THIS IS A TEST INSTANCE. ALL YOUR CHANGES WILL BE LOST!!!!
Status
Current state: UNDER DISCUSSION
Discussion thread: <link to mailing list DISCUSS thread>
JIRA:
Released:
Problem
Samza framework enables its users to build stateful stream processing applications–that is, applications that remember information about past events in a local state(store), which will be then used to influence the processing of future events from the stream. Local state is a fundamental and enabling concept in stream processing which is required and essential to support a majority of common use cases such as stream-stream join, stream-table join, windowing etc.
Every stream application in samza has many task instances which contains a custom user-defined function for processing events from a stream. Each task instance will have one to many associated local stores. Local store of a task instance is backed up by an log compacted kafka topic referred to as change-log. When a task instance commits, incremental local task store updates are flushed to the kafka topic. When a task instance runs on a host that doesn’t have latest local store, it’s restored by replaying messages from the change-log stream. For large stateful jobs, this restoration phase takes longer time, thus preventing the application from starting up and processing events from the input streams. Host affinity is a feature that maintains stickiness between a task and physical host and offers best-effort guarantees that a task instance will be assigned to run on the same physical it had ran before. This document discusses some potential approaches to support this feature in standalone deployment model.
Requirements
Goals
- Support stateful stream processing in standalone stream applications.
- Minimize partition movements amongst stateful processors in the rebalance phase.
Non Goals
- In the embedded samza library model, users are expected to perform manual garbage collection of unused local state stores(to reduce the disk footprint) on nodes.
Proposed Changes
Overall idea intent behind this approach is to encapsulate the host aware task assignment to processors logic as a part of JobModel generation(specifically as a part of TaskNameGrouper implementation) in standalone. With existing host affinity implementation in samza-yarn, this happens outside of the JobModel generation(specifically in a ContainerAllocator implementation). The trouble with replicating this outside of JobModel generation in standalone(in the leader layer) is that, it creates an abstraction boundary spill over to the higher level layer which shouldn’t concern itself with intricacies/details of the task assignment to stream processors.
If an optimal assignment for each task to a particular processor is generated in the JobModel as part of the leader in a stateful processors group, each follower will just pick up their assignments from job model after the rebalance phase and start processing(similar to non-stateful jobs). The goal is to guarantee that the optimal assignment happens which minimizes the task movement between the processors. Local state of the tasks will be persisted in a directory(local.store.dir) provided through configuration by each processor.
High level flow in standalone with HostAffinity
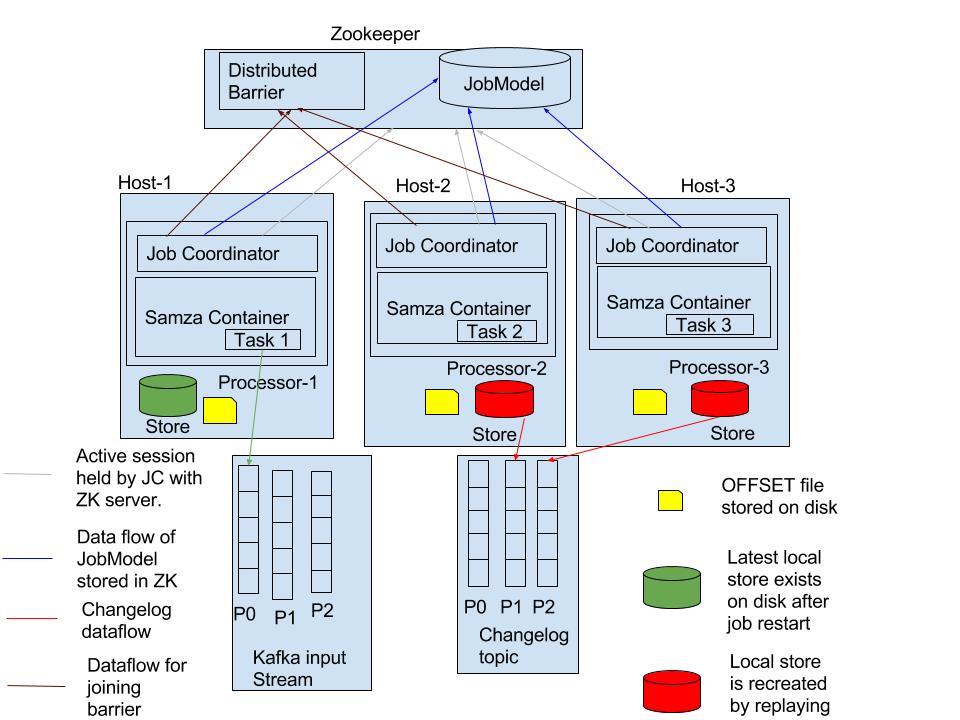


ZK Data Model to support host affinity:
After the rebalancing phase, before the start of processing each stream processor will register the details of physical host on which it runs in the localityData zookeeper node. The goal here is to separate the locality information from the JobModel itself (JobModel will be used to hold the task assignments). LocalityManager abstraction will be used to read and write locality information for different deployment models in appropriate storage layers. There will be two implementations of LocalityManager viz CoordinatorStreamBasedLocalityManager to read/write container locality information for yarn and ZkLocalityManager to read/write container locality information for standalone. In case of standalone, last known physical host in which each samza task had run will be stored in zookeeper, which will then be used to assign tasks to stream processors. Stream processor will update the task locality of the tasks assigned to it before it begins processing(This is synonymous to behaviour in yarn, where locality is updated in SamzaContainer as a part of startup sequence).
- zkBaseRootPath/$appName-$appId-$JobName-$JobId-$stageId/
- processors/
- processor.000001/
- processor.000002/
...
- processor.00000N/
- jobModels/
- {jobModelVersion}
JobModelObject
- localityData
- task01/
- locationId
- task02/
- locationId
...
- task0N/
- locationId
Local store sandboxing:
In standalone landscape, the file system location to persist the local state should be provided by the users through stream processor configuration(by defining local.store.dir configuration). The configuration `local.store.dir` is expected to be preserved across processor restarts to reuse preexisting local state. It’s expected that the stream processor java process will be configured by user to run with sufficient read/write permissions to access the local state directories created by any processor in the group. The local store file hierarchy/organization followed in samza-yarn deployment model for both high and low level API will be followed in standalone.
Remove coordinator stream bindings from JobModel:
JobModel is a data access object used to represent a samza job in both yarn and standalone deployment models. With existing implementation, JobModel requires LocalityManager(which is tied to coordinator stream) to read and populate processor locality assignments. However, since zookeeper is used as JobModel persistence layer and coordinator stream doesn’t exist in standalone landscape, it’s essential to remove this LocalityManager binding from JobModel and make JobModel immutable. Any existing implementations(ClusterBasedJobCoordinator, ContainerProcessManager) which depends upon this binding for functional correctness in samza-yarn, should directly read container locality from the coordinator stream instead of getting it indirectly via JobModel.
Cleaning up ContainerModel:
ContainerModel is a data access object used in samza for holding the task to system stream partition assignments which is generated by TaskNameGrouper implementations. ContainerModel currently has two fields(processorId and containerID) used to uniquely identify a processor in a processors group. Standalone deployment model uses processorId and Yarn deployment model uses containerId field to store the unique processorId. To achieve uniformity between the two deployment models, the proposal is to remove duplicate containerId. This will not require any operational migration.
State store restoration:
Upon processor restart, nonexistent local stores will be restored using the same restoration sequence followed in yarn deployment model.
Container to physical host assignment:
When assigning tasks to a stream processor in a run, the stream processor to which the task was assigned in the previous run will be preferred. If the stream processor to which task was assigned in previous run is unavailable in the current run, the stream processors running on physical host of previous run will be given higher priority and favored. If both of the above two conditions are not met, then the task will be assigned to any stream processor available in the processor group.
Semantics of host affinity with ‘run.id’
When a samza user stops all the stream processors of a samza application and starts them again(in any order), it is considered as a new samza application run. Samza supports deployment and management of multi-stage data pipeline jobs consuming form bounded(batch) as well as unbounded(streaming) data sources. Host affinity will be supported by default in all streaming scenarios and within a same run in batching(bounded data source) scenarios. Host affinity will not supported across multiple runs when a samza job consumes only from bounded data sources(batching scenarios in beam-runner).
Public Interfaces
// '+' denotes addition, '-' denotes deletion.
public interface TaskNameGrouper {
+ @deprecated
Set<ContainerModel> group(Set<TaskModel> tasks);
+ @deprecated
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containersIds) {
return group(tasks);
}
+ Set<ContainerModel> group(Set<TaskModel> currentGenerationTaskModels, List<String> currentGenerationProcessorIds, Set<ContainerModel> previousGenerationContainerModels);
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
+ @deprecated
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
public class ContainerModel {
- @Deprecated
- private final int containerId;
private final String processorId;
private final Map<TaskName, TaskModel> tasks;
+ // New field added denoting the physical locationId.
+ private final String locationId;
}
+public interface LocationIdProvider {
LocationId getLocationId();
}
+ public class LocalityInfo {
+ // In case of containerized environments, LocationId is a combination of multiple fields (sliceId, containerId, hostname) instead of simple physical hostname,
+ // Using a class to represent that, rather than a primitive string. This will be provided by execution environment.
+ private Map<String, LocationId> taskLocality;
+ public Map<String, LocationId> getLocality();
}
+ public interface LocalityManager {
// returns processorId to host mapping.
+ public LocalityInfo readProcessorLocality();
// writes the provided processordId to host mapping to underlying storage.
+ public boolean writeProcessorLocality(LocalityInfo localityInfo);
}
Here are few reasons supporting the modification of TaskNameGrouper interface and removing LocalityManager from interface methods:
Any TaskNameGrouper implementation should be usable in both yarn and standalone deployment models. However, TaskNameGrouper interface definition has an explicit and tight binding with CoordinatorStream through LocalityManager and existing TaskNameGrouper implementations employs LocalityManager to read/write locality mapping from and to Coordinator stream. Coordinator stream doesn’t exist in standalone landscape and this prohibits usage of some TaskNameGrouper implementations in standalone.
Multiple group methods in TaskNameGrouper interface and additional balance method in BalancingTaskNameGrouper are logically synonymous to each other and exists to generate ContainerModels based upon the input task models and past locality assignments. It’s sensible to combine them into one interface method with adequate parameters and simplify things.
Any future TaskNameGrouper implementation could hold references to LocalityManager(a live object) and create object hierarchies based upon that reference. This will clutter the ownership of LocalityManager and could potentially create an unintentional resource leak.
Number of processors is a static configuration in yarn deployment model and a job restart is required to change the number of processors. However, an addition/deletion of a processor to a processors group in standalone is quite common and an expected behavior. Existing generators discard the task to physical host assignment when generating the JobModel. However, for standalone it’s essential to consider this detail(task to physical host assignment) between successive job model generations to accomplish optimal task to processor assignment. For instance, let’s assume stream processors P1, P2 runs on host H1 and processor P3 runs on host H3. If P1 dies, it is optimal to assign some of the tasks processed by P1 to P2. If previous task to physical host assignment is not taken into account when generating JobModel, this cannot be achieved.
Logically, a TaskNameGrouper implementation would just require the previous generation container models(to get previous task to preferred host mapping, previous task to systemstreampartition mapping) which can be passed in through the interface method to generate new mapping. Any modifications to existing assignments should be done outside of TaskNameGrouper implementation. This will make any implementation as a pure function simply operating on the passed in data.
After this change, we will have one method in TaskNameGrouper interface clearly defining the contract and all other methods in TaskNameGrouper will be deprecated(eventually removed). Host aware task to stream processors assignment in standalone will be housed in a TaskNameGrouper implementation which will be used to support this feature.
Implementation and Test Plan
Modify the existing interfaces and classes as per the proposed solution.
Add unit tests to test and validate compatibility and functional correctness.
Add a integration test in samza standalone samples to verify the host affinity feature.
Verify compatibility - Jackson, a java serialization/deserialization library is used to convert data model objects in samza into JSON and back. After removing containerId field from ContainerModel, it should be verified that deserialization of old ContainerModel data with new ContainerModel spec works.
Some TaskNameGrouper implementations assumes the comparability of integer containerId present in ContainerModel(for instance - GroupByContainerCount, a TaskNameGrouper implementation). Modify existing TaskNameGrouper implementations to take in collection of string processorId’s, as opposed to assuming that containerId is integer and lies within [0, N-1] interval(without incurring any change in functionality).
Compatibility, Deprecation, and Migration Plan
- In upcoming release, LocalityManager class will be changed into an interface. Any code which depends on LocalityManager class directly in open source should migrate to CoordinatorStreamBasedLocalityManager.
- We are not changing the existing data storage format of the ContainerModel in coordinator stream for yarn deployment model.
- ContainerId field in ContainerModel which is deprecated in samza 0.13 version will be removed in the future release. Open source users using containerId field from ContainerModel should migrate and use processorID field in ContainerModel.
- All of the existing methods in TaskNameGrouper and BalancingTaskNameGrouper will be deprecated.
- It’s recommended that the users recompile their deployable after migrating to the samza version that has this feature.
- Will add compatibility test to verify that deprecating/changing the TaskNameGrouper API changes does not alter the existing behaviors.
Rejected Alternatives
Approach 1
This contains all the changes mentioned in proposed solution with a differing interface changes as listed below.
// '+' denotes addition, '-' denotes deletion.
public interface TaskNameGrouper {
+ @deprecated
Set<ContainerModel> group(Set<TaskModel> tasks);
+ @deprecated
default Set<ContainerModel> group(Set<TaskModel> tasks, List<String> containerIds) {
return group(tasks);
}
+ Set<ContainerModel> group(Set<TaskModel> taskModels, List<String> containerIds, LocalityManager localityManager);
}
public interface BalancingTaskNameGrouper extends TaskNameGrouper {
+ @deprecated
Set<ContainerModel> balance(Set<TaskModel> tasks, LocalityManager localityManager);
}
LocalityManager will be turned to an interface and there will be two implementations of LocalityManager viz CoordinatorStreamBasedLocalityManager to read/write container locality information for yarn and ZkLocalityManager to read/write container locality information for standalone.
Cons:
Would require boilerplate LocalityManager implementations for every new execution environment integration with standalone. For instance, azure integration would require building AzureTableLocalityManager and wiring it into TaskNameGrouper. Ideally a TaskNameGrouper implementation should not be aware about the underlying storage layer used to persist JobModel.
Any TaskNameGrouper implementation could hold references to LocalityManager(a live object) and create object hierarchies based upon that reference. This will clutter the ownership of LocalityManager and could potentially create an unintentional resource leak.
Approach 2
GroupByContainerIds is the only TaskNameGrouper currently supported in standalone. Implement the host aware task to stream processors assignment for standalone in GroupByContainerIds.
Pros:
Straightforward and easy to implement.
Cons:
Ideally any grouper should be usable in both yarn and standalone deployment model. If we proceed with this approach, custom groupers cannot be supported in standalone. This limits the extensibility available in yarn in standalone and loses enormous value proposition in standalone.
Approach 3
Do not change any existing interfaces and pass the previous generation ContainerModel, TaskModels to TaskNameGrouper implementations through the config object and document it in the interface contract.
Cons:
Even though this approach works, it suffers from all problems mentioned in approach 2. Ideally a configuration object should only contain topology and processor related configurations(should be a collection of simple key-value pairs) and should not be used to accommodate and propagate an entire heavy-weight JobModel object.