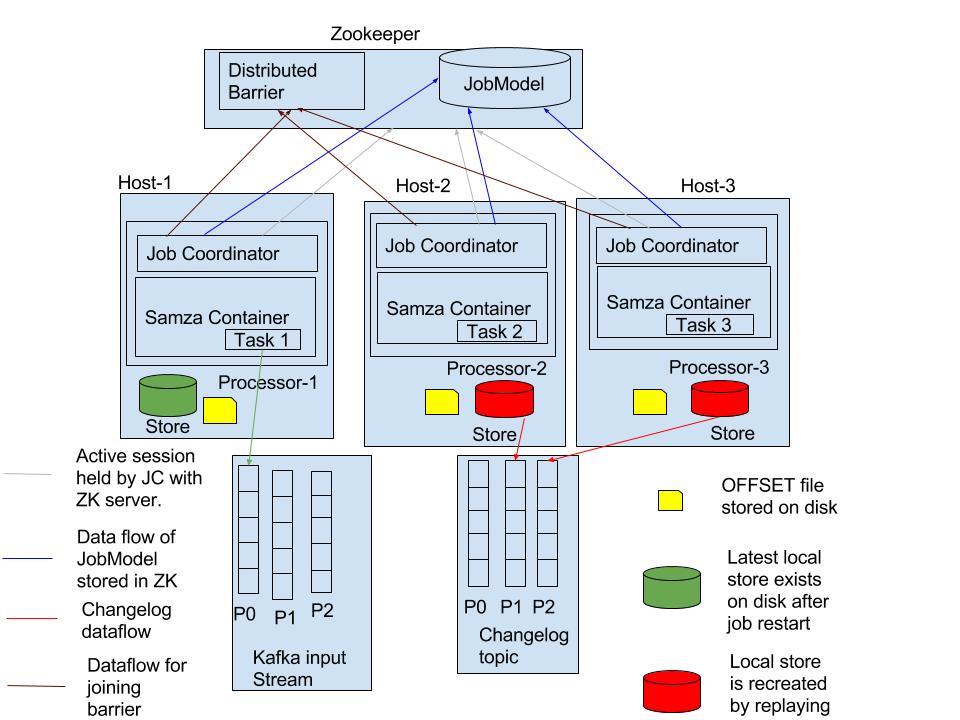
ZK Data Model to support host affinity:
- zkBaseRootPath/$appName-$appId-$JobName-$JobId-$stageId/
- processors/
- processor.000001/
- physicalHost1
- processor.000002/
- physicalHost2
...
- processor.00000N/
- physicalHostN
- jobModelVersion/
- {$Generation.$Version}
- JobModel
- JobConfiguration
- ContainerModel-1
- processorId: 0
- hostName: physicalHostName-1
- TaskModel-1
- taskName: TaskId-1
- SystemStreamPartitions: [InputStream1:P1, InputStream1:P2]
- changeLogPartitionId: 0
- TaskModel-2
- taskName: TaskId-2
- systemStreamPartitions: [InputStream1:P3, InputStream1:P4]
- ChangeLogPartitionId: 1
- ContainerModel-2
- processorId: 1
- hostName: physicalHostName-2
- TaskModel-3
- taskName: TaskId-3
- SystemStreamPartitions: [InputStream1:P5, InputStream1:P6]
- ChangeLogPartitionId: 2
- TaskModel-4
- taskName: TaskId-4
- SystemStreamPartitions: [InputStream1:P7, InputStream1:P8]
- ChangeLogPartitionId: 3
In standalone landscape, the file system location to persist the local state should be provided by the users through stream processor configuration(by defining local.store.dir configuration). It’s expected that the stream processor java process will be configured by user to run with sufficient read/write permissions to access the local state directories created by any processor in the group. Users should manage the garbage collection of unused and stale local state’s created by the stream processors.
The following directory structure will be used to store the local state of the stream processors in the host machine with an objective to achieve store isolation between multiple stream processors running on the same machine.
When low level StreamTask/AsyncStreamTask API is used:
- {local.store.dir}
- {jobId-jobName-1}
- {taskName-1}
- store-1
- OFFSET
- 1.sst
- {jobId-jobName-2}
- {taskName-2}
- store-2
- OFFSET
- 1.sst
When high level fluent API is used:
- {local.store.dir}
- {appId-appName-1}
- {taskName-1}
- {operatorId-1}
- store1
- OFFSET
- 1.sst
- {taskName-2}
- {operatorId-2}
- store2
- OFFSET
- 1.sst
In order to make local store data highly available, all writes to the local store are replicated to a durable changelog(kafka topic) which serves the purpose of replication log. Each local store has an associated OFFSET file which represents the local state store lag behind the changelog(source of truth). When a samza task commits or samza container shuts down, pending local store changes are flushed to change log stream and latest changelog offset is persisted to OFFSET file on disk.
Upon processor restart, if the local state associated with the task is not available on the disk, it will be restored following the existing restoration logic followed in yarn deployment model. The following represents the state store restoration sequence which occurs upon Stream processor restart:
Opens the persisted store on disk.
Reads the OFFSET file.
Restores the state store from the OFFSET value.
When assigning tasks to a stream processor in a run, the stream processor to which the task was assigned in the previous run will be preferred. If the stream processor to which task was assigned in previous run is unavailable in the current run, the stream processors running on physical host of previous run will be given higher priority and favored. If both of the above two conditions are not met, then the task will be assigned to any stream processor available in the processor group.
2. Remove coordinator stream bindings from JobModel
JobModel is a data access object used to represent a samza job in both yarn and standalone deployment models. With existing implementation, JobModel requires LocalityManager(which is tied to coordinator stream) to read and populate processor locality assignments. However, since zookeeper is used as JobModel persistence layer and coordinator stream doesn’t exist in standalone landscape, it’s essential to remove this LocalityManager binding from JobModel and make JobModel immutable. It will be ideal to store task to preferred host assignment as a part of job model due to the following reasons:
Task to locality assignment information logically belongs to the JobModel itself and it makes things simpler by persisting them together.
If task to preferred host assignment and JobModel are stored separately in zookeeper in standalone, we’ll run into consistency problems between these two data sinks when performing JobModel upgrades. We’ll also lose the capability to do atomic updates of entire JobModel in zookeeper.
Any existing implementations(ClusterBasedJobCoordinator, ContainerProcessManager) which depends upon this binding for functional correctness in samza-yarn, should directly read container locality from the coordinator stream instead of getting it indirectly via JobModel.
3. Clean up ContainerModel:
ContainerModel is a data access object used in samza for holding the task to system stream partition assignments which is generated by TaskNameGrouper implementations. ContainerModel currently has two fields(processorId and containerID) used to uniquely identify a processor in a processors group. Standalone deployment model uses processorId and Yarn deployment model uses containerId field to store the unique processorId. To achieve uniformity between the two deployment models, the proposal is to remove duplicate containerId. This will not require any operational migration.
Public Interfaces
Existing interface:
public interface TaskNameGrouper {
Set<ContainerModel> group(Set<TaskModel> tasks);
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containersIds) {
return group(tasks);
}
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
public class ContainerModel {
@Deprecated
private final int containerId;
private final String processorId;
private final Map<TaskName, TaskModel> tasks;
Proposed changes:
public interface TaskNameGrouper {
@deprecated
Set<ContainerModel> group(Set<TaskModel> tasks);
@deprecated
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containersIds) {
return group(tasks);
}
Set<ContainerModel> group(Set<TaskModel> currentGenerationTaskModels, List<String> currentGenerationContainerIds, Set<ContainerModel> previousGenerationContainerModels);
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
@deprecated
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
public class ContainerModel {
// ContainerId field is deleted.
private final String processorId;
private final Map<TaskName, TaskModel> tasks;
// New field added denoting the physical hostname.
private final String hostName;
Implementation and Test Plan
Modify the existing interfaces and classes as per the proposed solution.
Add unit tests to test and validate compatibility and functional correctness.
Add a integration test in samza standalone samples to verify the host affinity feature.
Verify compatibility - Jackson, a java serialization/deserialization library is used to convert data model objects in samza into JSON and back. After removing containerId field from ContainerModel, it should be verified that deserialization of old ContainerModel data with new ContainerModel spec works.
Some TaskNameGrouper implementations assumes the comparability of integer containerId present in ContainerModel(for instance - GroupByContainerCount, a TaskNameGrouper implementation). Modify existing TaskNameGrouper implementations to take in collection of string processorId’s, as opposed to assuming that containerId is integer and lies within [0, N-1] interval(without incurring any change in functionality).
Rejected Alternatives
Approach 1
This contains all the changes mentioned in proposed solution with a differing interface changes as listed below.
Existing interfaces:
public interface TaskNameGrouper {
Set<ContainerModel> group(Set<TaskModel> tasks);
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containerIds) {
return group(tasks);
}
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
Proposed changes:
public interface TaskNameGrouper {
@deprecated
Set<ContainerModel> group(Set<TaskModel> tasks);
@deprecated
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containerIds) {
return group(tasks);
}
Set<ContainerModel> group(Set<TaskModel> taskModels, List<String> containerIds, LocalityManager localityManager);
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
@deprecated
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
LocalityManager will be turned to an interface and there will be two implementations of LocalityManager viz CoordinatorStreamBasedLocalityManager to read/write container locality information for yarn and ZkLocalityManager to read/write container locality information for standalone.
Cons:
Would require boilerplate LocalityManager implementations for every new execution environment integration with standalone. For instance, azure integration would require building AzureTableLocalityManager and wiring it into TaskNameGrouper. Ideally a TaskNameGrouper implementation should not be aware about the underlying storage layer used to persist JobModel.
Any TaskNameGrouper implementation could hold references to LocalityManager(a live object) and create object hierarchies based upon that reference. This will clutter the ownership of LocalityManager and could potentially create an unintentional resource leak.
Approach 2
GroupByContainerIds is the only TaskNameGrouper currently supported in standalone. Implement the host aware task to stream processors assignment for standalone in GroupByContainerIds.
Pros:
Straightforward and easy to implement.
Cons:
Ideally any grouper should be usable in both yarn and standalone deployment model. If we proceed with this approach, custom groupers cannot be supported in standalone. This limits the extensibility available in yarn in standalone and loses enormous value proposition in standalone.
Approach 3
Do not change any existing interfaces and pass the previous generation ContainerModel, TaskModels to TaskNameGrouper implementations through the config object and document it in the interface contract.
Cons:
Even though this approach works, it suffers from all problems mentioned in approach 2. Ideally a configuration object should only contain topology and processor related configurations(should be a collection of simple key-value pairs) and should not be used to accommodate and propagate an entire heavy-weight JobModel object.